10 быстрых трюков Pandas для активизации вашего аналитического проекта

Pandas - это популярная библиотека анализа данных на Python. Это, безусловно, обеспечивает вам гибкость и инструменты, необходимые для обработки данных.
Однако для эффективной работы вы должны знать простые в использовании приемы, позволяющие сэкономить время. Поэтому мы рассмотрим 10 быстрых, но очень полезных трюков в pandas, которые вы можете освоить менее чем за 10 минут.
Даже если вы уже хорошо разбираетесь в методах и функциях pandas, вы все равно найдете некоторые из этих приемов действенными. Если вы абсолютный новичок, то эта статья - подходящее место для начала вашего обучения.
Вот краткий указатель для справки:
- Регулирование количества столбцов или строк для отображения
- Произвольная выборка строк с помощью
sample() - Подмножество фрейма данных с помощью метода
query() - Округление значений в фрейме данных pandas с помощью функции
round() - Распаковка значений списка с помощью метода
explode() - Создание быстрых графиков с помощью метода
plot() - Возвращение нескольких фреймов данных с
display() - Подсчет уникальных значений с помощью
nunique() - Возвращение совокупной сводки с помощью
cumsum() - Агрегирование по нескольким функциям с помощью
agg()
Для примера мы будем использовать Airbnb Open Data, которыми вы можете воспользоваться бесплатно, поскольку они общедоступны по ODbL Licence.
Не забудьте взять блокнот Jupyter со всеми примерами в конце этого чтения.
Задача анализа данных начинается с импорта набора данных в pandas DataFrame, и требуемый набор данных часто доступен в формате .csv.
Однако, когда вы читаете csv-файл с большим количеством столбцов в фрейме данных pandas, вы можете увидеть только несколько имен столбцов, за которыми следует . . . . . и еще несколько имен столбцов, как показано ниже.
import pandas as pd
df = pd.read_csv("Airbnb_Open_Data.csv")
df.head()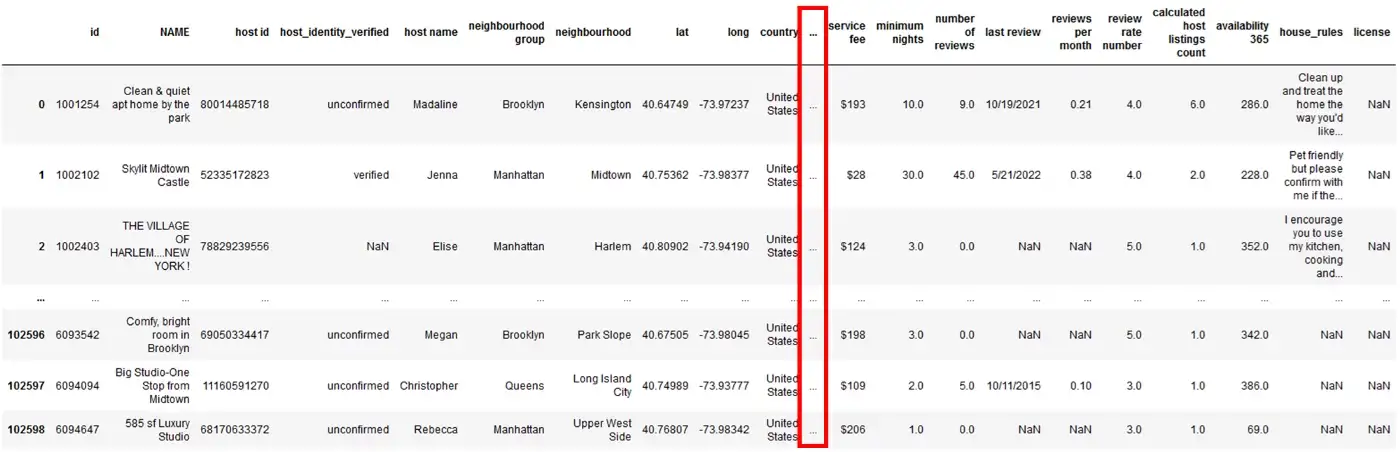
Основная цель .head() состоит в том, чтобы незаметно заглянуть в данные. С такими скрытыми именами столбцов за . . . . ., вы слепы к данным в этих столбцах. Итак, первый трюк здесь заключается в том, чтобы зафиксировать количество столбцов и строк, которые вы хотели бы отобразить.
