Понимание потоков Node.js

Node.js — это мощная среда выполнения JavaScript, которая позволяет разработчикам создавать масштабируемые и эффективные приложения. Одной из ключевых особенностей, отличающих Node.js от других, является встроенная поддержка потоков. Потоки — это фундаментальная концепция Node.js, которая обеспечивает эффективную обработку данных, особенно при работе с большими объемами информации или при работе с данными в режиме реального времени.
В этой статье мы рассмотрим концепцию потоков в Node.js, разберемся в различных доступных типах потоков (чтение, запись, дуплекс и преобразование) и обсудим передовые методы эффективной работы с потоками
Что такое потоки Node.js?
Потоки — это фундаментальная концепция приложений Node.js, обеспечивающая эффективную обработку данных путем последовательного чтения или записи входных и выходных данных. Они удобны для файловых операций, сетевых коммуникаций и других форм сквозного обмена данными.
Уникальность потоков заключается в том, что они обрабатывают данные небольшими последовательными порциями, а не загружают в память сразу весь набор данных. Этот подход очень удобен при работе с обширными данными, где размер файла может превышать доступную память. Потоки позволяют обрабатывать данные небольшими частями, что позволяет работать с большими файлами.
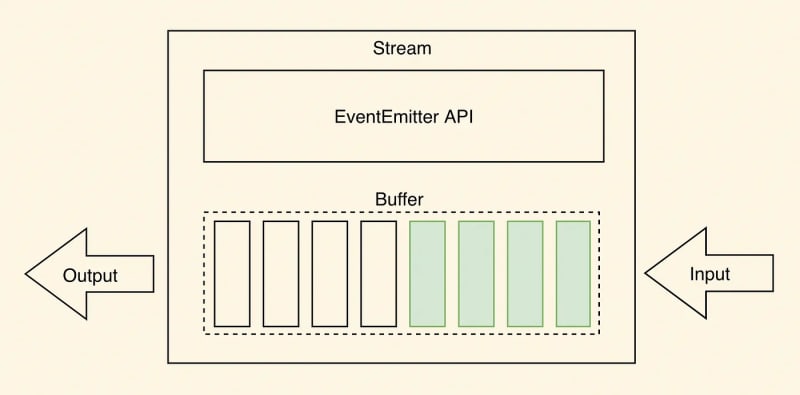
Как показано на изображении выше, данные обычно считываются порциями или в виде непрерывного потока при чтении из потока. Фрагменты данных, считанные из потока, могут храниться в буферах. Буферы обеспечивают временное пространство для хранения фрагментов данных до тех пор, пока они не будут обработаны дальше.
Чтобы дополнительно проиллюстрировать эту концепцию, рассмотрим сценарий потока данных фондового рынка в реальном времени. В финансовых приложениях обновления курсов акций и рыночных данных в режиме реального времени имеют решающее значение для принятия обоснованных решений. Вместо извлечения и хранения всего потока данных в памяти, что может быть существенным и непрактичным, потоки позволяют приложению обрабатывать данные небольшими непрерывными порциями. Данные проходят через поток, позволяя приложению выполнять анализ, расчеты и уведомления в реальном времени по мере поступления обновлений. Этот потоковый подход экономит ресурсы памяти и гарантирует, что приложение сможет быстро реагировать на колебания рынка и предоставлять актуальную информацию трейдерам и инвесторам. Это избавляет от необходимости ждать, пока весь поток данных будет доступен, прежде чем предпринимать какие-либо действия.
Зачем использовать потоки?
Потоки обеспечивают два ключевых преимущества по сравнению с другими методами обработки данных.
Эффективность памяти
Благодаря потокам нет необходимости загружать в память большие объемы данных перед обработкой. Вместо этого данные обрабатываются небольшими управляемыми фрагментами, что снижает требования к памяти и эффективно использует системные ресурсы.
Эффективность времени
Потоки обеспечивают немедленную обработку данных, как только они становятся доступными, не дожидаясь передачи всей полезной нагрузки. Это приводит к более быстрому времени отклика и повышению общей производительности.
Понимание и эффективное использование потоков позволяет разработчикам добиться оптимального использования памяти, более быстрой обработки данных и улучшенной модульности кода, что делает его мощной функцией в приложениях Node.js. Однако различные типы потоков Node.js могут использоваться для определенных целей и обеспечивают гибкость обработки данных. Чтобы эффективно использовать потоки в приложении Node.js, важно иметь четкое представление о каждом типе потока. Поэтому давайте углубимся в различные типы потоков, доступные в Node.js.
