Как работает JavaScript: под капотом движка V8
Сегодня мы заглянем под капот движка JavaScript V8 и выясним, как именно выполняется JavaScript.
Задний план
Веб-стандарты - это набор правил, которые реализует браузер. Они определяют и описывают аспекты Всемирной паутины.
W3C - это международное сообщество, которое разрабатывает открытые стандарты для Интернета. Они следят за тем, чтобы все следовали одним и тем же принципам и не поддерживали десятки совершенно разных сред.
Современный браузер - это довольно сложная программа с кодовой базой, состоящей из десятков миллионов строк кода. Таким образом, он разделен на множество модулей, отвечающих за разную логику.
Двумя наиболее важными частями браузера являются движок JavaScript и движок рендеринга.
Blink - это движок рендеринга, который отвечает за весь конвейер рендеринга, включая деревья DOM, стили, события и интеграцию V8. Он анализирует дерево DOM, определяет стили и определяет визуальную геометрию всех элементов.
Непрерывно отслеживая динамические изменения с помощью кадров анимации, Blink раскрашивает контент на вашем экране. Движок JS - большая часть браузера, но мы еще не вдавались в подробности.
Движок JavaScript 101
Механизм JavaScript выполняет и компилирует JavaScript в собственный машинный код. Каждый крупный браузер разработал свой собственный JS-движок: Google Chrome использует V8, Safari использует JavaScriptCore, а Firefox использует SpiderMonkey.
В частности, мы будем работать с V8, поскольку он используется в Node.js и Electron, но другие движки построены таким же образом.
Каждый шаг будет содержать ссылку на код, отвечающий за него, чтобы вы могли ознакомиться с кодовой базой и продолжить исследование после этой статьи.
Мы будем работать с зеркалом V8 на GitHub, поскольку оно предоставляет удобный и хорошо известный пользовательский интерфейс для навигации по кодовой базе.
Подготовка исходного кода
Первое, что нужно сделать V8, - это загрузить исходный код. Это можно сделать через сеть, кэш или сервис-воркеры.
Как только код получен, нам нужно изменить его так, чтобы компилятор мог его понять. Этот процесс называется парсингом и состоит из двух частей: сканера и самого парсера.
Сканер берет файл JS и преобразует его в список известных токенов. Список всех токенов JS находится в файле keywords.txt.
Анализатор поднимает его вверх и создает абстрактное синтаксическое дерево (AST): древовидное представление исходного кода. Каждый узел дерева обозначает конструкцию, встречающуюся в коде.
Давайте посмотрим на простой пример:
function foo() {
let bar = 1;
return bar;
}Этот код создаст следующую древовидную структуру:
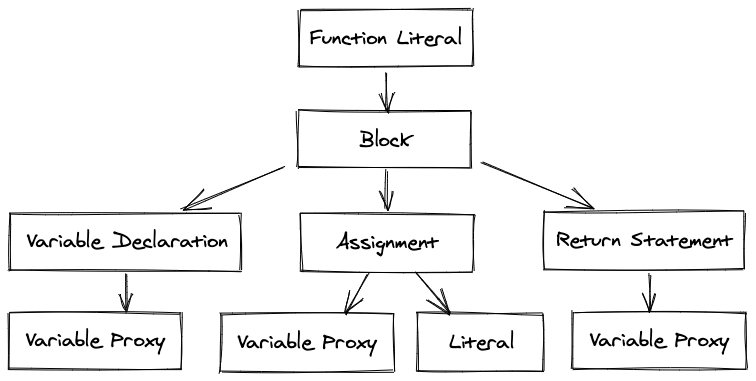
Вы можете выполнить этот код, выполнив обход предварительного заказа (корень, влево, вправо):
- Определите функцию
foo. - Объявите переменную
bar. - Назначьте
1вbar. - Верните
barиз функции.
Вы также увидите VariableProxy - элемент, который связывает абстрактную переменную с местом в памяти. Процесс разрешения VariableProxy называется анализом объема.
В нашем примере результат процесса VariableProxy будет указывать на одну и ту же переменную bar.
Парадигма Just-in-Time (JIT)
Обычно для выполнения кода язык программирования необходимо преобразовать в машинный код. Есть несколько подходов к тому, как и когда может произойти это преобразование.
Наиболее распространенный способ преобразования кода - выполнение предварительной компиляции. Это работает именно так, как звучит: код преобразуется в машинный код перед выполнением вашей программы на этапе компиляции.
Этот подход используется многими языками программирования, такими как C ++, Java и другими.
С другой стороны таблицы у нас есть интерпретация: каждая строка кода будет выполняться во время выполнения. Этот подход обычно используется в языках с динамической типизацией, таких как JavaScript и Python, поскольку невозможно узнать точный тип до выполнения.
