Последние достижения в области ИИ с открытым исходным кодом от лаборатории Tongyi Lab компании Alibaba: FunAudioLLM

В то время как OpenAI не спешит выпускать своего голосового помощника GPT-4o, другие модели генерации звука появляются одна за другой, и, что важно, они с открытым исходным кодом.
Недавно лаборатория Tongyi Lab компании Alibaba сделала значительный шаг, запустив FunAudioLLM, проект речевой модели с открытым исходным кодом, включающий две модели: SenseVoice и CosyVoice.
SenseVoice специализируется на высокоточном распознавании многоязычной речи, распознавании эмоций и определении аудиособытий, поддерживая более 50 языков. Она превосходит Whisper по точности, особенно в китайском и кантонском языках, с улучшением более чем на 50%.
Она отлично справляется с распознаванием эмоций и может определять такие распространенные события человеко-машинного взаимодействия, как музыка, аплодисменты, смех, плач, кашель и чихание, достигая самых высоких результатов в различных тестах.
CosyVoice специализируется на генерации естественной речи, поддерживая несколько языков, тонов и эмоциональный контроль. Она может генерировать голоса на китайском, английском, японском, кантонском и корейском языках, значительно превосходя традиционные модели генерации речи.
Используя всего 3-10 секунд исходного аудио, CosyVoice может смоделировать голос, включая ритм и эмоции, даже при генерации межъязыковой речи.
CosyVoice также поддерживает тонкий контроль над эмоциями и ритмом генерируемой речи с помощью насыщенного текста или естественного языка, что значительно повышает эмоциональную выразительность аудио.
Давайте рассмотрим возможности использования и демонстрации FunAudioLLM.
Многоязычный перевод, передающий тон и эмоции
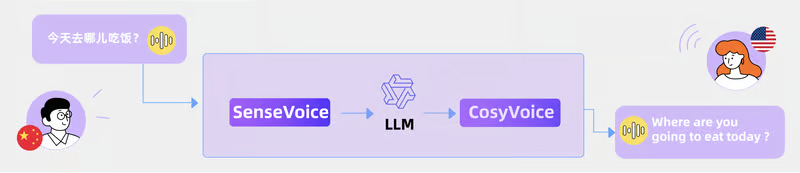
Объединив SenseVoice, LLM и CosyVoice, мы можем беспрепятственно выполнять перевод с речи на речь (S2ST). Этот комплексный подход не только повышает эффективность и беглость перевода, но и позволяет улавливать эмоции и тональность оригинальной речи, воспроизводя эти эмоциональные нюансы в переведенной речи, что делает диалог более аутентичным и увлекательным.
Будь то устный перевод на многоязычных конференциях, межкультурная коммуникация или предоставление услуг мгновенного голосового перевода для людей, не являющихся носителями языка, эта технология значительно снижает языковые барьеры и потери при общении.
Эмоционально насыщенное голосовое взаимодействие
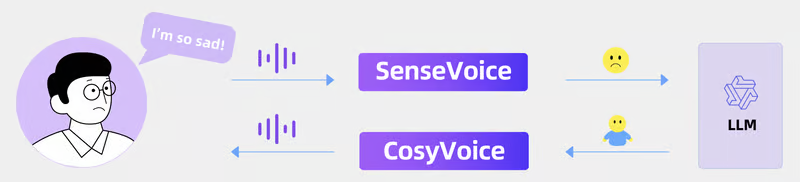
Интеграция SenseVoice, больших языковых моделей (LLM) и CosyVoice позволяет разработать эмоциональное приложение для голосового чата. Когда SenseVoice обнаруживает эмоции, настроения или другую паралингвистическую информацию, например кашель, LLM генерирует соответствующие эмоциональные реакции. Затем CosyVoice синтезирует соответствующий эмоциональный тон, создавая комфортное и естественное разговорное взаимодействие.
Интерактивный подкаст
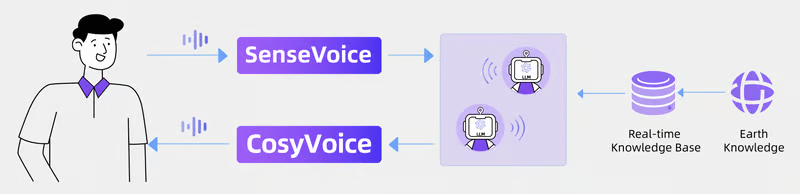
Интегрировав SenseVoice, мультиагентную систему на основе LLM, обладающую знаниями о мире в реальном времени, и CosyVoice, мы можем создать интерактивную подкаст-станцию. SenseVoice записывает разговоры в реальном времени между ИИ-подкастерами и пользователями, распознавая даже окружающие звуки и эмоции. Пользователи могут в любой момент прервать ИИ-подкастера, чтобы направить дискуссию в другое русло. CosyVoice генерирует голоса ИИ-подкастеров с возможностью управления несколькими языками, тонами и эмоциями, предлагая слушателям богатый и разнообразный слуховой опыт.
