Как сделать слайд-шоу с помощью OpenCV

Мы сделали слайд-шоу для большинства наших презентаций в колледже / офисе, чтобы они отлично смотрелись при презентации с использованием Microsoft PowerPoint, давайте рассмотрим это как действие по обработке изображений и посмотрим, как мы можем получить утилиту слайд-шоу с помощью библиотеки OpenCV Python в этой статье.
Cоздание с нуля простой ORM на Python

ORM (Object Relational Mapper) является инструментом, который позволяет взаимодействовать с вашей базой данных с помощью объектно-ориентированной парадигмы. Поэтому ORM обычно реализуются в виде библиотек на языках, поддерживающих объектно-ориентированное программирование.
Кластеризация траектории GPS с помощью Python
Быстрый рост мобильных устройств привел к появлению огромного количества траекторий GPS, собранных службами на основе определения местоположения, геосоциальными сетями, транспортом или приложениями для совместного использования.
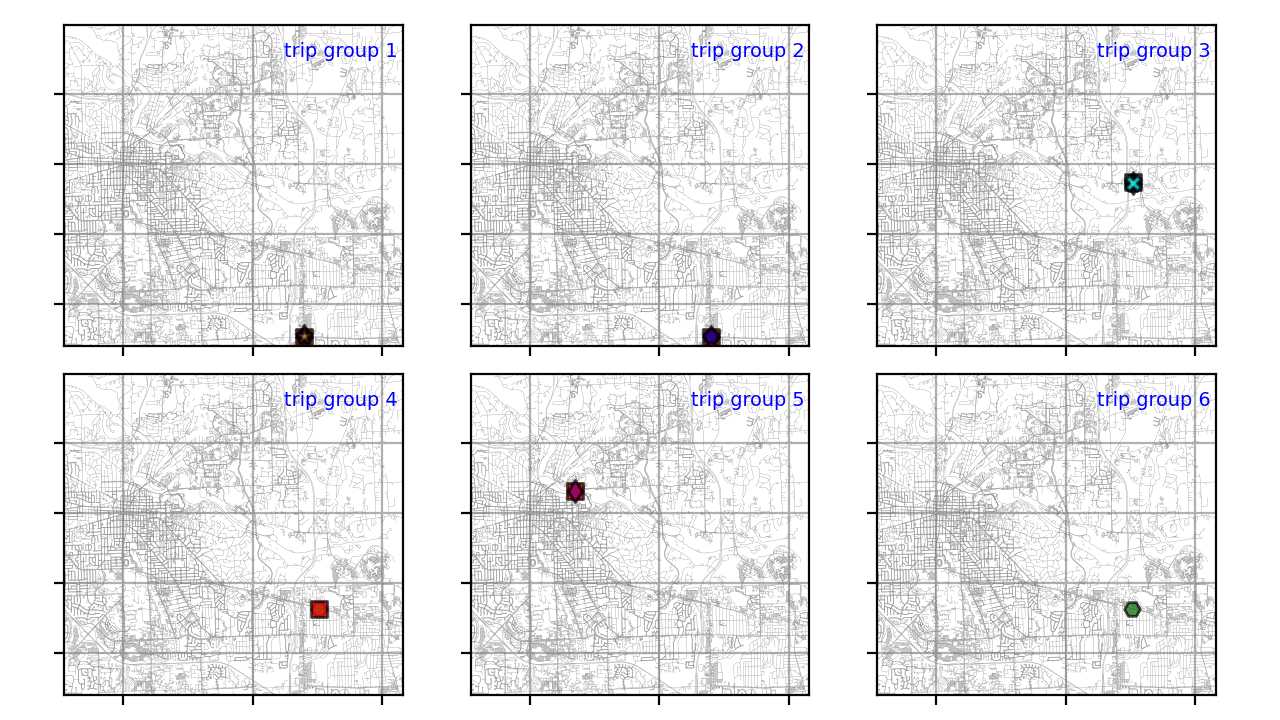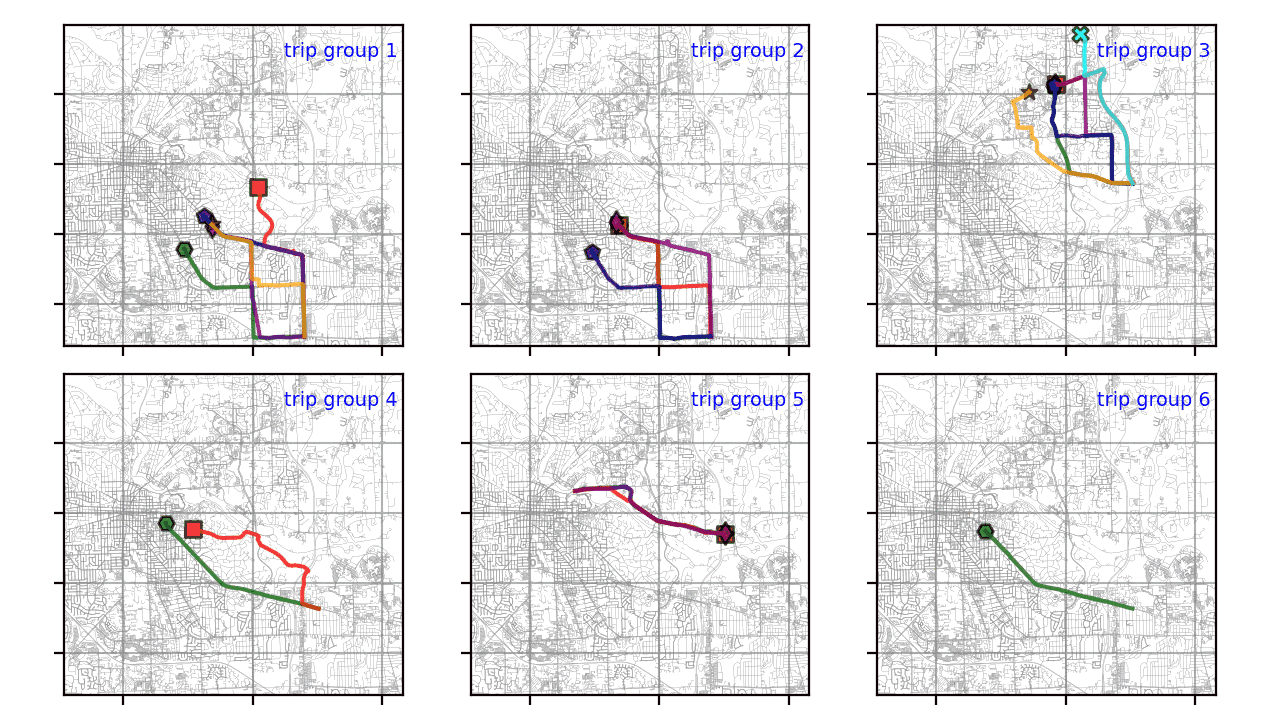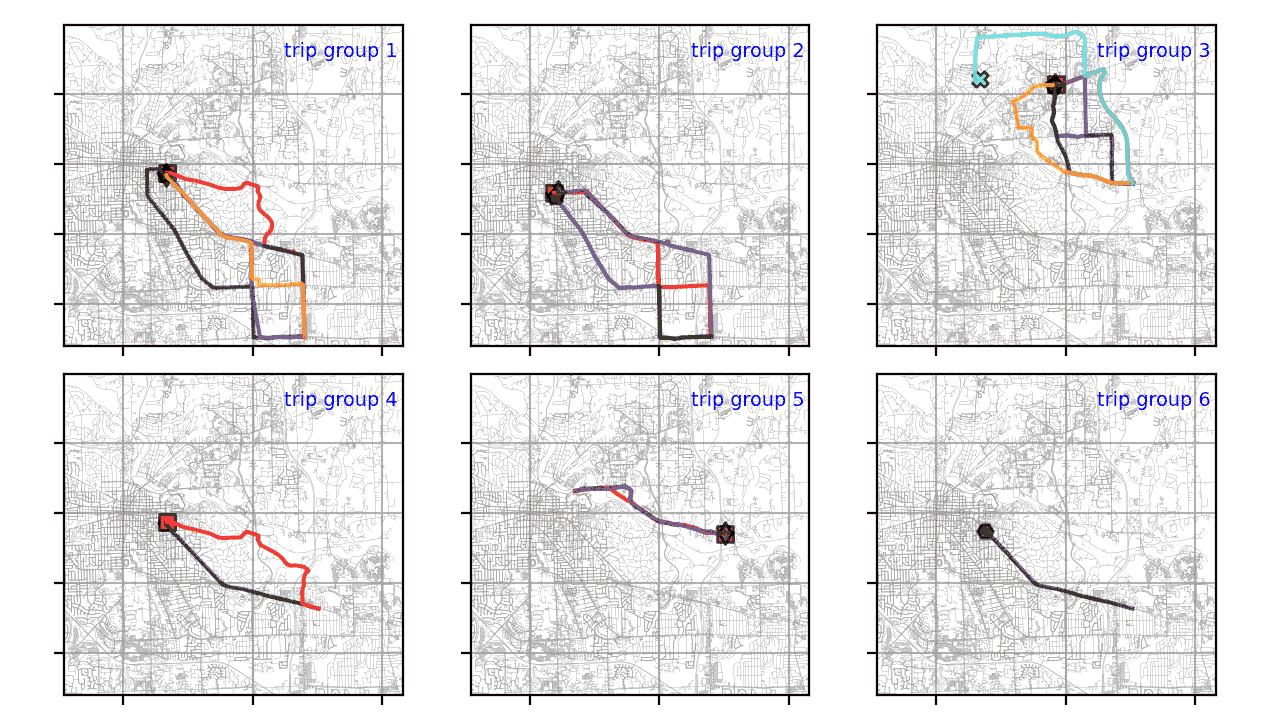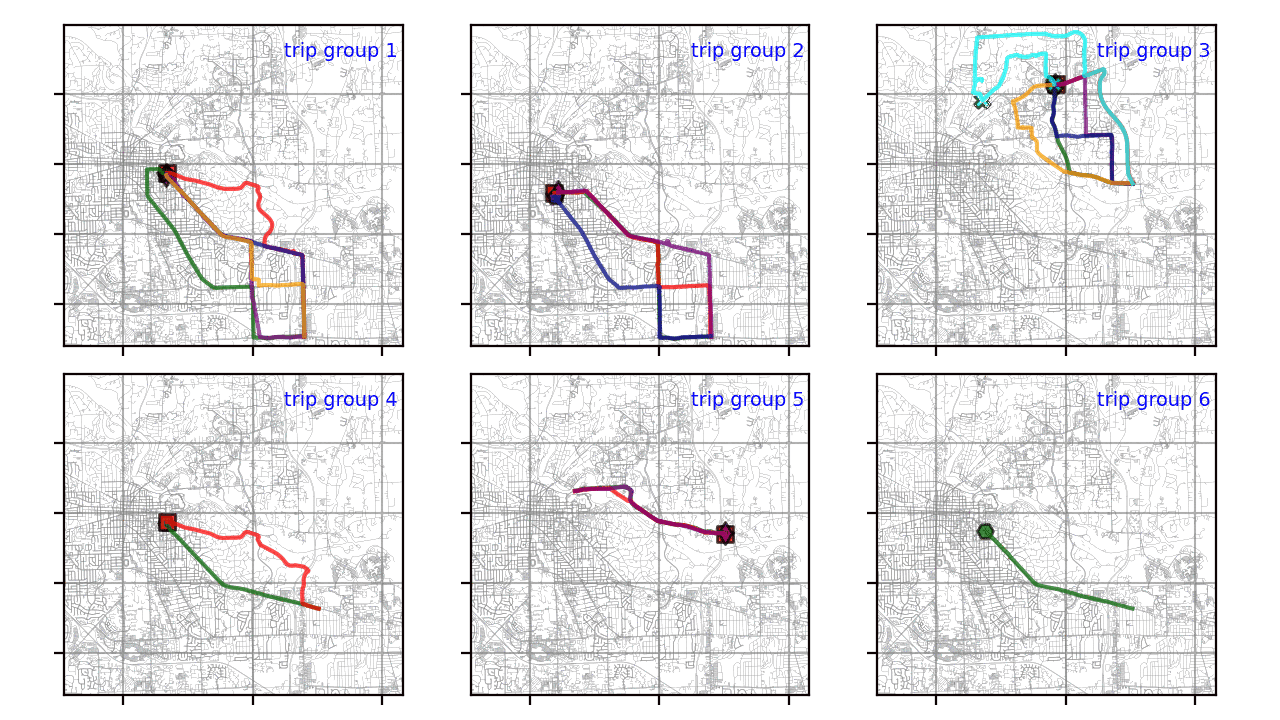
Как записать данные из Google Sheets в вашу базу данных с помощью Python

Представьте себе: вы находитесь в процессе сбора источников данных для создания нового отчета и понимаете, что некоторые наборы данных все еще обновляются вручную вашими заинтересованными сторонами и хранятся в таблицах Google… звучит знакомо?
В этом случае у вас есть два варианта: либо вы запустите ускоренный курс, чтобы научить своих менее технических коллег работе с SQL и хранилищами данных, либо вы сами автоматизируете процесс с помощью Python.