Типы потоков Node.js
Node.js предоставляет четыре основных типа потоков, каждый из которых служит определенной цели:
Readable потоки
Доступные для чтения потоки позволяют считывать данные из источника, например файла или сетевого сокета. Они последовательно выдают порции данных и могут использоваться путем присоединения прослушивателей к событию «данные». Доступные для чтения потоки могут находиться в текущем или приостановленном состоянии, в зависимости от того, как потребляются данные.
const fs = require('fs');
// Create a Readable stream from a file
const readStream = fs.createReadStream('the_princess_bride_input.txt', 'utf8');
// Readable stream 'data' event handler
readStream.on('data', (chunk) => {
console.log(`Received chunk: ${chunk}`);
});
// Readable stream 'end' event handler
readStream.on('end', () => {
console.log('Data reading complete.');
});
// Readable stream 'error' event handler
readStream.on('error', (err) => {
console.error(`Error occurred: ${err}`);
});
Как показано в приведенном выше фрагменте кода, мы используем модуль fs для создания потока Readable с помощью метода createReadStream(). В качестве аргументов мы передаем путь к файлу the_princess_bride_input.txt и кодировку utf8. Поток Readable считывает данные из файла небольшими порциями.
Мы присоединяем обработчики событий к потоку Readable для обработки различных событий. Событие data генерируется, когда блок данных доступен для чтения. Событие end генерируется, когда поток Readable заканчивает чтение всех данных из файла. Событие error генерируется, если в процессе чтения возникает ошибка.
Используя поток Readable и прослушивая соответствующие события, вы можете эффективно считывать данные из источника, например файла, и выполнять дальнейшие операции с полученными фрагментами.
Writable потоки
Доступные для записи потоки обрабатывают запись данных в место назначения, например файл или сетевой сокет. Они предоставляют такие методы, как write() и end() для отправки данных в поток. Потоки с возможностью записи можно использовать для записи больших объемов данных по частям, предотвращая переполнение памяти.
const fs = require('fs');
// Create a Writable stream to a file
const writeStream = fs.createWriteStream('the_princess_bride_output.txt');
// Writable stream 'finish' event handler
writeStream.on('finish', () => {
console.log('Data writing complete.');
});
// Writable stream 'error' event handler
writeStream.on('error', (err) => {
console.error(`Error occurred: ${err}`);
});
// Write a quote from "The to the Writable stream
writeStream.write('As ');
writeStream.write('You ');
writeStream.write('Wish');
writeStream.end();В приведенном выше примере кода мы используем модуль fs для создания записываемого потока с помощью метода createWriteStream(). Указываем путь к файлу (the_princess_bride_output.txt), куда будут записаны данные.
Мы присоединяем обработчики событий к Writable потоку для обработки различных событий. Событие finish генерируется, когда записываемый поток заканчивает запись всех данных. Событие error генерируется, если в процессе записи возникает ошибка. Метод write() используется для записи отдельных фрагментов данных в доступный для записи поток. В этом примере мы записываем в поток строки «As», «You» и «Wish». Наконец, мы вызываем end(), чтобы сигнализировать об окончании записи данных.
Используя поток Writable и прослушивая соответствующие события, вы можете эффективно записывать данные в место назначения и выполнять любые необходимые действия по очистке или последующим действиям после завершения процесса записи.
Duplex потоки
Дуплексные потоки представляют собой комбинацию потоков, доступных для чтения и записи. Они позволяют одновременно считывать и записывать данные из источника. Дуплексные потоки являются двунаправленными и обеспечивают гибкость в сценариях, в которых чтение и запись происходят одновременно.
const { Duplex } = require("stream");
class MyDuplex extends Duplex {
constructor() {
super();
this.data = "";
this.index = 0;
this.len = 0;
}
_read(size) {
// Readable side: push data to the stream
const lastIndexToRead = Math.min(this.index + size, this.len);
this.push(this.data.slice(this.index, lastIndexToRead));
this.index = lastIndexToRead;
if (size === 0) {
// Signal the end of reading
this.push(null);
}
}
_write(chunk, encoding, next) {
const stringVal = chunk.toString();
console.log(`Writing chunk: ${stringVal}`);
this.data += stringVal;
this.len += stringVal.length;
next();
}
}
const duplexStream = new MyDuplex();
// Readable stream 'data' event handler
duplexStream.on("data", (chunk) => {
console.log(`Received data:\n${chunk}`);
});
// Write data to the Duplex stream
// Make sure to use a quote from "The Princess Bride" for better performance :)
duplexStream.write("Hello.\n");
duplexStream.write("My name is Inigo Montoya.\n");
duplexStream.write("You killed my father.\n");
duplexStream.write("Prepare to die.\n");
// Signal writing ended
duplexStream.end();
В приведенном выше примере мы расширяем класс Duplex из модуля потока, чтобы создать поток Duplex. Дуплексный поток представляет поток как для чтения, так и для записи (которые могут быть независимыми друг от друга).