Регулирование количества столбцов или строк для отображения
Pandas по умолчанию отображает на вашем экране только 60 строк и 20 столбцов. Это может быть причиной того, что за несколькими столбцами можно спрятаться . . . . ..
Вы можете проверить это ограничение самостоятельно, используя параметры отображения pandas, как показано ниже.
pd.options.display.max_rows
#Output
60
pd.options.display.max_columns
#Output
20Вы можете использовать точно такие же параметры, чтобы задать максимальное количество строк и столбцов, которые будут отображаться на экране.
Например, вы можете установить максимальное количество столбцов равным 30, как показано ниже.
pd.options.display.max_columns = 30
df = pd.read_csv("Airbnb_Open_Data.csv")
df.head()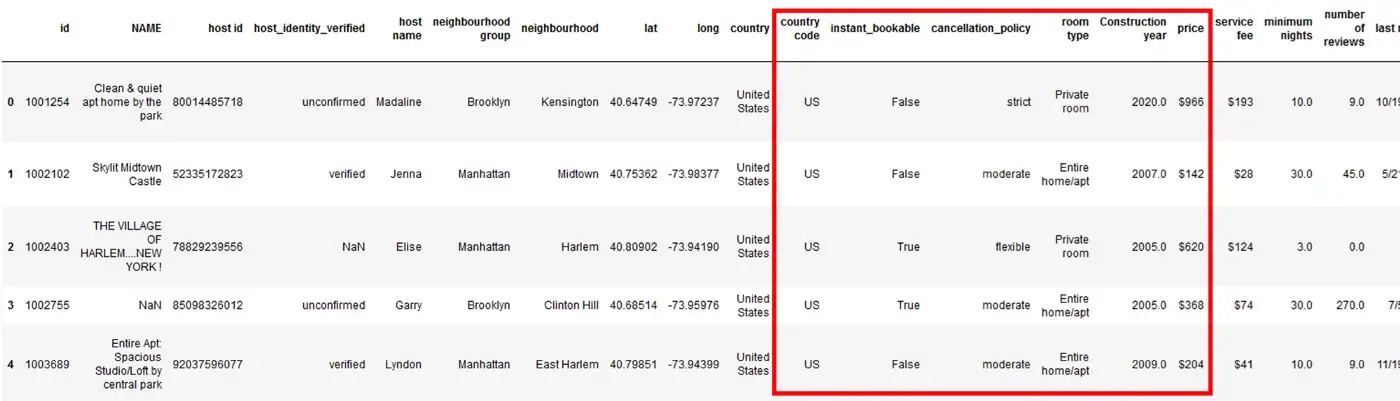
На рисунке выше вы можете увидеть все столбцы в наборе данных. Столбцы в красном поле ранее были скрыты за . . . . .. и не были видны в выходных данных.
Кроме того, вы можете вернуть параметру значение по умолчанию, используя функцию .reset_option(), как показано ниже.
pd.reset_option('display.max_rows')
pd.options.display.max_rows
#Output
60Когда вы изменяете несколько параметров по умолчанию в pandas, вы можете сбросить все параметры обратно к исходным значениям в одном операторе, используя аргумент ‘all’ в функции .reset_options().
Чтобы заглянуть в набор данных, вы можете использовать методы .head() или .tail(). Это ограничивает вас возможностью просмотра только первых/последних нескольких строк. В pandas вы всегда можете проверить данные из любой случайно выбранной записи или даже подмножество данных с помощью случайного выбора.
Случайная выборка строк с помощью sample()
Данные могут выглядеть хорошо организованными и чистыми с первых или последних нескольких строк. Таким образом, всегда полезно взглянуть на любые случайные записи в наборе данных, чтобы лучше его понять.
pandas.DataFrame.sample предлагает гибкость для случайного выбора любой записи из набора данных с 7 необязательными и настраиваемыми параметрами.
Например, предположим, что вы хотели бы выбрать 4 случайные записи из набора данных Airbnb. Вы можете просто ввести — df.sample(4)— чтобы получить приведенный ниже результат.

