Создание платформы на базе Kubernetes: основные компоненты, решения и антипаттерны
Kubernetes был широко принят в качестве менеджера контейнеров и уже несколько лет работает в различных организациях . Таким образом, он обеспечивает прочную основу для поддержки трех других возможностей собственной облачной платформы: прогрессивной доставки, управления границами и наблюдаемости. Эти возможности могут быть предоставлены, соответственно, с помощью следующих технологий: конвейеры непрерывной доставки, стек ребер и стек наблюдаемости.
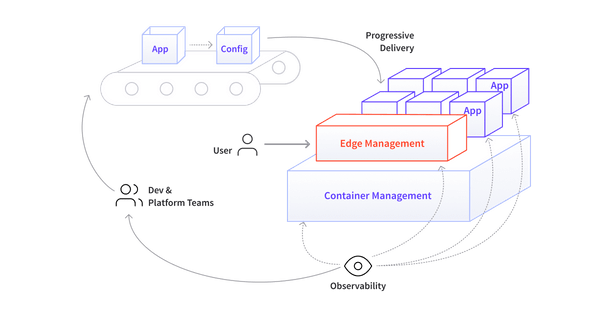
Практически каждый поставщик облачных решений для частного облака поддерживают развертывание и эксплуатацию инфраструктуры контейнерной оркестровки Kubernetes. С момента первоначального выпуска Kubernetes компанией Google в 2014 году вокруг этой платформы сформировалось большое сообщество, часто при поддержке организации, которая сейчас является руководителем проекта, Cloud Native Computing Foundation (CNCF) .
Начиная с Kubernetes, давайте рассмотрим, как каждая из этих технологий интегрируется для обеспечения основных возможностей облачной платформы.
Kubernetes
Вслед за ранним успехом Docker , контейнеры стали стандартным элементом («артефактом») развертывания облаков. Приложения, написанные на любом языке, могут быть созданы, упакованы и «герметично» запечатаны в образе контейнера. Эти контейнеры могут быть развернуты и запущены везде, где поддерживается формат изображения контейнера. Это облачная реализация популярной концепции разработки программного обеспечения «пиши один раз, беги куда угодно», за исключением того, что теперь написание кода было заменено созданием и упаковкой этого кода.
Рост популярности контейнеров можно объяснить тремя факторами: контейнеры требуют меньше ресурсов для запуска, чем виртуальные машины (с компромиссом для общего ядра операционной системы); формат манифеста Dockerfile предоставил разработчикам отличную абстракцию для определения «достаточно» конфигурации сборки и развертывания; Docker впервые разработал простой метод для разработчиков, позволяющий собирать приложения в режиме самообслуживания ( сборка Docker ), и позволил легко обмениваться и искать приложения в контейнерах через общие реестры и общедоступный Docker Hub .
Сами контейнеры, хотя и являются мощной абстракцией, не решают проблем эксплуатации, таких как перезапуск и перепланирование при сбое основного оборудования. Для этого требуется структура оркестровки контейнера. Что-то вроде Kubernetes.
Циклы управления и общие абстракции
Kubernetes позволяет командам разработчиков работать в режиме самообслуживания в отношении операционных аспектов работы контейнеров. Например, определение зондов готовности и готовности приложения и указание требований к ресурсам времени выполнения, таких как ЦП и память. Затем эта конфигурация анализируется циклом управления в среде Kubernetes, который прилагает все усилия, чтобы убедиться, что спецификации разработчика соответствуют фактическому состоянию кластера. Оперативные группы также могут определять глобальные политики доступа и развертывания, используя веб-справочники управления доступом на основе ролей (RBAC) и допуска . Это помогает ограничить доступ и направлять группы разработчиков к передовым методам развертывания приложений.
Помимо предоставления среды выполнения и оркестровки контейнера, Kubernetes позволяет и разработчикам, и команде платформы взаимодействовать, совместно использовать и совместно использовать стандартизированный рабочий процесс и набор инструментов. Он делает это с помощью нескольких основных абстракций: контейнер как единица развертывания, модуль как компонент конфигурации среды выполнения (объединение контейнеров и определение политик развертывания, перезапуска и повторных попыток) и сервис как высокоуровневые, ориентированные на бизнес компоненты приложения.