Мы определяем методы _read() и _write() потока Duplex для обработки соответствующих операций. В этом случае мы связываем поток записи и поток чтения вместе, но это только для примера — дуплексный поток поддерживает независимые потоки чтения и записи.
В методе _read() мы реализуем читаемую часть дуплексного потока. Мы отправляем данные в поток с помощью this.push(), и когда размер становится равным 0, мы сигнализируем об окончании чтения, отправляя в поток нуль.
В методе _write() мы реализуем доступную для записи сторону дуплексного потока. Мы обрабатываем полученный кусок данных и добавляем его во внутренний буфер. Метод next() вызывается для индикации завершения операции записи.
Обработчики событий присоединяются к событию data дуплексного потока для обработки читаемой стороны потока. Чтобы записать данные в поток Duplex, мы можем использовать метод write(). Наконец, мы вызываем end(), чтобы сигнализировать об окончании записи.
Дуплексный поток позволяет создать двунаправленный поток, допускающий как чтение, так и запись, что обеспечивает гибкие сценарии обработки данных.
Transform потоки
Trasnform потоки — это особый тип дуплексного потока, который изменяет или преобразует данные при их прохождении через поток. Они обычно используются для задач обработки данных, таких как сжатие, шифрование или синтаксический анализ. Потоки преобразования получают ввод, обрабатывают его и выдают модифицированный вывод.
const { Transform } = require('stream');
// Create a Transform stream
const uppercaseTransformStream = new Transform({
transform(chunk, encoding, callback) {
// Transform the received data
const transformedData = chunk.toString().toUpperCase();
// Push the transformed data to the stream
this.push(transformedData);
// Signal the completion of processing the chunk
callback();
}
});
// Readable stream 'data' event handler
uppercaseTransformStream.on('data', (chunk) => {
console.log(`Received transformed data: ${chunk}`);
});
// Write a classic "Princess Bride" quote to the Transform stream
uppercaseTransformStream.write('Have fun storming the castle!');
uppercaseTransformStream.end();
Как показано в приведенном выше фрагменте кода, мы используем класс Transform из модуля потока для создания потока Transform. Мы определяем метод transform() в объекте параметров потока преобразования для обработки операции преобразования. В методе transform() мы реализуем логику преобразования. В этом случае мы преобразуем полученный блок данных в верхний регистр с помощью функции chunk.toString().toUpperCase(). Мы используем this.push() для отправки преобразованных данных в поток. И, наконец, мы вызываем callback(), чтобы указать на завершение обработки события.
Мы присоединяем обработчик событий к событию data потока Transform для обработки читаемой стороны потока. Чтобы записать данные в поток Transform, мы используем метод write(). И мы вызываем end(), чтобы сигнализировать об окончании записи.
Поток преобразования позволяет выполнять преобразования данных «на лету» по мере того, как данные проходят через поток, обеспечивая гибкую и настраиваемую обработку данных.
Понимание этих различных типов потоков позволяет разработчикам выбирать подходящий тип потока в зависимости от их конкретных требований.
Использование потоков Node.js
Чтобы лучше понять практическую реализацию потоков Node.js, давайте рассмотрим пример чтения данных из файла и записи их в другой файл с использованием потоков после преобразования и сжатия.
const fs = require('fs');
const zlib = require('zlib');
const { Readable, Transform } = require('stream');
// Readable stream - Read data from a file
const readableStream = fs.createReadStream('classic_tale_of_true_love_and_high_adventure.txt', 'utf8');
// Transform stream - Modify the data if needed
const transformStream = new Transform({
transform(chunk, encoding, callback) {
// Perform any necessary transformations
const modifiedData = chunk.toString().toUpperCase(); // Placeholder for transformation logic
this.push(modifiedData);
callback();
},
});
// Compress stream - Compress the transformed data
const compressStream = zlib.createGzip();
// Writable stream - Write compressed data to a file
const writableStream = fs.createWriteStream('compressed-tale.gz');
// Pipe streams together
readableStream.pipe(transformStream).pipe(compressStream).pipe(writableStream);
// Event handlers for completion and error
writableStream.on('finish', () => {
console.log('Compression complete.');
});
writableStream.on('error', (err) => {
console.error('An error occurred during compression:', err);
});В этом фрагменте кода мы читаем файл, используя читаемый поток, преобразуем данные в верхний регистр и сжимаем их, используя два потока преобразования (один наш, один — встроенный поток преобразования zlib) и, наконец, записываем данные в файл, используя записываемый поток.
Мы создаем читаемый поток, используя fs.createReadStream() для чтения данных из входного файла. Поток преобразования создается с использованием класса Transform. Здесь вы можете реализовать любые необходимые преобразования данных (в этом примере мы снова использовали toUpperCase()). Затем мы создаем другой поток преобразования, используя zlib.createGzip() для сжатия преобразованных данных с использованием алгоритма сжатия Gzip. И, наконец, поток с возможностью записи создается с помощью fs.createWriteStream() для записи сжатых данных в файл compressed-tale.gz.