Поскольку предварительная компиляция позволяет оценить весь код вместе, она может обеспечить лучшую оптимизацию и в конечном итоге произвести более производительный код. С другой стороны, интерпретацию проще реализовать, но обычно она медленнее, чем скомпилированный вариант.
Чтобы преобразовать код для динамических языков быстрее и эффективнее, был создан новый подход, названный компиляцией Just-in-Time (JIT). Он сочетает в себе лучшее из интерпретации и компиляции.
Используя интерпретацию как базовый метод, V8 может обнаруживать функции, которые используются чаще, чем другие, и компилировать их, используя информацию о типе из предыдущих выполнений.
Однако есть вероятность, что тип может измениться. Вместо этого нам нужно деоптимизировать скомпилированный код и вернуться к интерпретации (после этого мы можем перекомпилировать функцию после получения обратной связи нового типа).
Давайте рассмотрим каждую часть JIT-компиляции более подробно.
Переводчик
V8 использует интерпретатор под названием Ignition. Первоначально он берет абстрактное синтаксическое дерево и генерирует байтовый код.
Инструкции байтового кода также имеют метаданные, такие как позиции исходной строки для будущей отладки. Как правило, инструкции байтового кода соответствуют абстракциям JS.
Теперь возьмем наш пример и сгенерируем для него байт-код вручную:
LdaSmi #1 // write 1 to accumulator
Star r0 // read to r0 (bar) from accumulator
Ldar r0 // write from r0 (bar) to accumulator
Return // returns accumulatorВ Ignition есть так называемый аккумулятор - место, где вы можете хранить / читать значения.
Аккумулятор избавляет от необходимости толкать и выдвигать верхнюю часть стопки. Это также неявный аргумент для многих байт-кодов и обычно содержит результат операции. Return неявно возвращает аккумулятор.
Вы можете проверить весь доступный байтовый код в соответствующем исходном коде. Если вам интересно, как другие концепции JS (например, циклы async / await) представлены в байтовом коде, я считаю полезным прочитать эти ожидания тестирования.
Исполнение
После генерации Ignition интерпретирует инструкции, используя таблицу обработчиков, привязанных к байтовому коду. Для каждого байтового кода Ignition может искать соответствующие функции-обработчики и выполнять их с предоставленными аргументами.
Как мы упоминали ранее, этап выполнения также обеспечивает обратную связь типа о коде. Разберемся, как его собирают и управляют.
Во-первых, мы должны обсудить, как объекты JavaScript могут быть представлены в памяти. При наивном подходе мы можем создать словарь для каждого объекта и связать его с памятью.
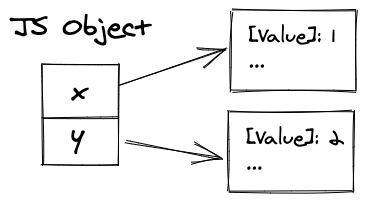
Однако обычно у нас много объектов с одинаковой структурой, поэтому было бы неэффективно хранить много дублированных словарей.
Чтобы решить эту проблему, V8 отделяет структуру объекта от самих значений с помощью форм объекта (или внутренних карт) и вектора значений в памяти.
Например, мы создаем литерал объекта:
let c = { x: 3 }
let d = { x: 5 }
c.y = 4В первой строке он создаст фигуру Map[c], имеющую свойство x со смещением 0.
Во второй строке V8 повторно использует ту же форму для новой переменной.
После третьей строки он создаст новую форму Map[c1] для свойства y со смещением 1 и создаст ссылку на предыдущую форму Map[c].
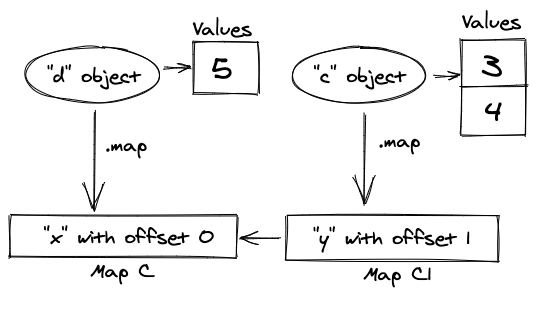
В приведенном выше примере вы можете видеть, что каждый объект может иметь ссылку на форму объекта, где для каждого имени свойства V8 может найти смещение для значения в памяти.
Формы объектов - это, по сути, связанные списки. Итак, если вы напишете c.x, V8 перейдет к началу списка, найдет там y, перейдет к связанной фигуре и, наконец, получит x и прочитает смещение от нее. Затем он перейдет к вектору памяти и вернет из него первый элемент.
Как вы понимаете, в большом веб-приложении вы увидите огромное количество связанных фигур. В то же время для поиска в связанном списке требуется линейное время, что делает поиск свойств действительно дорогостоящей операцией.