В этом руководстве вы узнаете, как извлекать наборы данных из электронной таблицы Google с помощью Python, подключившись к API Google Диска, а затем сохранить их в таблице базы данных с помощью пакета SQLAlchemy.
Тепловая карта с использованием Python
В Data Science тепловая карта используется для понимания взаимосвязи между различными функциями в наборе данных. Она представляет числа в форме цветной палитры, так что более темные оттенки представляют высокую степень взаимосвязи между элементами, а более светлые оттенки представляют собой низкую степень взаимосвязи между элементами. Теперь давайте посмотрим, как визуализировать тепловую карту с помощью Python.
Самый быстрый способ форматирования строк в Python
Есть 3 способа форматирования строк в Python
- Использование оператора
% - Использование
format() - Использование
fстрок

Введение в Apache Hudi с PySpark

Чтобы преодолеть проблему удаления одной строки из системы больших данных, на рынке доступно множество решений, например, от транзакционных свойств Hive до функций Delta блоков данных. Сегодня мы узнаем об Apache Hudi и сделаем несколько практических шагов по удалению записей из наборов данных.
Связанные списки в Python

Связанный список - это линейная структура данных, элементы которой не хранятся в непрерывном месте. Это означает, что связанный список содержит отдельные вакуоли, известные как «узлы», которые содержат данные, для которых они были созданы, и ссылку на другой узел в списке.