Kubernetes как услуга или самообслуживание
Сам Kubernetes представляет собой сложную структуру для развертывания, эксплуатации и обслуживания. Поэтому основное решение при принятии этой платформы - использовать размещенное предложение, такое как Google GKE , Amazon EKS или Azure AKS , или самостоятельно управлять этим с помощью инструментов администрирования, таких как kops и kubeadm.

Вторым важным решением является то, какое распределение («дистрибутив») Kubernetes использовать. В исходном дистрибутиве Kubernetes с открытым исходным кодом по умолчанию предоставляются все основные функции. Неудивительно, что поставщики облачных услуг часто расширяют свои дистрибутивы, чтобы упростить интеграцию с окружающей их экосистемой. Другие поставщики платформ, такие как Red Hat , Rancher или Pivotal, предлагают дистрибутивы, которые эффективно работают на многих облачных платформах, а также включают различные улучшения. Как правило, дополнительные функции сконцентрированы на поддержке корпоративных сценариев использования с упором на безопасность, гомогенизированные рабочие процессы, а также на предоставление комплексных пользовательских интерфейсов (UI) и панелей администратора.
Документация Kubernetes предоставляет дополнительную информацию, чтобы помочь с этим выбором.
Избежание антипаттерн платформы
Основные абстракции разработки, предоставляемые Kubernetes, - контейнеры, модули и службы - облегчают взаимодействие между группами разработки и эксплуатации и помогают предотвратить разрозненное владение. Эти абстракции также снижают вероятность того, что разработчики должны взять вещи в свои руки и начать создавать «микроплатформы» внутри самой системы.
Kubernetes также может быть развернут локально, что на ранних этапах внедрения может помочь в решении проблемы медленной или ограниченной обратной связи с разработчиками. По мере роста использования Kubernetes в организации они могут использовать множество инструментов для решения задачи локальной и удаленной разработки. Такие инструменты, как Telepresence , Skaffold , Tilt и Garden, предоставляют разработчикам механизмы , позволяющие защитить цикл обратной связи от кодирования (возможно, от удаленных зависимостей), построения и проверки.
Конвейер непрерывной доставки
Основной мотивацией непрерывной доставки является внесение любых и всех изменений приложений - включая эксперименты, новые функции, конфигурацию и исправления ошибок - в производство так быстро и безопасно, как этого требует организация. Этот подход основан на идее, что возможность быстрой итерации обеспечивает конкурентное преимущество. Развертывание приложений должно быть рутинным и свободным от драматизма мероприятием, инициируемым по требованию и безопасно ориентированными на продукт командами разработчиков, и организация должна быть в состоянии постоянно внедрять инновации и вносить изменения устойчивым образом.
Улучшение обратной связи
Прогрессивная доставка расширяет подход непрерывной доставки, стремясь улучшить цикл обратной связи для разработчиков. Использование преимуществ собственных механизмов управления трафиком в облаке и усовершенствованных инструментов наблюдения позволяет разработчикам легче проводить контролируемые эксперименты на производстве, просматривать результаты практически в реальном времени с помощью панелей мониторинга и при необходимости принимать корректирующие меры.
Успешная реализация как непрерывной, так и прогрессивной доставки зависит от того, смогут ли разработчики определять, модифицировать и поддерживать конвейеры, которые кодифицируют все утверждения сборки, качества и безопасности. Основные решения, которые необходимо принять при принятии нативного облачного подхода, основаны главным образом на двух факторах: сколько у существующей инфраструктуры непрерывной доставки есть в организации; и уровень проверки, необходимый для артефактов приложения.
