ChatGPT: Повышение качества информации из Интернета в реальном времени
Вчера мы смогли подключить наших ChatGPT ботов к Интернету. Эта функция все еще является экспериментальной, и она не всегда работает, но сегодня мы смогли устранить 90% ошибок, связанных с этим.
В этой статье я расскажу о некоторых наиболее важных вещах, которые мы сделали для достижения этой цели, и поделюсь своими выводами с остальным миром. Надеюсь, это будет полезно для других, пытающихся добиться того же.
Конечно, мы являемся магазином Hyperlambda, но вы, вероятно, сможете перенести наши идеи на свой язык программирования по своему выбору.
Попробуйте ChatGPT с доступом в Интернет
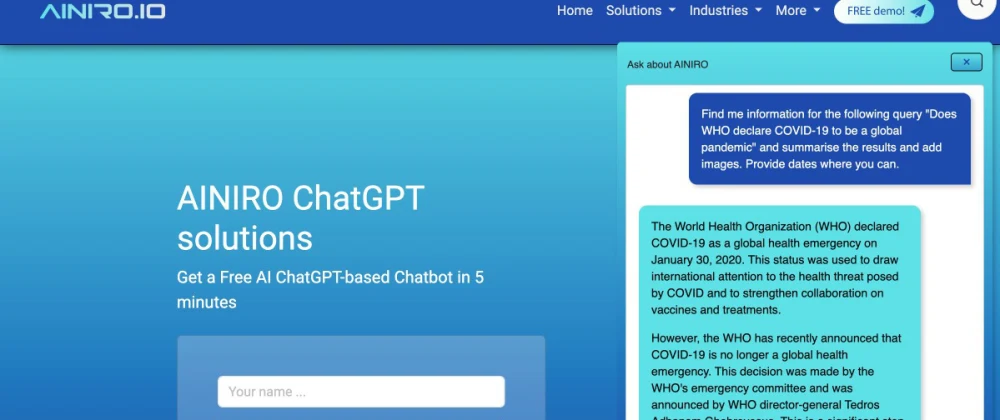
Прежде чем я начну объяснять, что мы сделали, сделайте мне одолжение. Нажмите на кнопку нашего чата в правом нижнем углу этой страницы и введите следующее;
Найдите мне информацию по следующему запросу "Объявляет ли "Всемирная организация здравоохранения" (ВОХ) COVID-19 пандемией в 2023 году?"
Дело в том, что вы получите от него что-то вроде следующего.
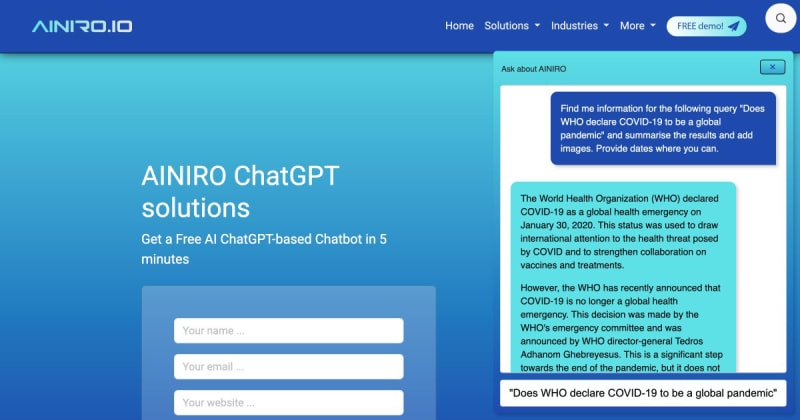
Я полагаю, что разница между приведенным выше ответом и тем, что вам отвечает ChatGPT, очевидна. Наш чат-бот может подключаться к Интернету с помощью DuckDuckGo и парсит полученные веб-сайты, что позволяет нам использовать ChatGPT для работы с информацией из Интернета в режиме реального времени. Обратите внимание, что он будет обращаться к Интернету только в том случае, если вы напишете свой запрос следующим образом;
Найди мне информацию по следующему запросу "QUERY_HERE"
Теперь, когда мы разобрались с семантикой, давайте рассмотрим некоторые вещи, которые нам пришлось сделать, чтобы повысить качество этого процесса. Изначально только от 40 до 50 процентов наших запросов были успешными, и ниже я объясню, почему и что мы сделали, чтобы увеличить это число более чем до 90%.