Аудиокниги
Используя аналитические возможности LLM для структурирования содержания книги и выявления эмоций, в сочетании с синтезом речи CosyVoice, мы можем создавать очень выразительные аудиокниги. LLM глубоко понимают текст, улавливая каждый эмоциональный нюанс и сюжетную линию, а CosyVoice преобразует эти эмоции в речь с особыми эмоциональными тонами и акцентами. Это обеспечивает слушателям богатый и эмоционально захватывающий опыт, превращая аудиокниги в эмоциональный и яркий слуховой праздник.
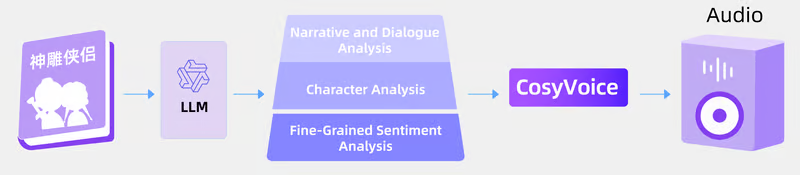
Принцип работы FunAudioLLM
CosyVoice
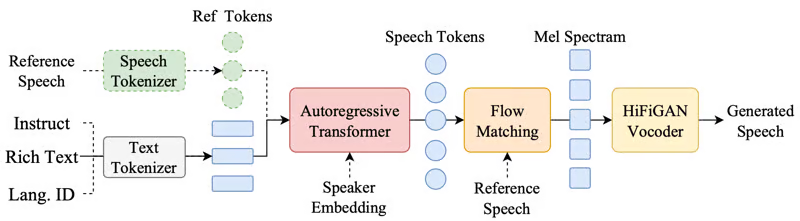
CosyVoice — это большая модель генерации речи, основанная на квантовом кодировании речи. Она дискретизирует речь и использует технологию больших моделей для достижения естественной и плавной генерации речи. По сравнению с традиционными технологиями генерации речи, CosyVoice превосходит их по естественности просодии и реалистичности тембра голоса. Она поддерживает до пяти языков и позволяет тонко управлять эмоциями и другими параметрами генерируемой речи с помощью естественного языка или насыщенного текста.
Исследовательская группа предлагает базовую модель CosyVoice-300M, усовершенствованную версию CosyVoice-300M-SFT и модель с поддержкой тонкого управления CosyVoice-300M-Instruct, рассчитанную на различные случаи использования.
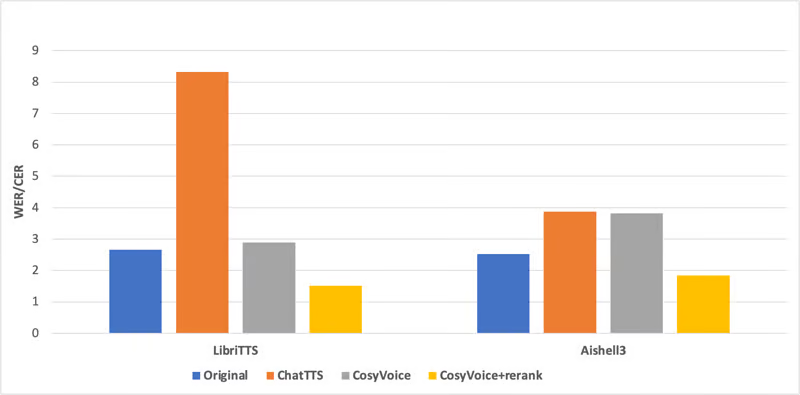
Объективные показатели сгенерированной речи
Исследовательская группа оценила согласованность содержания синтезированного аудио, используя открытый китайский набор данных Aishell3 и английский набор данных LibriTTS с помощью тестов распознавания речи.
Сравнение с оригинальным аудио и недавно популярным ChatTTS показало, что синтезированное CosyVoice аудио достигло более высокого уровня согласованности содержания и редко демонстрировало галлюцинации или феномены дополнительных слов.
CosyVoice эффективно моделирует семантическую информацию в синтезированном тексте, достигая уровня, сравнимого с человеческими дикторами. Кроме того, повторная оценка синтезированного аудио еще больше снизила количество ошибок распознавания, даже превзойдя человеческие показатели по согласованности содержания и сходству с диктором.