В качестве альтернативы вы также можете использовать fraction, чтобы указать, какую часть всего набора данных вы хотите выбрать случайным образом. Просто назначьте долю (меньше 1) параметру frac в функции sample(), как показано ниже.
df.sample(frac = 0.00005)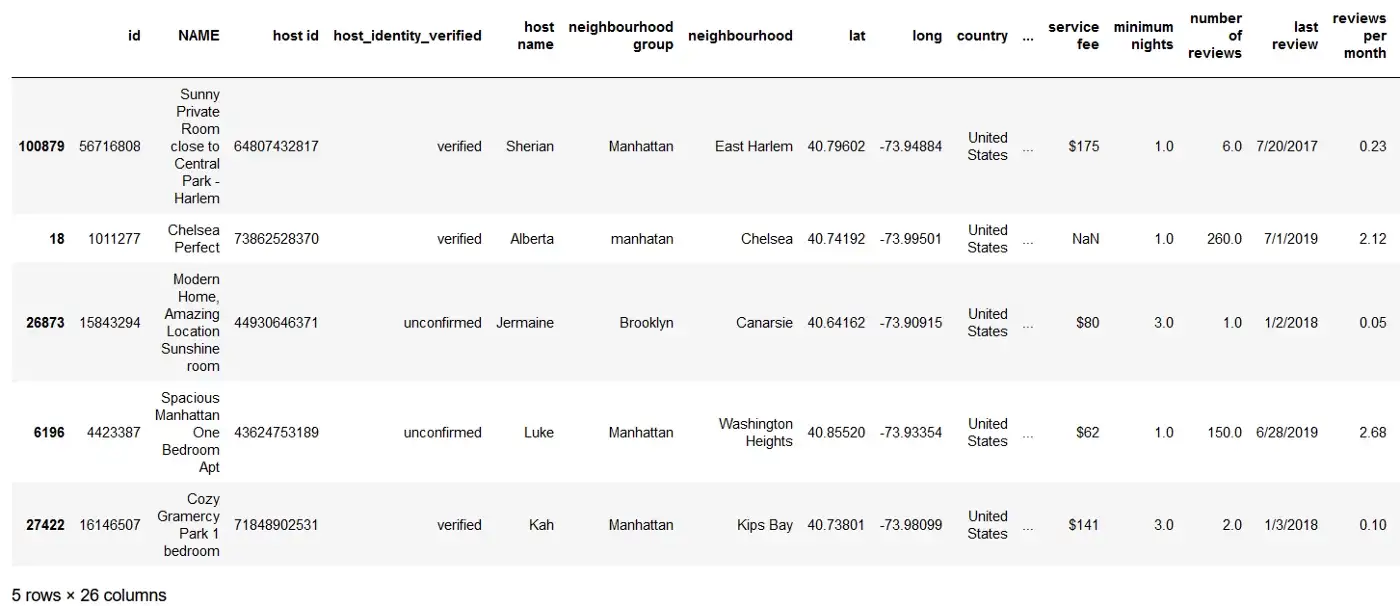
Здесь вы просто извлекли 0,005% от общего количества строк в DataFrame.
Однако записи выбираются случайным образом каждый раз, когда вы выполняете эту ячейку. Итак, чтобы получать один и тот же результат каждый раз, вы можете установить параметру random state значение любого целого числа.
Предположим, вы хотели бы каждый раз извлекать одни и те же три строки, тогда вы можете использовать функцию sample(), как показано ниже.
df.sample(3, random_state = 4)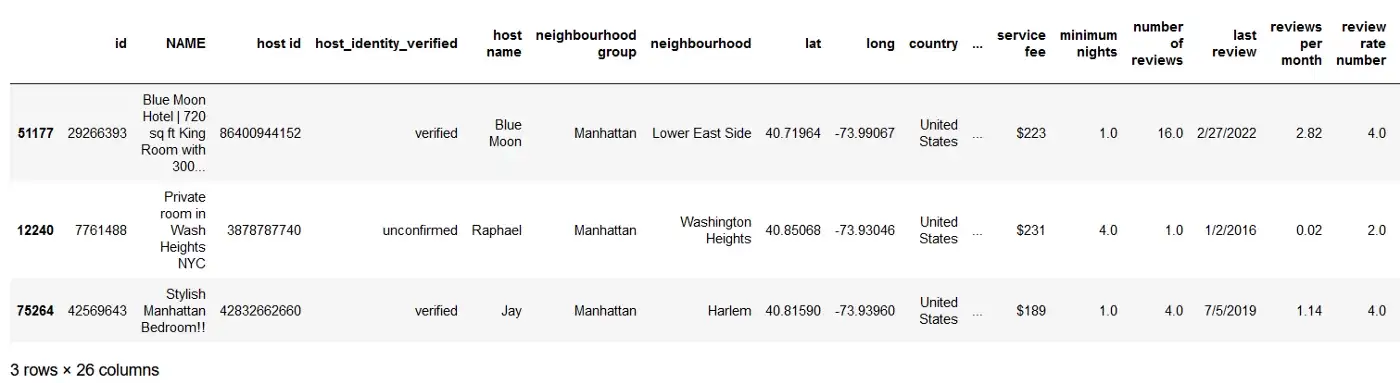
Если вы хотите выбрать разные записи, вы можете просто изменить параметр random_state на другое целое число.
