Пользовательские поля: предоставьте вашим клиентам поля, которые им нужны

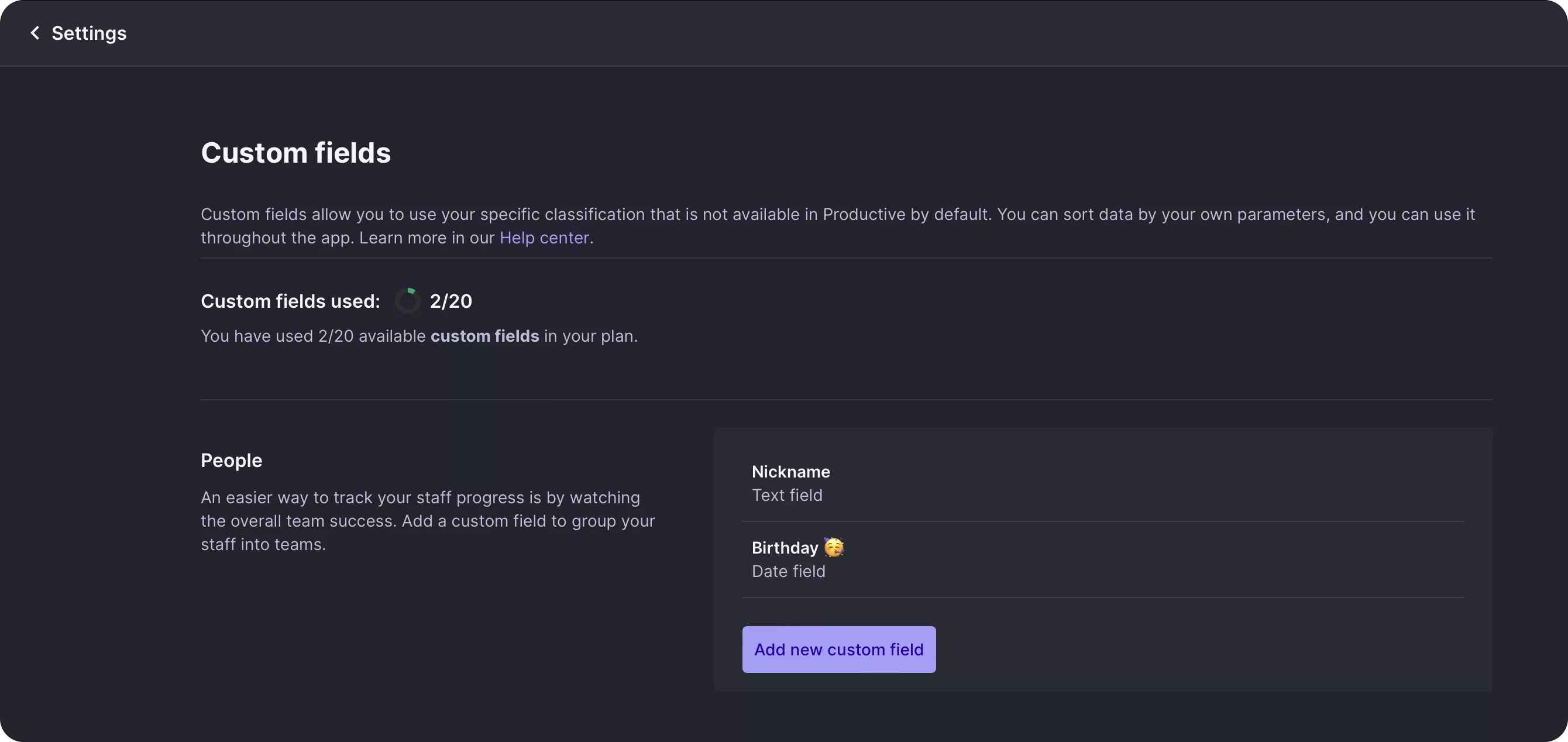
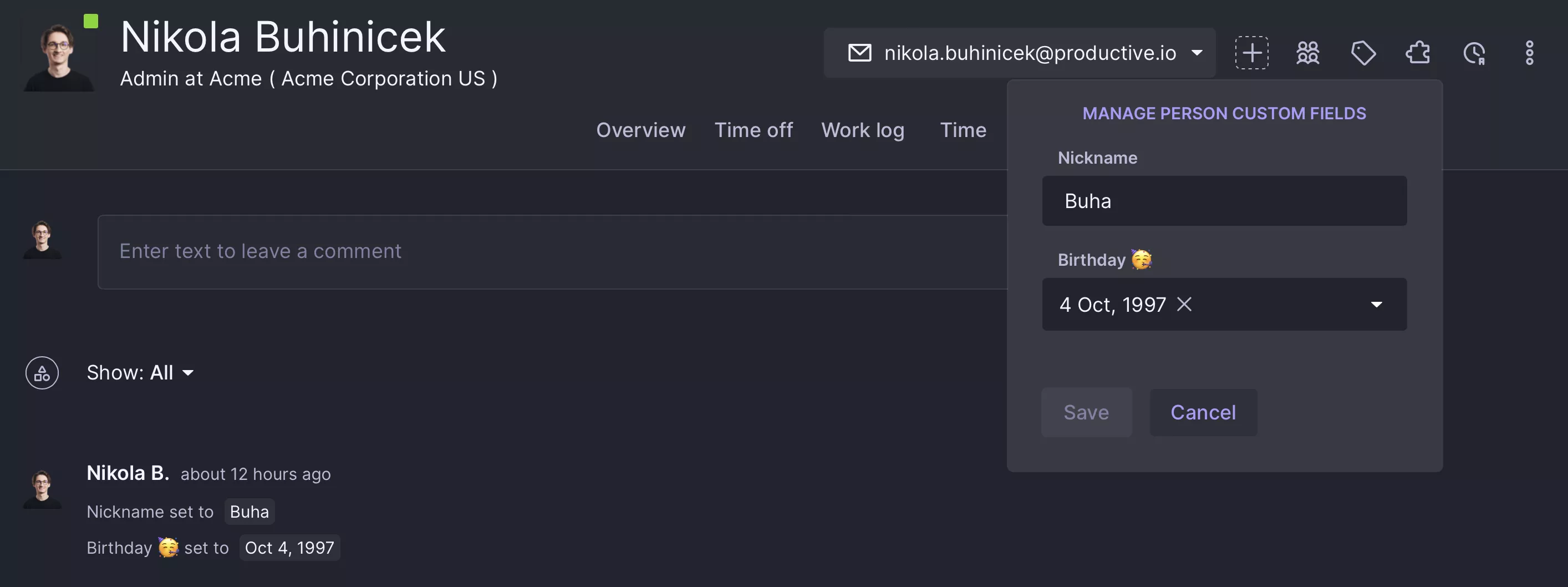
Допустим, один из наших клиентов, цифровое агентство ACME digital, хочет отслеживать псевдонимы своих сотрудников и иметь возможность искать их по этому полю. Помимо этого, они также хотели бы отслеживать свои дни рождения и иметь возможность сортировать их и группировать по этой дате.
Для меня, как разработчика, это звучит настолько просто, насколько это возможно — добавьте два новых столбца в таблицу people, откройте эти атрибуты для редактирования через API и отправьте их обратно в ответе.
Но должны ли мы это делать? Должны ли мы добавлять все виды полей в наши модели, даже если эти поля будут использоваться лишь горсткой наших клиентов?
Позвольте мне показать вам, как мы справились с этим типом запросов функций и создали вокруг него довольно общую систему.
Чего хотели наши клиенты?
Нам было совершенно ясно, чего хотят наши клиенты, и это было:
- Иметь возможность добавлять дополнительные поля к некоторым нашим моделям (Люди, проекты, задачи, ...).
- Иметь различные типы данных в этих полях (текст, числа или даты).
- Иметь возможность искать, сортировать или даже группировать по этим полям.
