Отслеживание работоспособности API с помощью Prometheus

APISIX имеет механизм проверки работоспособности, который заранее проверяет состояние работоспособности апстрим узлов в вашей системе. Кроме того, APISIX интегрируется с Prometheus через свой плагин, который предоставляет восходящим узлам (несколько экземпляров серверной службы API, которой управляет APISIX) метрики проверки работоспособности на конечной точке метрик Prometheus, как правило, по пути URL: /apisix/prometheus/metrics
В этом посте мы расскажем, как включить и отслеживать проверки работоспособности API с помощью APISIX и Prometheus.
Предпосылки
В этом руководстве предполагается, что следующие инструменты установлены локально:
- Прежде чем начать, полезно иметь базовое представление об APISIX. Также будет полезно знание API-шлюза и его ключевых понятий, таких как маршруты, апстрим, Admin API, плагины и протокол HTTP.
- Docker используется для установки контейнеров etcd и APISIX.
- Установите cURL, чтобы отправлять запросы в службы для проверки.
Запустите демонстрационный проект APISIX
Этот проект использует существующий предварительно определенный файл конфигурации Docker Compose для настройки, развертывания и запуска APISIX, etcd, Prometheus и других сервисов с помощью одной команды. Сначала клонируйте репозиторий apisix-prometheus-api-health-check на GitHub, откройте его в своем любимом редакторе и запустите проект, просто запустив docker compose up из корневой папки проекта.
Когда вы запускаете проект, Docker загружает все образы, необходимые для запуска. Полный список сервисов можно посмотреть в файле docker-compose.yaml.
Добавьте конечные точки API проверки работоспособности в апстриме
Чтобы периодически проверять работоспособность API, APISIX необходим HTTP-путь к конечной точке работоспособности вышестоящей службы. Итак, сначала вам нужно добавить конечную точку /health для вашей серверной службы. Оттуда вы просматриваете наиболее релевантные показатели для этой службы, такие как использование памяти, подключение к базе данных, продолжительность ответа и многое другое.
Предположим, что у нас есть две серверные службы REST API web1 и web2, запущенные с использованием демонстрационного проекта, и каждая из них имеет свою собственную конечную точку проверки работоспособности по адресу URL /health. На данном этапе вам не нужно выполнять дополнительные настройки. На самом деле вы можете заменить их своими бэкенд сервисами.
Самый простой и стандартный способ проверить статус службы – определить новую конечную точку проверки работоспособности, например/healthили/status
Настройка проверок работоспособности в APISIX
Этот процесс включает проверку рабочего состояния «апстрим» узлов. APISIX предоставляет два типа проверок работоспособности: активные проверки и пассивные проверки соответственно. Подробнее о проверках работоспособности и о том, как их включить, читайте здесь. Используйте Admin API для создания объекта "Upstream". Вот пример создания объекта "Upstream" с двумя узлами (для каждой определенной нами серверной службы) и настройки параметров проверки работоспособности в объекте апстрим:
curl "http://127.0.0.1:9180/apisix/admin/upstreams/1" -H "X-API-KEY: edd1c9f034335f136f87ad84b625c8f1" -X PUT -d '
{
"nodes": {
"web1:80": 1,
"web2:80": 1
},
"checks": {
"active": {
"timeout": 5,
"type": "http",
"http_path": "/health",
"healthy": {
"interval": 2,
"successes": 1
},
"unhealthy": {
"interval": 1,
"http_failures": 2
}
}
}
}'В этом примере настраивается активная проверка работоспособности на конечной точке /health узла. Он считает узел работоспособным после одной успешной проверки работоспособности и неработоспособным после двух неудачных проверок работоспособности.
Обратите внимание, что иногда вам могут понадобиться IP-адреса апстрим узлов, а не их домены (web1иweb2), если вы запускаете службы вне сети докеров. По замыслу проверка работоспособности будет запущена только в том случае, если количество узлов (разрешенных IP-адресов) больше 1.
Включите плагин Prometheus
Создайте глобальное правило для включения плагина prometheus на всех маршрутах, добавив "prometheus": {} в опции плагинов. APISIX собирает внутренние показатели времени выполнения и предоставляет их через порт 9091 и URL по умолчанию /api six/prometheus/metrics, которые Prometheus может очистить. Также можно настроить порт экспорта и путь URI, добавить дополнительные метки, частоту этих сбоев и другие параметры, настроив их в файле конфигурации Prometheus /prometheus_conf/prometheus.yml.
curl "http://127.0.0.1:9180/apisix/admin/global_rules" -H "X-API-KEY: edd1c9f034335f136f87ad84b625c8f1" -X PUT -d '{
"id": "rule-for-metrics",
"plugins": {
"prometheus":{}
}
}'Создайте маршрут
Создайте объект Route для маршрутизации входящих запросов к апстрим узлам:
curl "http://127.0.0.1:9180/apisix/admin/routes/1" -H "X-API-KEY: edd1c9f034335f136f87ad84b625c8f1" -X PUT -d '
{
"name": "backend-service-route",
"methods": ["GET"],
"uri": "/",
"upstream_id": "1"
}'Отправьте запросы проверки на маршрут
Чтобы сгенерировать некоторые показатели, вы пытаетесь отправить несколько запросов на маршрут, который мы создали на предыдущем шаге:
curl -i -X GET "http://localhost:9080/"Если вы запустите приведенные выше запросы пару раз, вы увидите из ответов, что APISX направляет одни запросы на node1, а другие — на node2. Вот как работает балансировка нагрузки шлюза!