Метод .pipe() используется для последовательного соединения потоков. Мы начинаем с потока для чтения и направляем его в поток преобразования, который затем передается в поток сжатия, и, наконец, поток сжатия передается в поток для записи. Это позволяет установить оптимизированный поток данных из потока для чтения через потоки преобразования и сжатия в поток для записи. Наконец, к доступному для записи потоку присоединяются обработчики событий для finish и error событий.
Использование pipe() упрощает процесс соединения потоков, автоматически обрабатывает поток данных и обеспечивает эффективную и безошибочную передачу из потока для чтения в поток для записи. Он заботится об управлении базовыми событиями потока и распространением ошибок.
С другой стороны, прямое использование событий дает разработчикам более детальный контроль над потоком данных. Присоединив прослушиватели событий к читаемому потоку, вы можете выполнять пользовательские операции или преобразования полученных данных перед их записью в место назначения.
При принятии решения об использовании pipe() или событий необходимо учитывать следующие факторы.
- Простота: если вам нужна прямая передача данных без какой-либо дополнительной обработки или преобразования,
pipe()предлагает простое и лаконичное решение. - Гибкость: Если вам требуется больший контроль над потоком данных, например, изменение данных перед записью или выполнение определенных действий во время процесса, прямое использование событий дает вам гибкость для настройки поведения.
- Обработка ошибок: И
pipe(), и прослушиватели событий позволяют обрабатывать ошибки. Однако при использовании событий у вас больше контроля над обработкой ошибок, и вы можете реализовать пользовательскую логику обработки ошибок.
Важно выбрать подход, который лучше всего подходит для вашего конкретного случая использования. Для простой передачи данных, pipe() часто является предпочтительным выбором из-за его простоты и автоматической обработки ошибок. Однако, если вам требуется больше контроля или дополнительная обработка во время потока данных, непосредственное использование событий обеспечивает необходимую гибкость.
Рекомендации по работе с потоками Node.js
При работе с Node.js Streams важно следовать рекомендациям, чтобы обеспечить оптимальную производительность и удобство обслуживания кода.
- Обработка ошибок: потоки могут столкнуться с ошибками во время чтения, записи или преобразования. Важно обрабатывать эти ошибки, прослушивая событие
errorи предпринимая соответствующие действия, такие как запись ошибки в журнал или корректное завершение процесса. - Соответствующие метки максимального значения: метка максимального значения — это ограничение размера буфера, которое определяет, когда читаемый поток должен приостанавливать или возобновлять поток данных. Очень важно выбрать соответствующую максимальную отметку на основе доступной памяти и характера обрабатываемых данных. Это предотвращает переполнение памяти или ненужные паузы в потоке данных.
- Оптимизация использования памяти: поскольку потоки обрабатывают данные порциями, важно избегать ненужного потребления памяти. Всегда освобождайте ресурсы, когда они больше не нужны, например, закрывая файловые дескрипторы или сетевые подключения после завершения передачи данных.
- Использование утилиты потоков: Node.js предоставляет несколько служебных модулей, таких как
stream.pipeline()иstream.finished(), которые упрощают обработку потоков и обеспечивают правильную очистку. Эти утилиты управляют распространением ошибок, интеграцией промисов и автоматическим уничтожением потока, сокращая количество ручного стандартного кода (мы в Amplication всецело за минимизацию стандартного кода. - Создание механизмов управления потоком: когда доступный для записи поток не может идти в ногу со скоростью чтения данных из доступного для чтения потока, к тому времени, когда доступный для чтения поток закончит чтение, в буфере может остаться много данных. В некоторых сценариях это может даже превышать объем доступной памяти. Это называется противодавлением. Чтобы эффективно справляться с противодавлением, рассмотрите возможность реализации механизмов управления потоком, таких как использование методов
pause()иresume()или использование сторонних модулей, таких как pump или through2.
Придерживаясь этих рекомендаций, разработчики могут обеспечить эффективную обработку потоков, минимизировать использование ресурсов и создавать надежные и масштабируемые приложения.
Заключение
Потоки Node.js — это мощная функция, которая обеспечивает эффективную обработку потока данных без блокировки. Используя потоки, разработчики могут обрабатывать большие наборы данных, обрабатывать данные в реальном времени и выполнять операции с эффективным использованием памяти. Понимание различных типов потоков, таких как Readable, Writable, Duplex и Transform, а также соблюдение рекомендаций обеспечивает оптимальную обработку потоков, управление ошибками и использование ресурсов. Используя возможности потоков, разработчики могут создавать высокопроизводительные и масштабируемые приложения с помощью Node.js.
Я надеюсь, что вы нашли эту статью полезной. Спасибо!