Развитие подхода организации к непрерывной доставке
Организации с большими инвестициями в существующие инструменты непрерывной доставки обычно неохотно уходят от этого. Jenkins можно встретить во многих корпоративных средах, и рабочие команды часто тратят много времени и энергии на понимание этого инструмента. Несмотря на то, что этот инструмент сборки до облачных вычислений можно адаптировать к новым требованиям, существует также дополнительный нативный проект облака, Jenkins X , в который встроена поддержка основных концепций прогрессивной доставки . Расширяемость Jenkins, к лучшему или к худшему, позволила создать множество плагинов. Есть плагины для выполнения анализа качества кода, сканирования безопасности и автоматического выполнения теста. Существуют также широкие интеграции с инструментами анализа качества, такими как SonarQube , Veracode и Fortify .

Организации с ограниченными существующими инвестициями в инструментальные средства непрерывной доставки часто предпочитают использовать собственные облачные опции, такие как Harness , CircleCI или Travis . Эти инструменты направлены на обеспечение простой настройки и выполнения самообслуживания для разработчиков.Однако некоторые из них не так расширяемы, как инструменты, которые развертываются и управляются локально, и предоставляемые функциональные возможности часто ориентированы на создание артефактов, а не на их развертывание. Операционные группы также обычно имеют меньшую видимость в конвейере. По этой причине многие группы разделяют автоматизацию сборки и развертывания и используют платформы непрерывной доставки, такие как Spinnaker, для организации этих действий.
Избежание антипаттерн платформы
Инфраструктура непрерывной доставки часто является мостом между разработкой и эксплуатацией. Это может быть использовано для решения традиционных проблем изолированного владения кодом и времени выполнения. Например, команды платформ могут работать с командами разработчиков для предоставления пакетов сборки кода и шаблонов, которые могут смягчить воздействие подхода «один размер подходит всем», а также устранить соблазн для разработчиков создавать свои собственные решения.
Непрерывная доставка также важна для улучшения обратной связи с разработчиками. Быстрый конвейер, который развертывает приложения, готовые к тестированию в производственной среде, уменьшит необходимость переключения контекста. Шаблоны развертывания и базовая конфигурация также могут быть добавлены в конвейер, чтобы включить общие требования наблюдаемости для всех приложений, например, для сбора журналов или метрических отправителей. Это может в значительной степени помочь разработчикам получить и понять производственные системы, а также помочь с проблемами отладки без необходимости полагаться на оперативную группу для предоставления доступа.
Краевой Стек
Основные цели, связанные с использованием эффективной границы центра обработки данных, которая в современной конфигурации облачной платформы часто является границей кластера Kubernetes, имеют три цели:
- Включение контролируемого выпуска приложений и новых функций;
- Поддержка конфигурации межфункциональных пограничных требований, таких как безопасность (аутентификация, безопасность на транспортном уровне и защита от DDoS) и надежность (ограничение скорости, разрыв цепи и тайм-ауты);
- Поддержка разработки и использования соответствующих API.
Отдельный выпуск от развертывания
В настоящее время наилучшей практикой в рамках облачной доставки собственного программного обеспечения является разделение развертывания и выпуска. Конвейер непрерывной доставки обрабатывает сборку, проверку и развертывание приложения. "Освобождение" происходит, когда изменение функции с предполагаемым влиянием на бизнес становится доступным для конечных пользователей. Используя такие методы, как запуски dark и выпуски canary, изменения можно чаще развертывать в производственных средах без риска крупномасштабного негативного воздействия на пользователей.
Более частые итеративные развертывания снижают риск, связанный с изменениями, а разработчики и заинтересованные стороны сохраняют контроль над выпуском функций конечным пользователям.
Масштабирование пограничных операций с самообслуживанием
Внутри облачной системы, которая создается с помощью микросервисов, необходимо эффективно решать задачи масштабирования операций на периферии и поддержки нескольких архитектур . Настройка границв должна быть самостоятельной как для разработчиков, быстро выполняющих итерации в рамках одного сервиса или API, так и для команды платформы, работающей в глобальном масштабе системы. Стек пограничных технологий должен предлагать всестороннюю поддержку для ряда протоколов, архитектурных стилей и моделей взаимодействия, которые обычно встречаются в языковом стеке полиглотов.