Парсинг сайта
У нас, вероятно, лучшая технология парсинга веб-страниц в отрасли, и мы многому научились, используя ее за последние 7 месяцев, сканируя десятки веб-сайтов каждый день благодаря бесплатному веб-чат-боту с искусственным интеллектом. Это дает нам уникальную возможность понять, как создавать высококачественные обучающие данные для ИИ с веб-сайтов и всевозможных источников. И вы будете удивлены, насколько большая часть «проблемы ИИ» связана со старой доброй разработкой программного обеспечения, с алгоритмами, архитектурой, композицией, дизайном программного обеспечения и простыми код.
Если вам нужен лучший ИИ, напишите лучший традиционный код 😉
Некоторые из наиболее важных выводов, сделанных нами в отношении парсинга веб-сайтов, заключаются в следующем.
Не все сайты можно парсить
Мы стараемся быть "добропорядочными гражданами". Под этим я подразумеваю, что мы четко идентифицируем наших пауков как парсеров веб-сайтов, используя уникальные идентифицируемые заголовки HTTP User-Agent, и мы стараемся уважать веб-сайты, чтобы не перегружать их, когда мы их парсим. Здесь можно проделать больше работы, но, по крайней мере, в отличие от большинства других, мы не "скрываем" тот факт, что парсим ваш сайт.
Однако не все веб-сайты допускают парсинг. Некоторые веб-сайты просто отключают все парсеры, которые они могут идентифицировать. У некоторых есть веб-брандмауэры, не позволяющие никому, кроме «людей», получить к ним доступ и парсить их — что создает для нас проблему, когда мы пытаемся получить любую информацию, которую мы можем найти на этих сайтах.
Способ, которым мы решаем эту проблему, заключается в вызове DuckDuckGo и извлечении 5 лучших совпадений для любого запроса, который ищет пользователь. Затем мы получаем все это параллельно с тайм-аутом 10 секунд. Почему тайм-аут? Потому что некоторые сайты «блокируют вас от получения данных, оставляя соединение сокета открытым», подразумевая, что они никогда не вернутся. Идея состоит в том, что если сайт не вернет свой HTML-код менее чем за 10 секунд, мы разорвем HTTP-соединение и просто проигнорируем этот URL-адрес.
Из 5 обращений от DuckDuckGo обычно блокируется 1 или менее. Поскольку мы извлекаем информацию параллельно, асинхронно с 5 URL-адресов, мы все равно будем получать «некоторую информацию с 2/3 веб-сайтов» в 98% случаев. И процесс в целом никогда не будет занимать более 10 секунд из-за нашего таймаута. Тайм-аут имеет решающее значение для нас, поскольку мы не сохраняем данные локально, а всегда извлекаем их по запросу, подразумевая, что 10 секунд на очистку веб-страниц превращаются в 10 дополнительных секунд на получение ответа от ChatGPT.
Ниже приведен основной код точки входа. Даже если вы не понимаете Hyperlambda, вы должны быть в состоянии понять общую идею и, возможно, перенести ее на выбранный вами язык программирования.
/*
* Slot that searches DuckDuckGo for [max] URLs matching the [query],
* for then to scrape each URL, and aggregating the result
* returning it back to caller as a single Markdown.
*/
slots.create:magic.http.duckduckgo-and-scrape
// Sanity checking invocation.
validators.mandatory:x:@.arguments/*/query
validators.string:x:@.arguments/*/query
min:3
max:250
validators.integer:x:@.arguments/*/max
min:1
max:10
// Searching DuckDuckGo for matches.
add:x:+
get-nodes:x:@.arguments/*
signal:magic.http.duckduckgo-search
// Building our execution object that fetches all URLs simultaneously in parallel.