Чтобы решить эту проблему в V8, вы можете использовать встроенный кэш (IC). Он запоминает информацию о том, где найти свойства объектов, чтобы сократить количество поисков.
Вы можете думать об этом как о сайте для прослушивания в вашем коде: он отслеживает все события CALL, STORE и LOAD в функции и записывает все проходящие фигуры.
Структура данных для хранения IC называется вектором обратной связи. Это просто массив для хранения всех микросхем для функции.
function load(a) {
return a.key;
}Для приведенной выше функции вектор обратной связи будет выглядеть следующим образом:
[{ slot: 0, icType: LOAD, value: UNINIT }]Это простая функция только с одной ИС, которая имеет тип НАГРУЗКИ и значение UNINIT. Это означает, что он не инициализирован, и мы не знаем, что будет дальше.
Давайте вызовем эту функцию с разными аргументами и посмотрим, как изменится встроенный кэш.
let first = { key: 'first' } // shape A
let fast = { key: 'fast' } // the same shape A
let slow = { foo: 'slow' } // new shape B
load(first)
load(fast)
load(slow)После первого вызова функции load наш встроенный кеш получит обновленное значение:
[{ slot: 0, icType: LOAD, value: MONO(A) }]Это значение теперь становится мономорфным, что означает, что этот кеш может разрешиться только для формы A.
После второго вызова V8 проверит значение IC и увидит, что оно мономорфно и имеет ту же форму, что и переменнаяfast. Таким образом, он быстро вернет смещение и разрешит его.
В третий раз форма отличается от сохраненной. Таким образом, V8 вручную разрешит это и обновит значение до полиморфного состояния с помощью массива из двух возможных форм.
[{ slot: 0, icType: LOAD, value: POLY[A,B] }]Теперь каждый раз, когда мы вызываем эту функцию, V8 необходимо проверять не только одну форму, но и перебирать несколько вариантов.
Для более быстрого кода вы можете инициализировать объекты одним и тем же типом и не слишком сильно менять их структуру.
Примечание. Вы можете помнить об этом, но не делайте этого, если это приведет к дублированию кода или к менее выразительному коду.
Встроенные кеши также отслеживают, как часто они вызываются, чтобы решить, подходит ли он для оптимизации компилятора - Turbofan.
Компилятор
Зажигание только доходит до нас. Если функция становится достаточно горячей, она будет оптимизирована в компиляторе Turbofan, чтобы сделать ее быстрее.
Турбовентилятор берет байтовый код из Ignition и набирает обратную связь (вектор обратной связи) для функции, применяет набор сокращений на его основе и создает машинный код.
Как мы видели ранее, обратная связь типа не гарантирует, что она не изменится в будущем.
Например, оптимизированный код Turbofan основан на предположении, что некоторое дополнение всегда добавляет целые числа.
Но что было бы, если бы он получил строку? Этот процесс называется деоптимизацией. Мы выбрасываем оптимизированный код, возвращаемся к интерпретируемому коду, возобновляем выполнение и обновляем информацию о типе.
Резюме
В этой статье мы обсудили реализацию JS-движка и точные этапы выполнения JavaScript.
Подводя итог, давайте посмотрим на конвейер компиляции сверху.
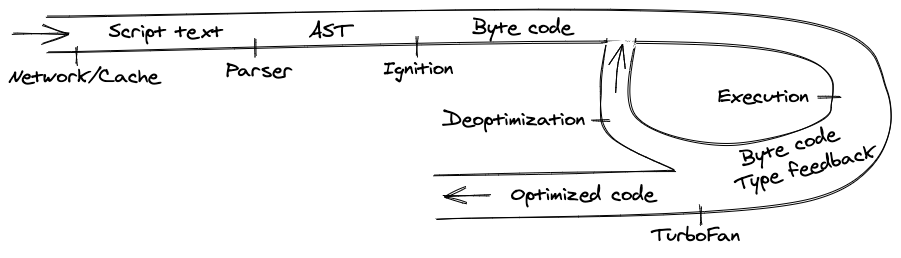
Мы рассмотрим это шаг за шагом:
- Все начинается с получения кода JavaScript из сети.
- V8 анализирует исходный код и превращает его в абстрактное синтаксическое дерево (AST).
- На основе этого AST интерпретатор Ignition может начать делать свое дело и создавать байт-код.
- В этот момент движок запускает код и собирает отзывы о типах.
- Чтобы он работал быстрее, байтовый код может быть отправлен оптимизирующему компилятору вместе с данными обратной связи. Оптимизирующий компилятор делает на его основе определенные предположения, а затем создает высокооптимизированный машинный код.
- Если в какой-то момент одно из предположений оказывается неверным, оптимизирующий компилятор деоптимизируется и возвращается к интерпретатору.