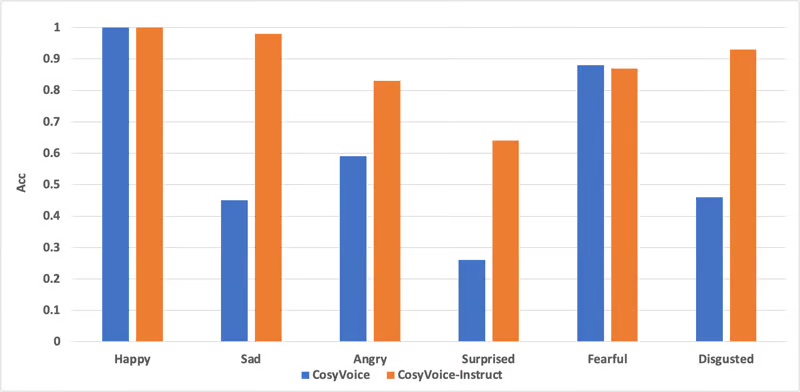
Способность к эмоциональному контролю
Исследовательская группа также оценила возможности CosyVoice по управлению эмоциями с помощью предварительно обученной модели классификации эмоций. Эта оценка была сосредоточена на пяти высокоэкспрессивных голосовых эмоциях: счастье, грусть, гнев, страх и отвращение.
Результаты тестирования показали, что CosyVoice-300M обладает способностью определять эмоции по содержанию текста. Модель CosyVoice-300M-Instruct, обученная с помощью тонкого контроля, получила более высокие результаты в классификации эмоций, продемонстрировав более сильную способность к эмоциональному контролю.
SenseVoice
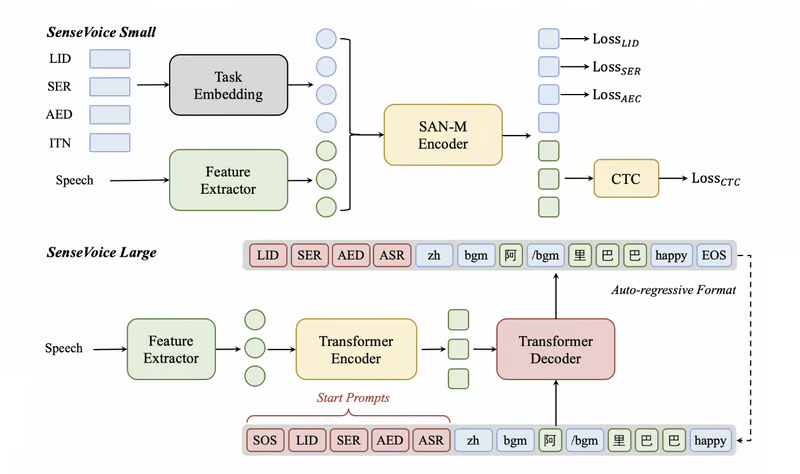
SenseVoice — это фундаментальная модель понимания речи с возможностями автоматического распознавания речи (ASR), идентификации языка (LID), распознавания настроения (SER) и обнаружения аудиособытий (AED). Она призвана обеспечить комплексные функции обработки речи для поддержки построения сложных систем речевого взаимодействия.
SenseVoice-Small — это легкая базовая модель речи, предназначенная для быстрого понимания речи и подходящая для чувствительных к задержкам приложений, таких как системы речевого взаимодействия в реальном времени.
SenseVoice-Large — это комплексная модель, ориентированная на более точное понимание речи, поддерживающая большее количество языков и подходящая для сценариев, требующих высокой точности распознавания.