.exe
// Waiting for all scraping operations to return.
join
for-each:x:@signal/*/result/*
// Dynamically contructing our lambda object.
.cur
fork
.reference
try
unwrap:x:+/*
signal:magic.http.scrape-url
url:x:@.reference/*/url
semantics:bool:true
.catch
log.error:Could not scrape URL
url:x:@.reference/*/url
message:x:@.arguments/*/message
// Adding URL and title as reference to currently iterated [fork].
unwrap:x:+/*/*
add:x:@.cur/*/fork/*/.reference
.
url:x:@.dp/#/*/url
title:x:@.dp/#/*/title
// Adding current thread to above [join].
add:x:@.exe/*/join
get-nodes:x:@.cur/*
// Executing [.exe] retrieving all URLs in parallel.
eval:x:@.exe
/*
* Iterating through each above result,
* returning result to caller.
*
* Notice, we only iterate through invocations that have result, and
* did not timeout by verifying [signal] slot has children.
*/
for-each:x:@.exe/*/join/*/fork
// Verifying currently iterated node has result, containing both prompt and completion.
if
exists:x:@.dp/#/*/try/*/signal/*/*/prompt/./*/completion
.lambda
// Adding primary return lambda to [return] below.
unwrap:x:+/*/*/*
add:x:../*/return
.
.
url:x:@.dp/#/*/.reference/*/url
title:x:@.dp/#/*/.reference/*/title
snippets
// Adding [snippets] to return below.
add:x:../*/return/0/-/*/snippets
get-nodes:x:@.dp/#/*/try/*/signal/*
// Returning result of invocation to caller.
returnОсновная идея заключается в следующем;
- Запрашиваем DuckDuckGo и парсим первые 5 URL-адресов.
- Создаем один асинхронный поток для каждого результата и извлекаем их из соответствующих URL-адресов с тайм-аутом 10 секунд.
- Дожидаемся завершения всех потоков и создаем агрегированный результат.
С этим связано гораздо больше кода, но, поскольку Magic является открытым исходным кодом, вы можете изучить его код для получения более подробной информации. Например, мы делаем все возможное, чтобы создать Markdown из полученного HTML. Это значительно сокращает объем данных, которые мы отправляем в ChatGPT, сохраняя при этом гиперссылки, изображения и списки в их семантической форме. Вот почему наш чат-бот может отображать изображения, гиперссылки и списки так, как он это делает. Этот простой факт увеличивает качество нашего чат-бота как минимум на 1 порядок.
Мы НЕ ВОРУЕМ вашу информацию
Одна вещь, которую мы делаем по-другому, заключается в том, что мы стараемся всегда предоставлять источник и ссылки нашим пользователям, если мы можем вписать их в контекст. Это означает, что он обычно заканчивает свое объяснение чем-то вроде «Эта информация была получена со следующих URL-адресов: abc, xyz».
Это, во-первых, вежливо, а во-вторых, позволяет нашим пользователям проверить, что говорят вам наши чат-боты. Конечным результатом становится то, что вместо «кражи трафика с вашего веб-сайта» мы, вероятно, вместо этого ДАЕМ вашему веб-сайту дополнительный трафик, поскольку пользователи, вероятно, захотят проверить свои запросы, прочитав источник, который нам предоставляет DuckDuckGo.
Заключение
Это трудно. Я помню, как мой бывший партнер сказал: «Почему я должен инвестировать в то, что любой может скопировать и украсть?» Что ж, пока что мы единственные в отрасли, способные делать то, что делаем сейчас. По сути, мы «на 10 лет опережаем конкурентов», и никто не может «скопировать нас» — хотя я делаю все возможное, чтобы помочь им копировать наши идеи каждый божий день, благодаря исключительно инновациям, открытым в публичном пространстве и лицензированию с открытым исходным кодом 99% каждой строки кода, который я пишу 😂
Ты был неправ, я был прав, проверь. 7 миллиардов 999 миллионов 999 тысяч и еще 999 впереди 😂
Псс, попробуйте наши чат-боты с искусственным интеллектом здесь