Анализ кибербезопасности - Руководство для начинающих по обработке журналов безопасности в Python
Сегодняшний взаимосвязанный мир делает нас более уязвимыми для кибератак: вездесущие устройства Интернета вещей записывают и слушают то, что мы делаем, спам и фишинговые электронные письма угрожают нам каждый день, а атаки на сети, которые воруют данные, могут привести к серьезным последствиям. Эти системы создают терабайты журналов, полных информации, которая может помочь обнаружить и защитить уязвимые системы. По консервативным оценкам, компания среднего размера с сотнями и тысячами взаимосвязанных устройств может создавать до 100 ГБ файлов журналов в день. Кроме того, частота регистрируемых событий может достигать уровней, исчисляемых десятками тысяч в секунду.
CLX (выраженные клики) является частью экосистемы RAPIDS, которая ускоряет обработку и анализ киберлогов. Как часть RAPIDS, он построен на основе RAPIDS DataFrames cuDF и дополнительно расширяет возможности библиотеки RAPIDS ML cuML, используя последние достижения в области обработки естественного языка для организации неструктурированных данных и построения моделей классификации.
Кибербезопасность
С появлением персональных компьютеров состязательные игры перешли от чисто разведывательных миссий и традиционной войны к вмешательству в компьютерные системы противника. Такие организации, как Агентство национальной безопасности (АНБ), полны ученых разного профиля, которые ежедневно пытаются обеспечить безопасность наших национальных сетей, чтобы злоумышленник не мог получить доступ к электросети или нашей банковской системе. На этом уровне ставки чрезвычайно высоки, как и защитные механизмы для предотвращения таких атак.
Персональные компьютеры или бизнес-сети - это другая мера: хотя атака на отдельный компьютер или сеть не может нанести вред или иным образом угрожать благополучию граждан, она может иметь серьезные последствия для финансов и / или будущих возможностей одного человека или компании.
Многие из этих атак оставляют после себя след, цепочку информации, которая может помочь бизнесу обнаружить атаку и защитить себя от нее. В конце концов, любая атака, которая ставит под угрозу способность компании вести бизнес в обычном режиме, приводит к потере производительности. Что еще хуже, если злоумышленник получит доступ к интеллектуальной собственности и похитит ее, он может нанести вред или полностью разрушить такой бизнес.
Однако как может бизнес, который генерирует более 100 ГБ лог-файлов в день, справиться со всем этим потоком данных?
cyBERT
Исторически подход заключался в анализе лог-файлов с помощью Regex. И хотя мы большие поклонники Regex как такового, такой подход становится непрактичным, если бизнесу необходимо поддерживать тысячи различных шаблонов для каждого отдельного типа журнала, который собирает такая компания. И вот здесь все начинается: для обнаружения атак в нашей сети нам нужны данные, а для получения данных нам нужно анализировать лог-файлы. Без данных мы не сможем обучить никакую модель машинного обучения. Другого пути нет.
Модель BERT (или двунаправленное представление кодировщика от трансформаторов) - это глубокая нейронная сеть, представленная Google для лучшего понимания естественного языка. В отличие от предыдущих подходов к решению проблем в области NLP, которые основывались на повторяющихся сетевых архитектурах (например, LSTM - Long Short-Term Memory), модель BERT представляет собой сеть с прямой связью, которая изучает контекст слова путем сканирования предложения в обоих направлениях. Таким образом, BERT будет производить другое вложение (или числовое представление) для одинаково звучащих предложений, таких как «Она смотрит телевизор» и «Она наблюдает, как растут ее дети».
В контексте журналов кибербезопасности такое внедрение может быть полезно для различения IP-адресов, конечных точек сети, портов или комментариев или сообщений свободного потока. Фактически, используя вложения BERT, можно обучить модель обнаружению таких сущностей. Введите cyBERT!
cyBERT - это автоматический инструмент для анализа лог-файлов и извлечения соответствующей информации. Для начала нам просто нужно загрузить модель, которую мы собираемся использовать:
cybert = Cybert()
cybert.load_model(
'pytorch_model.bin'
, 'config.json'
)
pytorch_model.bin модель PyTorch, обученная распознавать сущности из лог-файлов Apache WebServer; её можно скачать из models.huggingface.co/bert/raykallen/cybert_apache_parser S3 bucket. В этом же S3 bucket мы можем найти файл config.json.
После загрузки модели CyBERT будет использовать возможности графических процессоров NVIDIA для быстрого анализа журналов, извлечения полезной информации и создания структурированного представления информации журнала. API делает это действительно просто.
logs_df = cudf.read_csv(‘apache_log.csv')
parsed_df, confidence_df = cybert.inference(logs_df["raw"])
Первый возвращенный фрейм данных содержит все проанализированные поля из журналов.
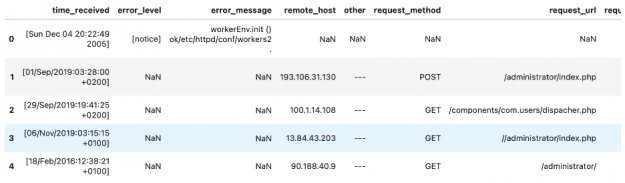
В то время как DataFrame confidence_df показывает, насколько модель CyBERT уверена в каждом извлеченном фрагменте информации.
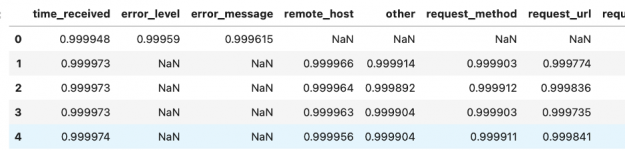
Как видите, модель довольно уверенная, и взгляд на данные подтверждает, что извлеченная информация соответствует имени столбца.