Сжатие изображения - метод DCT
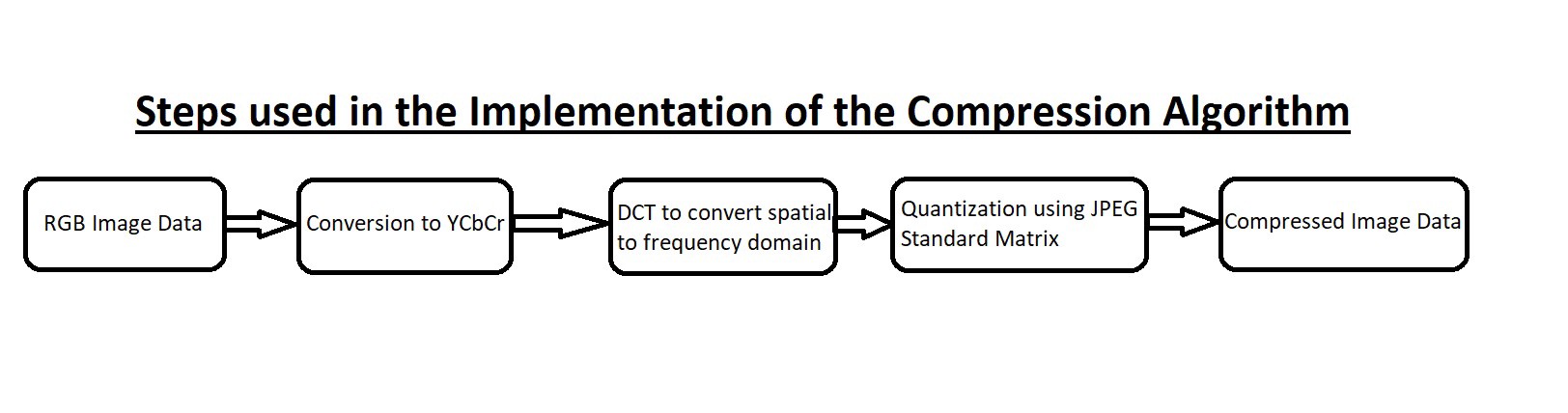
Мы видим, что в последние годы наблюдается экспоненциальный рост вычислительных ресурсов и данных. Хотя и вычислительные ресурсы, и объем данных растут, темпы роста этих же показателей резко отличаются. Теперь у нас очень большие объемы данных и недостаточно вычислительных ресурсов для их обработки в приличное количество времени. Это подводит нас к одной из основных проблем, с которыми мир сталкивается сейчас. Как мы можем сжимать информацию о данных, сохраняя при этом большую часть информации, содержащейся в данных?
В этом проекте мы будем иметь дело с информацией об изображении. К изображениям применяются два основных типа сжатия - сжатие без потерь и сжатие с потерями. Некоторыми примерами стандартов сжатия без потерь являются PNG (переносимая сетевая графика) и PCX (обмен изображениями). При сжатии без потерь вся информация сохраняется, но степень сжатия низкая. Если нам нужно более высокое сжатие, мы должны рассмотреть алгоритмы сжатия с потерями. Одним из широко используемых алгоритмов сжатия с потерями является алгоритм сжатия JPEG. Алгоритм JPEG работает на DCT, что является темой обсуждения в этом проекте.
DCT расшифровывается как Discrete Cosine Transform. Это тип быстрого вычисления преобразования Фурье, который отображает реальные сигналы в соответствующие значения в частотной области. DCT работает только с реальной частью сложного сигнала, потому что большинство реальных сигналов являются реальными сигналами без сложных компонентов. Здесь мы обсудим реализацию алгоритма DCT для данных изображения и его потенциальное использование. Проект размещен на GitHub, и вы можете просмотреть его здесь.
Почему вам действительно нужно обновить pip

Новые выпуски программного обеспечения могут содержать исправления ошибок, новые функции и более высокую производительность. Например, в NumPy 1.20 добавлены аннотации типов и улучшена производительность за счет использования SIMD, когда это возможно. Если вы устанавливаете NumPy, возможно, вы захотите установить самую новую версию.
К сожалению, если вы используете старую версию pip, установка последней версии пакета Python может завершиться ошибкой или установиться более медленным и более сложным способом.
Почему? Комбинация управления версиями glibc, графика окончания срока службы CentOS и способов установки pip пакетов.
Давайте посмотрим, в чем именно заключается проблема, как ее решить и, наконец, если вам достаточно интересно, что ее вызывает.
Python - высокоуровневый язык программирования созданный Гвидо ван Россумом еще в 1980 году. Мощный, одновременно поддерживающий несколько парадигм программирования, на сегодняшний день используется во многих сферах деятельности, от программирования микроконтроллеров и до создания сложных микросервисных веб приложений.
Присоединяйся в тусовку
Поделитесь своим опытом, расскажите о новом инструменте, библиотеке или фреймворке. Для этого не обязательно становится постоянным автором.