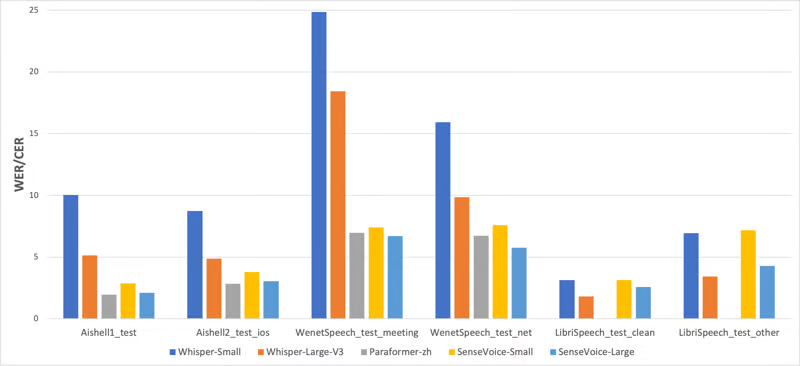
Эффективность распознавания многоязычной речи
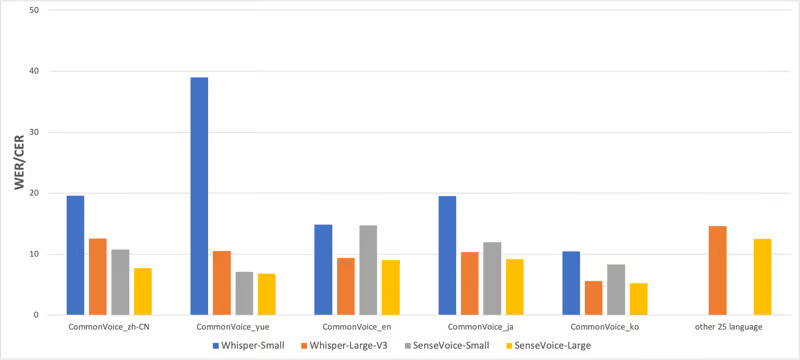
Исследовательская группа сравнила производительность многоязычного распознавания SenseVoice и Whisper и эффективность выводов на наборах данных с открытым исходным кодом, включая AISHELL-1, AISHELL-2, Wenetspeech, Librispeech и Common Voice.
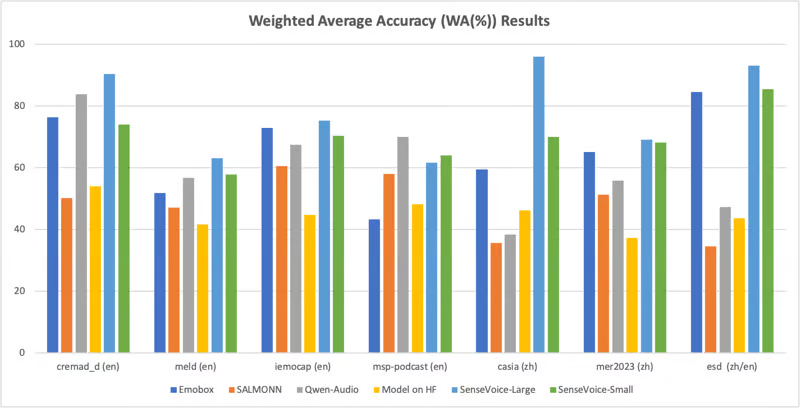
Эмоциональное распознавание речи
SenseVoice также может использоваться для распознавания дискретных эмоций, в настоящее время поддерживая такие эмоции, как счастье, грусть, гнев и нейтралитет. Оцениваемая на семи популярных наборах данных для распознавания эмоций, система SenseVoice-Large достигла или превзошла результаты SOTA даже без тонкой настройки на целевых массивах.
Эффективность обнаружения аудиособытий
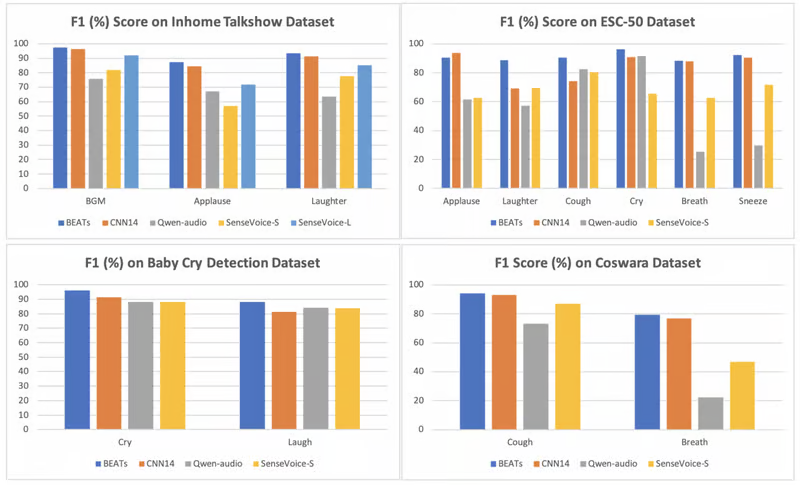
Как SenseVoice-Small, так и SenseVoice-Large могут определять звуковые события в речи, включая музыку, аплодисменты и смех. SenseVoice-Large также может точно определить время начала и окончания этих событий.
В настоящее время модели, связанные с SenseVoice и CosyVoice, находятся в открытом доступе на ModelScope и Huggingface, а соответствующие коды обучения, вывода и тонкой настройки опубликованы на GitHub.
Для получения более подробной информации изучите ссылки:
Благодарю за прочтение!