HTTP/1.1 200 OK
Content-Type: text/plain; charset=utf-8
Content-Length: 10
Connection: keep-alive
Date: Sat, 22 Jul 2023 10:16:38 GMT
Server: APISIX/3.3.0
hello web2
...
HTTP/1.1 200 OK
Content-Type: text/plain; charset=utf-8
Content-Length: 10
Connection: keep-alive
Date: Sat, 22 Jul 2023 10:16:39 GMT
Server: APISIX/3.3.0
hello web1Сбор данных проверки работоспособности с помощью плагина Prometheus
Как только проверки работоспособности и маршрутизатор настроены в APISIX, вы можете использовать Prometheus для мониторинга проверок работоспособности. APISIX автоматически предоставляет данные метрик проверки работоспособности для ваших API, если параметр проверки работоспособности включен для вышестоящих узлов. Вы увидите показатели в ответе после их получения из API SIX:
curl -i http://127.0.0.1:9091/apisix/prometheus/metricsПример вывода:
# HELP apisix_http_requests_total The total number of client requests since APISIX started
# TYPE apisix_http_requests_total gauge
apisix_http_requests_total 119740
# HELP apisix_http_status HTTP status codes per service in APISIX
# TYPE apisix_http_status counter
apisix_http_status{code="200",route="1",matched_uri="/",matched_host="",service="",consumer="",node="172.27.0.5"} 29
apisix_http_status{code="200",route="1",matched_uri="/",matched_host="",service="",consumer="",node="172.27.0.7"} 12
# HELP apisix_upstream_status Upstream status from health check
# TYPE apisix_upstream_status gauge
apisix_upstream_status{name="/apisix/upstreams/1",ip="172.27.0.5",port="443"} 0
apisix_upstream_status{name="/apisix/upstreams/1",ip="172.27.0.5",port="80"} 1
apisix_upstream_status{name="/apisix/upstreams/1",ip="172.27.0.7",port="443"} 0
apisix_upstream_status{name="/apisix/upstreams/1",ip="172.27.0.7",port="80"} 1Данные проверки работоспособности представлены с меткой метрики apisix_upstream_status. Он имеет такие атрибуты, как апстрим name, IP и port. Значение 1 означает работоспособность, а 0 означает, что вышестоящий узел неисправен.
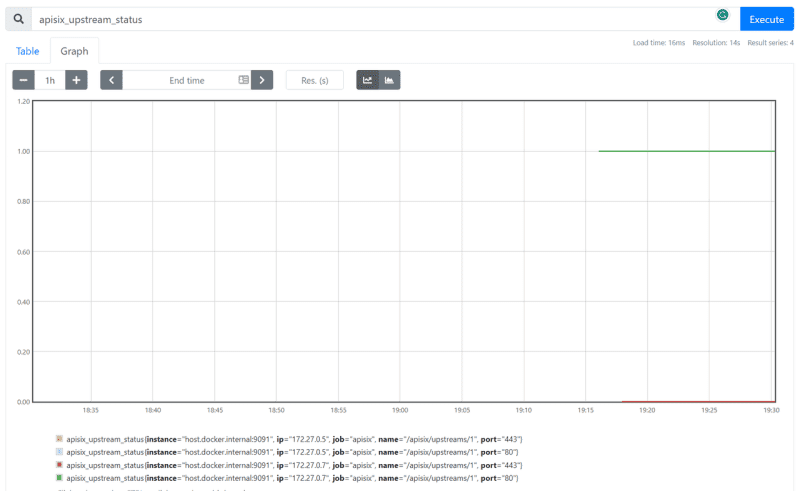
Визуализируйте данные на приборной панели Prometheus
Перейдите по адресу http://localhost:9090/, где запущен экземпляр Prometheus в Docker, и введите выражение apisix_upstream_status в строке поиска. Вы также можете увидеть вывод статусов проверки работоспособности апстрим узлов на Prometheus dashboard в виде таблицы или графика:
Очистка
После того, как вы закончите экспериментировать с метриками проверки работоспособности Prometheus и APISIX Gateway, вы можете использовать следующие команды, чтобы остановить и удалить службы, созданные в этом руководстве:
docker compose downСледующие шаги
Теперь вы узнали, как настраивать и отслеживать проверки работоспособности API с помощью Prometheus и APISIX. Плагин APISIX Prometheus настроен на автоматическое подключение Grafana для визуализации метрик. Продолжайте изучать данные и настройте панель инструментов Grafana, добавив панель, показывающую количество активных проверок работоспособности.