Задача сверхвысокого разрешения для одного изображения

Цель этой мини-задачи - увеличить разрешение отдельного изображения (в четыре раза). Данные для этой задачи взяты из набора данных DIV2K [1]. Для этой задачи мы подготовили мини-набор данных, который состоит из 500 обучающих и 80 проверочных пар изображений, где изображения HR имеют разрешение 2K, а изображения LR субдискретизированы в четыре раза.
Для каждого изображения LR алгоритмы увеличат разрешение изображений. Качество вывода будет оцениваться на основе PSNR между выводом и изображениями HR. Идея состоит в том, чтобы позволить алгоритму выявить больше деталей, незаметных на изображении LR.
Предварительная обработка данных
Набор данных DIV2K [1] состоит из 500 обучающих и 80 проверочных пар изображений, где изображения HR имеют разрешение 2K, а изображения LR подвергаются понижающей дискретизации в четыре раза. Хотя DIV2K имеет изображения с высоким разрешением, обучающие патчи обычно небольшие. Если вы читаете все изображение целиком, используя только очень маленькую его часть, это будет напрасно. Чтобы увеличить скорость ввода-вывода во время обучения, изображения с разрешением 2K можно обрезать до под-изображений (480x480 под-изображений) с помощью скрипта extract_subimages.py из кодовой базы BasicSR [2]
Увеличение данных
Совместные разнообразные методы увеличения могут использоваться для частичного блокирования или сбивания с толку обучающего сигнала, чтобы модель приобрела большую обобщающую способность. Производительность можно еще больше повысить, применив несколько тщательно отобранных методов увеличения данных на этапе обучения.
Cutout
Cutout [2] может стирать (обнулять) случайно выбранные пиксели с вероятностью α. Вырезанные пиксели отбрасываются при вычислении потерь путем маскирования удаленных пикселей. При настройке по умолчанию, отбрасывание 25% пикселей прямоугольной формы может ухудшить исходную производительность. Однако это даст положительный эффект при применении с соотношением 0,1% и стиранием случайных пикселей вместо прямоугольной области.
CutMix и Mixup
CutMix [3] может заменить случайно выбранную область квадратной формы на фрагмент из другого изображения. Mixup [4] может смешивать два случайно выбранных изображения. CutMix можно соединить с изображением Mixuped.
CutBlur
CutBlur [5] вырезает фрагмент с низким разрешением и вставляет его в соответствующую область изображения с высоким разрешением и наоборот. Имея частично LR и частично HR распределения пикселей со случайным соотношением в одном изображении, CutBlur пользуется эффектом регуляризации, побуждая модель изучать и «how», и «where» для сверхразрешения изображения. Поступая таким образом, модель может понять, «how much», вместо того, чтобы слепо учиться применять сверхвысокое разрешение к каждому заданному пикселю.
Flip and Rotate
Произвольный поворот по горизонтали, вертикали и поворот на 90, 180, 270 градусов для увеличения объема данных.
Перестановка RGB
Перестановка RGB заключается в случайном изменении каналов RGB, которые не вызывают каких-либо структурных изменений в изображении.
Модельная архитектура
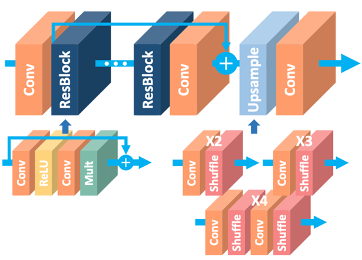
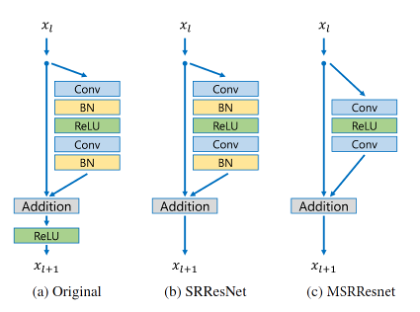
Магистралью сети является MSRResNet, которая модифицирована из EDSR [6], как показано на рисунке 2. Из рисунка 3 видно, что по сравнению с ResNet [7], SRResNet [8], уровни пакетной нормализации удалены из сети. Поскольку уровни пакетной нормализации нормализуют функции, они избавляют сети от гибкости диапазона за счет нормализации функций, и поэтому их лучше удалить. После удаления этого шага сеть может складывать больше сетевых уровней или извлекать больше функций из каждого уровня в рамках тех же вычислительных проблемных ресурсов с лучшей производительностью. Сеть использует потерянную функцию L1 нормы для оптимизации сетевой модели. При обучении сначала обучается модель выборки с малым увеличением, а затем параметры модели выборки с низким увеличением мощности обучаются для инициализации модели выборки с высоким увеличением,
Сетевая архитектура состоит из нескольких остаточных блоков. По умолчанию количество остаточных блоков равно 16, и его увеличивают до 20, чтобы создать более глубокую модель в рамках ограничения параметра. В каждом блоке res за сверточным слоем 3x3 следуют слой BN и слой Relu. Leaky Relu наносится после первого сверточного слоя и соединяет последние четыре сверточных слоя. Он вводит обучаемый параметр, который помогает адаптивно запоминать некоторые отрицательные коэффициенты.
Функция потерь
Функция потерь сохраняется с использованием функции потерь L1, поскольку она уже обсуждалась в [8], которая доказывает, что потеря L1 обеспечивает лучшую сходимость, чем L2.
Измененные параметры и гиперпараметры
(1) num_block установлен от 16 до 20
Номер блока увеличен на 20, чтобы получить более глубокую модель. В результате параметр модели увеличен с 1 517 571 до 1812 995.
(2) total_iter устанавливается в одну десятую от оригинала от 1 000 000 до 100 000
Общее количество итераций для обучения сокращено для более быстрого обучения.
(3) периоды скорости обучения устанавливаются в одну десятую от оригинала от [250000, 250000, 250000, 250000] до [25000, 25000, 25000, 25000]
Косинусный отжиг - это тип графика скорости обучения, который имеет эффект начала с большой скорости обучения, которая относительно быстро снижается до минимального значения, а затем снова быстро увеличивается. Поскольку total_iter устанавливается в одну десятую от оригинала, периоды отжига косинуса также должны быть установлены на одну десятую от оригинала.
Результат
PSNR модели в наборе данных проверки и количество параметров модели. показаны в Таблице 1 ниже.

Заключение
Подводя итог, можно сказать, что модель MSRResNet воспроизводится, а производительность матрицы оценки PSNR улучшается за счет применения совместного дополнения данных и более глубокой модели