Яндекс представил новую версию машинного перевода

Большая языковая модель YandexGPT была использована для создания эталонных текстов, на которых обучили нейросеть в Яндекс Переводчике, сообщили в пресс-службе Яндекса.
Это улучшило понимание контекста, распознавание фразеологизмов и владение профессиональной лексикой сервисом. Теперь он лучше переводит длинные и сложные тексты, а также точнее определяет взаимосвязи в предложениях и между ними. Качество перевода статей узконаправленной тематики также выросло, например, сервис теперь умеет распознавать контекст и оставлять названия языков программирования или фондовых индексов без перевода.
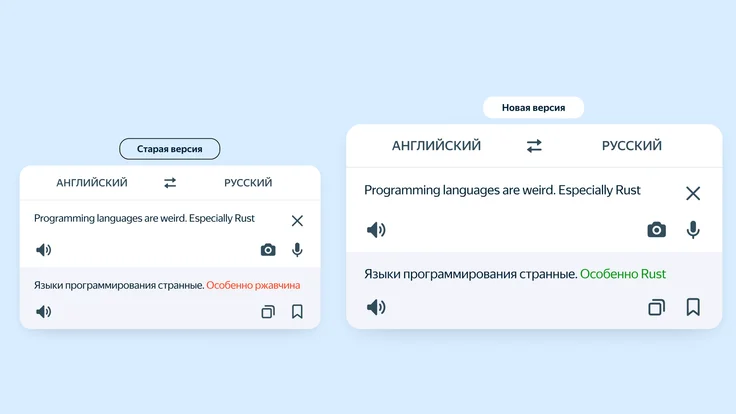
Например, сервис теперь поймёт по контексту, что речь идёт о языке программирования или фондовом индексе, и оставит их названия без перевода.
Обновленная технология используется для перевода текстов с английского на русский язык в различных продуктах Яндекса, включая Переводчик, Поиск и перевод видео в Браузере.
Большая языковая модель YandexGPT способна генерировать сложные, лексически и стилистически разнообразные тексты, в том числе со специфической терминологией. Поэтому компания использовала её потенциал для создания эталонных примеров, чтобы расширить датасет и повысить его качество. Так нейросеть в Переводчике не утратила скорость своей работы, но стала умнее.
Сначала модель во время этапа pretraining проанализировала множество текстов на английском и русском языках и изучила правила лексики, морфологии и синтаксиса. Следующим этапом шла тонкая настройка языковой модели (supervised finetuning) под задачи перевода. Затем на этапе reinforcement learning AI-тренеры оценивали качество перевода YandexGPT и ранжировали её ответы от лучших к худшим.
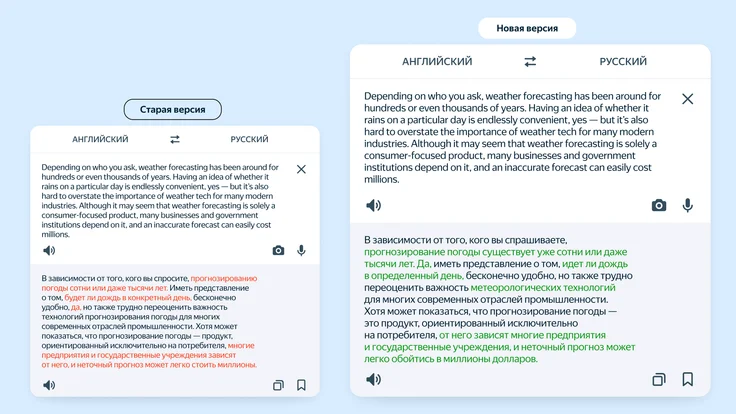
Асессоры, владеющие русским и английским языками, оценивали работу дообученной нейросети в Переводчике методом Side by Side (SbS), где в 57% случаев новая версия справлялась лучше.