Модель пользовательских полей
Мы строим RESTful API, который отформатирован в формате JSON:спецификации API и хранит наши данные в реляционной базе данных MySQL8, некоторые вещи были довольно просты – нам нужна новая модель, и мы назовем это Custom Field.
Основными атрибутами этой модели должны быть:
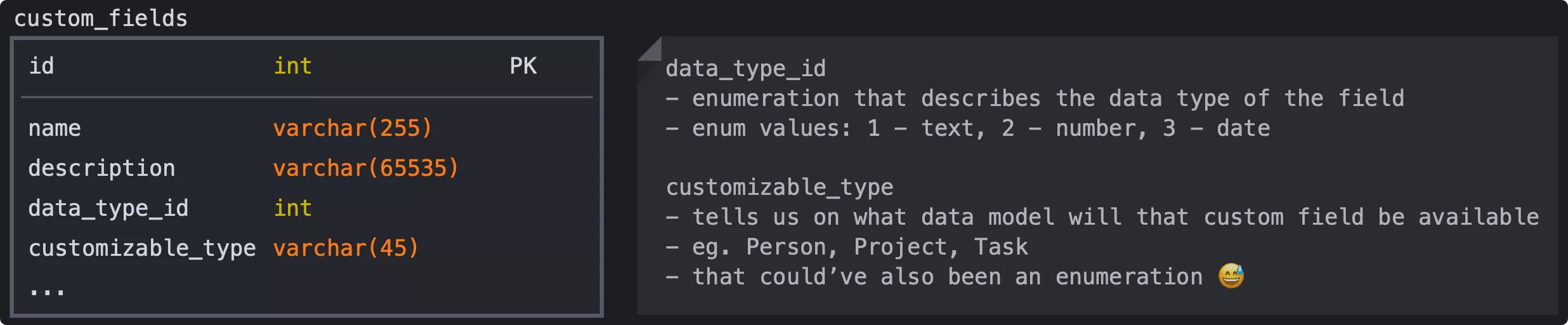
Как хранить значения полей?
Итак, теперь, когда мы знаем, как определять пользовательские поля, как мы можем узнать, какое значение кто-то присвоил пользовательскому полю для некоторого объекта? И где хранить эту информацию?
На ум пришли три возможных решения:
1. Добавление ограниченного количества столбцов custom_field в наши модели
Мы можем добавить несколько столбцов custom_field в наши модели, и это сработает для некоторых наших клиентов, но всегда найдутся другие, которым требуется несколько дополнительных полей. Добавление множества столбцов в наши модели, безусловно, не лучшее решение, мы можем сделать лучше.
2. Добавление таблицы соединений
Как упоминалось ранее, несмотря на то, что вы полагаетесь на реляционную базу данных, объединяемая таблица звучит как универсальный подход. Эта таблица была бы простой таблицей соединения пользовательского поля с полиморфным целевым объектом. Помимо этих внешних ключей, у нас был бы столбец для хранения значения.
3. Добавление в наши модели одного столбца JSON
Это звучало настолько гибко, насколько это возможно. Это была бы простая карта, где ключом был бы идентификатор пользовательского поля, а значением - присвоенное значение для этого пользовательского поля.

Почему мы в итоге выбрали JSON
Первое решение было слишком ограниченным, поэтому мы сразу отказались от него и сосредоточились на двух оставшихся решениях.
С одной стороны, было бы лучше, если бы значения пользовательских полей были представлены моделью, но, с другой стороны, на самом деле мы мало что сможем сделать с этими данными. Это были бы просто данные, которые наши пользователи устанавливают в наших объектах, данные, которые не важны для нашей бизнес-логики. Таким образом, простой столбец JSON тоже звучит неплохо.
Аспект поиска и сортировки в этом запросе функций был, вероятно, самым важным для нас. Предполагалось, что это должно было работать как можно быстрее, не влияя на нашу производительность.
Вот почему мы внедрили оба решения, протестировали множество сценариев поиска/сортировки/группирования (скоро мы рассмотрим это более подробно), а затем проверили показатели.