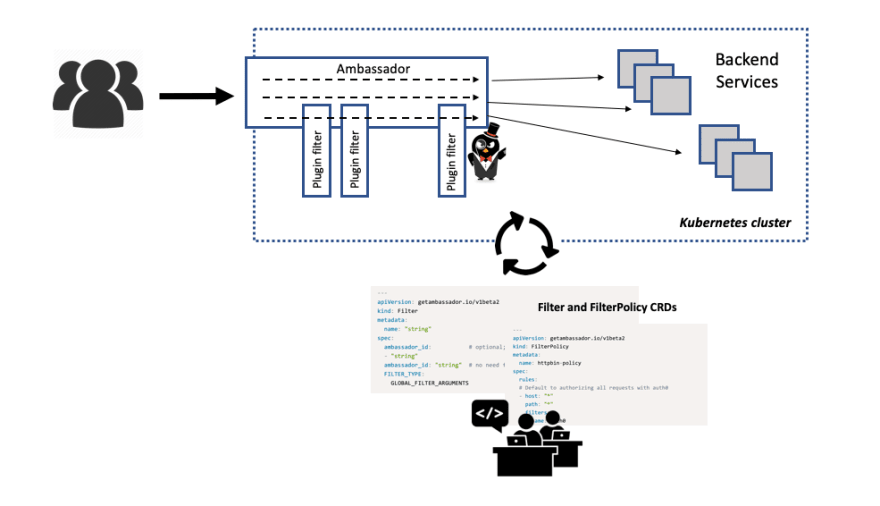
Избежание антипаттерн платформы
Прошли те времена, когда каждый API, представленный в системе, основывался на SOAP или REST. Благодаря целому ряду протоколов и стандартов, таких как WebSockets , gRPC и CloudEvents , больше не может быть подхода «один размер подходит всем». Теперь настольные ставки для всех частей пограничного стека изначально поддерживают несколько протоколов.
Край системы Kubernetes - это еще одна ключевая точка сотрудничества для разработчиков платформ. Команды платформ хотят уменьшить фрагментацию за счет централизации основных функций, таких как аутентификация и авторизация. Разработчики хотят избежать необходимости подавать заявки на настройку и выпуск служб в рамках своего обычного рабочего процесса, поскольку это только добавляет трения и сокращает время цикла доставки функциональности конечным пользователям.
Стек наблюдаемости
Концепция « наблюдаемости » возникла из математической теории управления и является мерой того, насколько хорошо внутренние состояния системы могут быть выведены из знания ее внешних результатов. Современные интерпретации наблюдаемости программного обеспечения развивались почти одновременно с ростом нативных облачных систем; наблюдаемость в этом контексте сфокусирована на способности выводить то, что происходит в программной системе, используя такие подходы, как мониторинг, ведение журнала и отслеживание.
Как популяризируется в книге Google SRE, учитывая, что индикатор уровня обслуживания (SLI) является индикатором некоторого аспекта "здоровья", о котором будут заботиться потребители системы (что часто указывается через SLO), есть две фундаментальные цели с наблюдаемостью:
- Постепенное улучшение SLI (возможно, оптимизация в течение дней, недель, месяцев)
- Быстрое восстановление SLI (немедленное реагирование на инцидент)
Исходя из этого, существует два основных действия, которые должен обеспечить стек наблюдаемости: обнаружение, то есть способность точно измерять SLI; и уточнение, которое является способностью уменьшить пространство поиска для правдоподобных объяснений проблемы.
Понятность, проверяемость и отладка
С целями улучшения или восстановления SLI тесно связаны дополнительные мотивы поддержки наблюдаемости в программной системе: понятность, возможность проверки и возможность отладки. Поскольку программные системы стали широко распространенными и критически важными для всего общества, потребность в их понимании и аудите резко возросла. Люди медленно доверяют тому, чего не могут понять. И если система, как полагают, действовала неправильно, или кто-то утверждает, что она это сделала, то возможность просмотреть отчет о проверке и доказать или опровергнуть это неоценимо.