Более быстрым решением было второе, со столбцом JSON, и это имело смысл для нас. Это решение не использует JOIN предложения в SQL, поскольку значения записываются непосредственно в искомой таблице и могут быть запрошены в WHERE предложении. К счастью для нас, MySQL8 поддерживает множество отличных функций для работы со столбцами JSON (JSON_EXTRACT, JSON_UNQUOTE, JSON_CONTAINS и другие).
Теперь, давайте углубимся в кодирование
С точки зрения разработки, мы сделали следующее:
- Добавили новую модель,
Custom Field, и реализовали операции CRUD, которые можно вызывать через API. - Написали схемы миграции, которые добавили в столбец JSON –
custom_fields– в некоторые из наших моделей (люди, проекты, задачи, ...). - Открыли атрибут
custom_fields, чтобы его можно было редактировать через API. - Написали общую проверку, которая проверяет, все ли значения в хэше
custom_fieldsимеют соответствующий тип данных. - Добавили атрибут
custom_fieldsв ответ API соответствующих моделей.
Это была большая часть работы, которую нам нужно было выполнить, чтобы иметь возможность управлять пользовательскими полями в наших моделях.
Но…как насчет аспектов поиска и сортировки пользовательских полей?
Поиск по значениям пользовательских полей
У нас уже было универсальное решение, написанное для поиска по API.
У нас есть формат отправки параметров запроса для поиска, например filter[attribute][operation]=value. Для поиска по пользовательским полям мы хотели сохранить тот же формат, поэтому в итоге выбрали довольно похожий –filter[custom_fields][custom_field_id][operation]=value.
Нам пришлось добавить оператор if-else, который обрабатывал бы фильтрацию пользовательских полей иным способом, чем фильтрация по другим атрибутам, поскольку формат содержал один дополнительный аргумент — custom_field_id.
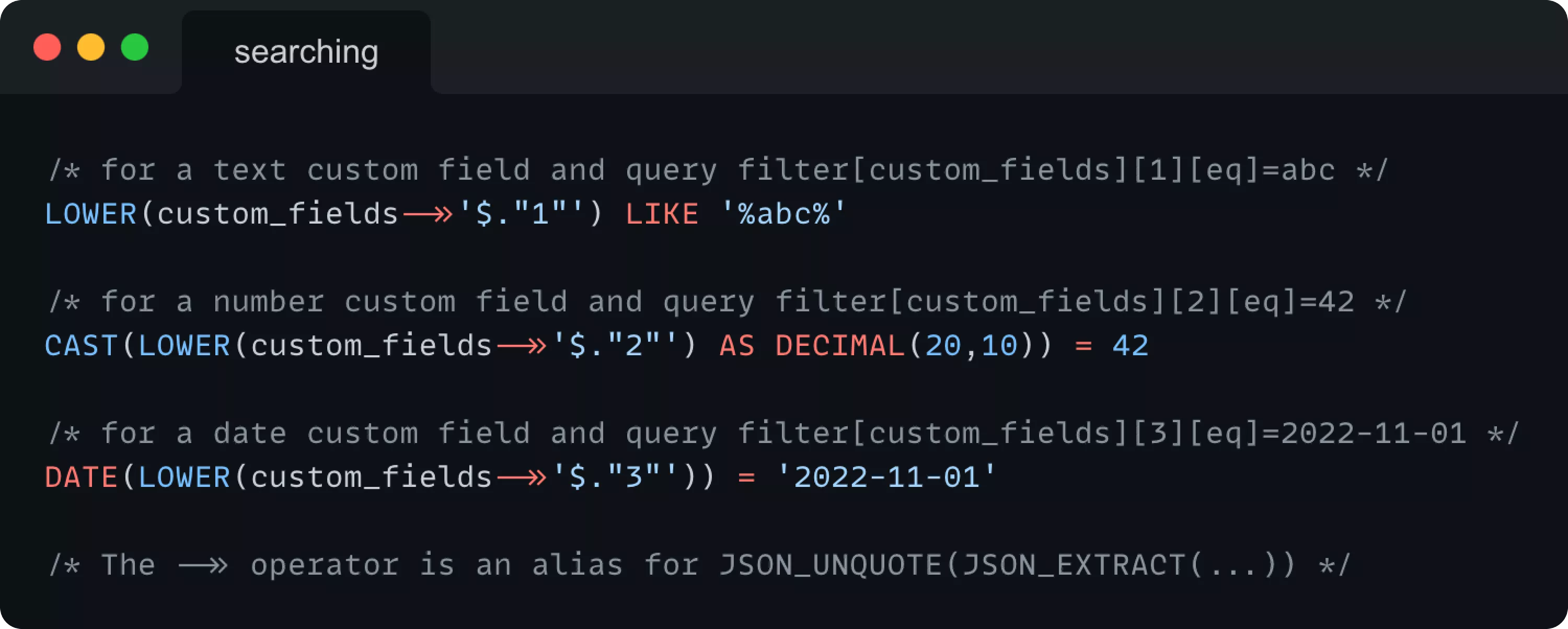
Отличием логики фильтрации было то, что мы должны были загрузить пользовательское поле, по которому выполняется фильтрация, и проверить, к какому типу данных относятся его значения. Это необходимо для преобразования значений в числа или даты — текстовые значения не имеют значения.
Таким образом, параметры запроса и его аналоги в SQL-запросе, основанные на типе пользовательского поля, будут выглядеть следующим образом:
Сортировка по значениям пользовательских полей
Концепция сортировки по атрибутам — это то, с чем мы также уже сталкивались при абстрагировании логики.
Единственное, что меняется при сортировке по пользовательским полям, это то, что нам сначала нужно привести значения, а затем отсортировать по ним.
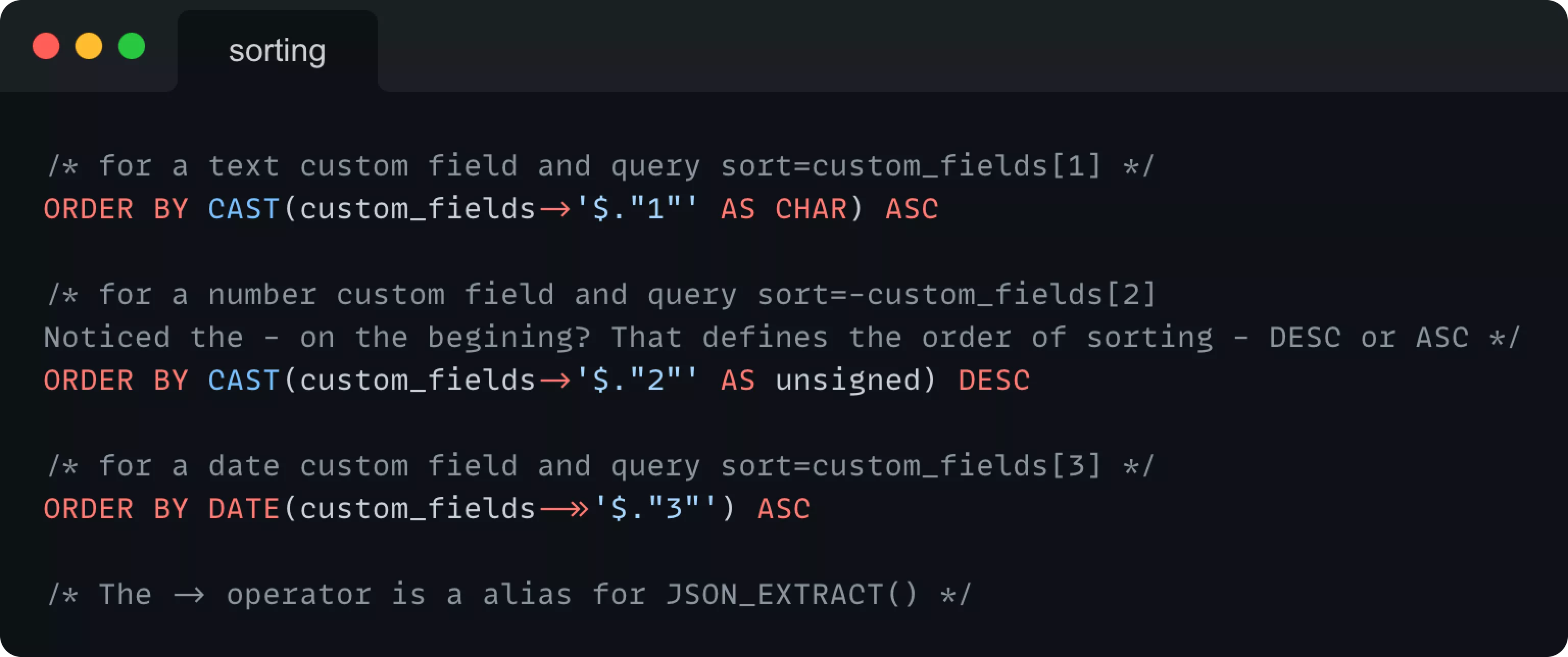
Еще раз, в формате сортировщиков пользовательских полей (sort=custom_fields[custom_field_id]) произошли небольшие изменения по сравнению с сортировкой по стандартному атрибуту (sort=attribute). Нам нужно обрабатывать сортировщики custom_fields отдельно, потому что мы должны загрузить нужное custom_field и проверить его тип.
Тогда ORDER BY инструкция, основанная на пользовательских типах полей, выглядит следующим образом:
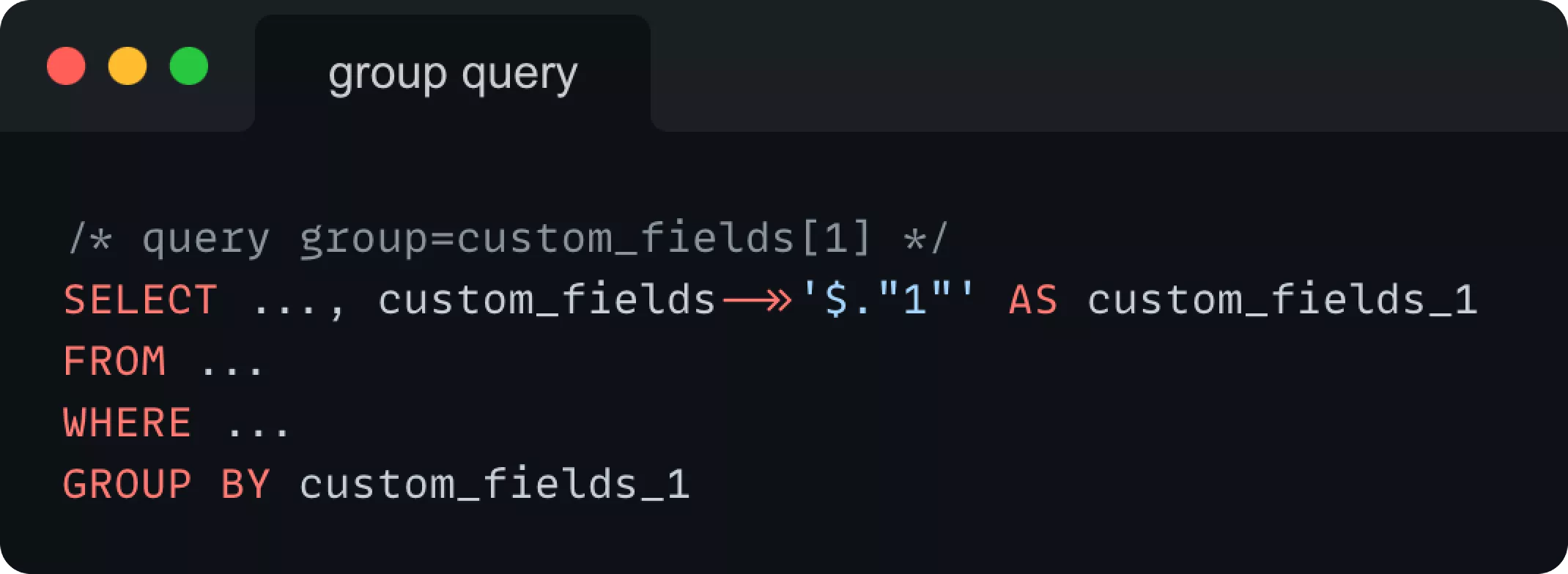
Группировка по значениям пользовательских полей
Это было весело. Основной момент здесь заключался в том, что вы должны включить пользовательские поля в виде неких столбцов, указанных в SELECT инструкции, чтобы позже вы могли использовать эти столбцы в GROUP BY инструкции.