Принятие облачных нативных технологий и архитектур, к сожалению, усложнило реализацию наблюдаемости. Понимание распределенной системы по своей сути сложнее при работе в масштабе. А существующие инструменты не поддерживают эффективную отладку высокомодульной системы, взаимодействующей по ненадежным сетям. Требуется новый подход к созданию собственного стека наблюдаемости облака.
Три столпа наблюдаемости: одно решение
Мыслители в этом современном пространстве наблюдаемости, такие как Синди Шридхарен , Чарити Мейджорс и Бен Сигельман , написали несколько замечательных статей, в которых представлены «три столпа» нативной наблюдаемости облака - мониторинг, регистрация и распределенное отслеживание. Тем не менее, они также предупредили, что эти столбы не следует рассматривать изолированно. Вместо этого следует искать целостное решение.
Мониторинг в собственном облачном пространстве обычно осуществляется через приложение Prometheus, размещенное в CNCF, или аналогичное коммерческое предложение. Метрики часто генерируются через контейнеризованные приложения, использующие протокол statsd или языковую библиотеку Prometheus. Использование метрик дает хорошее представление о приложении и платформе моментального снимка во времени, а также может использоваться для запуска оповещения.
Ведение журнала обычно отправляется в виде событий из контейнерных приложений через общий интерфейс, такой как STDOUT, или через SDK для ведения журнала, включенный в приложение. Популярные инструменты включают Elasticsearch , Logstash и Kibana стек (ELK) . Fluentd , размещенный в CNCF проект, часто используется вместо Logstash. Регистрация полезна, когда задним числом пытается понять, что произошло в приложении, и может также использоваться для целей аудита.

Распределенная трассировка обычно реализуется с использованием OpenZipkin или инструмента Jaegar, размещенного на CNCF , или коммерческого эквивалента. Трассировка - это, по сути, форма регистрации событий на основе событий, которая содержит некоторую форму идентификатора корреляции, которая может использоваться для объединения событий из нескольких служб, связанных с запросом одного конечного пользователя. Это обеспечивает сквозное понимание запросов и может использоваться для идентификации проблемных служб в системе (например, скрытых служб) или для понимания того, как запрос проходил через систему, чтобы удовлетворить требования соответствующего пользователя.
Многие из принципов парадигмы сетки данных применимы к наблюдаемой теме. Инженеры платформы должны предоставить ряд инструментов доступа к данным и API-интерфейсов для разработчиков, чтобы разработчики могли использовать их для самообслуживания.
Избежание антипаттерн платформы
В облачной наблюдаемости отсутствует подход «один размер подходит всем».Хотя процесс передачи и сбора данных о наблюдаемости должен быть стандартизирован, чтобы избежать фрагментации платформы, способность к самообслуживанию при определении и анализе метрик конкретных приложений и служб жизненно важна для разработчиков, чтобы иметь возможность отслеживать работоспособность или исправлять что-то, когда происходят неизбежные сбои. Распространенным антипаттерном, встречающимся в организациях, является требование подать заявку, чтобы отслеживать конкретные метрики или включить их в информационную панель. Это полностью противоречит принципу включения быстрого цикла разработки, что особенно важно при запуске новой функциональности или при возникновении производственного инцидента.
Резюме и заключение
Kubernetes получил широкое распространение и уже несколько лет работает в различных организациях. Таким образом, он обеспечивает прочную основу для поддержки трех других возможностей собственной облачной платформы, обеспечивающей полный цикл разработки. Эти возможности могут быть обеспечены, соответственно, с помощью следующих технологий: конвейер непрерывной доставки, краевой стек и стек наблюдаемости.
Инвестирование в эти технологии и соответствующие рабочие процессы, основанные на передовом опыте, ускорит путь организации к осознанию преимуществ от использования принципов облачного и полного цикла разработки.