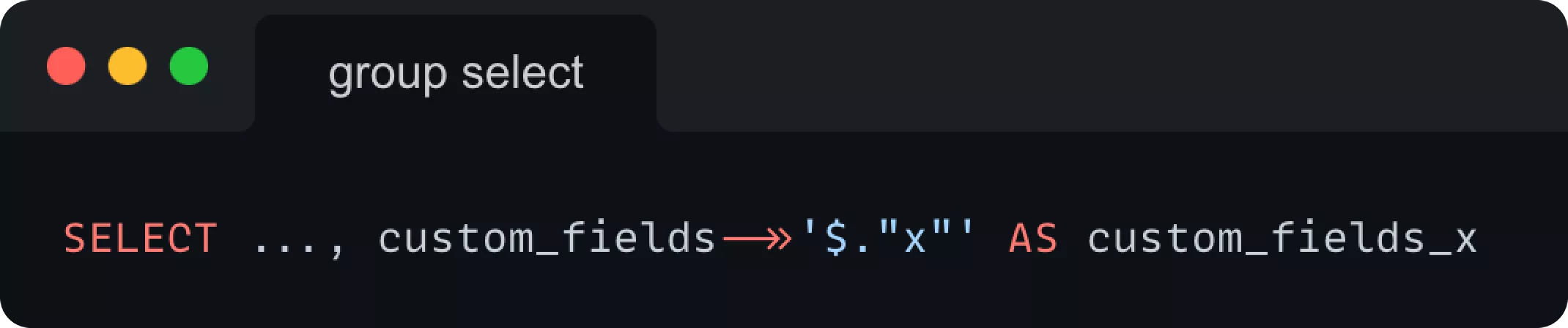
Чтобы получить пользовательское поле в SELECT инструкции, вы должны создать для него виртуальный столбец. Все, что нам нужно было сделать, это извлечь значения сгруппированного пользовательского поля и присвоить этому виртуальному столбцу псевдоним, чтобы мы могли ссылаться на него в GROUP BY инструкции. Для псевдонима столбца мы выбрали формат custom_fields_{custom_field_id}.
Для пользовательского поля с id=x это делается следующим образом:
Как только мы определим виртуальный столбец, часть группировки будет выполнена просто, путем добавления GROUP BY инструкции с ранее упомянутым псевдонимом.
Итак, в итоге вы получаете SQL-запрос типа:
Что получили наши клиенты
Простой способ определения настраиваемых полей:
И место для присвоения значений их полям:
Итоги
Мы предоставили нашим клиентам возможность определять пользовательские поля в наших моделях данных. Кроме того, мы сделали возможным поиск, сортировку и группировку по этим полям.
Вскоре у нас появилось еще больше запросов, основанных на нашей архитектуре пользовательских полей. Поля, которые мы поддерживали поначалу, были в порядке вещей, но теперь нашим клиентам захотелось больше типов полей. Они хотели:
- Иметь выпадающие пользовательские поля
- Иметь реляционные пользовательские поля
- Поле, значениями которого будут объекты из одной из наших существующих моделей данных