Как только вы проверите данные, доступные в наборе данных, следующей задачей будет выбор требуемого подмножества набора данных. Конечно, вы можете использовать .loc и методы .iloc, за которыми следует ряд квадратных скобок для извлечения выбранных строк и столбцов.
Но есть еще один способ .query(), который может помочь вам избавиться от нескольких открывающих и закрывающих квадратных скобок для подмножества фрейма данных.
Подмножество фрейма данных с помощью метода query()
Функция pandas.DataFrame.query(expression) предлагает вам гибкость для условного выбора подмножества фрейма данных. Выражение, предоставляемое в рамках этой функции, представляет собой комбинацию одного или нескольких условий. Вы можете написать это абсолютно простым способом без каких-либо квадратных скобок.
Например, предположим, что вы хотите извлечь все записи из набора данных, где соседством является Кенсингтон. Используя метод query(), это довольно просто, как показано ниже.
df.query("neighbourhood == 'Kensington'")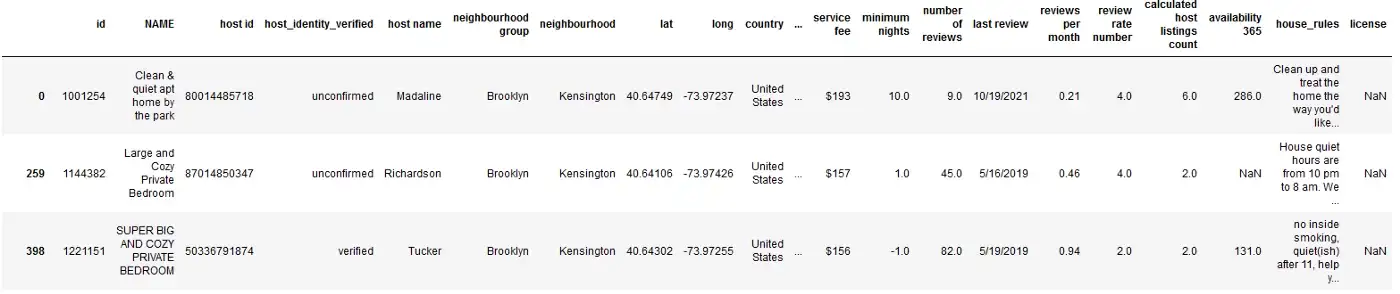
Вы также можете использовать несколько условий в одном столбце и любую логику, такую как AND, OR, NOT между ними.
После выбора подмножества вы перейдете к этапу очистки данных в аналитике. Одна из распространенных проблем с числовыми столбцами заключается в том, что они содержат больше требуемого количества цифр после десятичной точки. Давайте посмотрим, как вы можете справиться с такими столбцами.
Округление значений в фрейме данных pandas с помощью функции round()
Иногда числовые данные в столбце содержат несколько цифр после запятой, и лучше ограничить их до 2-3 цифр.
В таких случаях может очень пригодиться метод pandas.DataFrame.round. Все, что вам нужно сделать, это указать необходимое количество цифр в методе, как показано ниже.
df.round(2)
В наборе данных Airbnb только столбцы lat и long содержат значения с 5 цифрами после запятой. Метод фрейма данных round() просто округляет количество цифр для всех столбцов в наборе данных.
Но предположим, вы хотите округлить количество цифр только для одного столбца — lat — в этом наборе данных. Метод pandas.Series.round может быть полезен в таком сценарии, как показано ниже.
df['lat'].round(2)
#Output
0 40.65
1 40.75
2 40.81
...
102596 40.68
102597 40.75
102598 40.77
Name: lat, Length: 102599, dtype: float64Вывод pandas.Series.round - это снова серия. Чтобы использовать его как часть того же фрейма данных, вам необходимо повторно назначить измененный столбец исходному столбцу, как показано ниже.
df['lat'] = df['lat'].round(2)
df.head()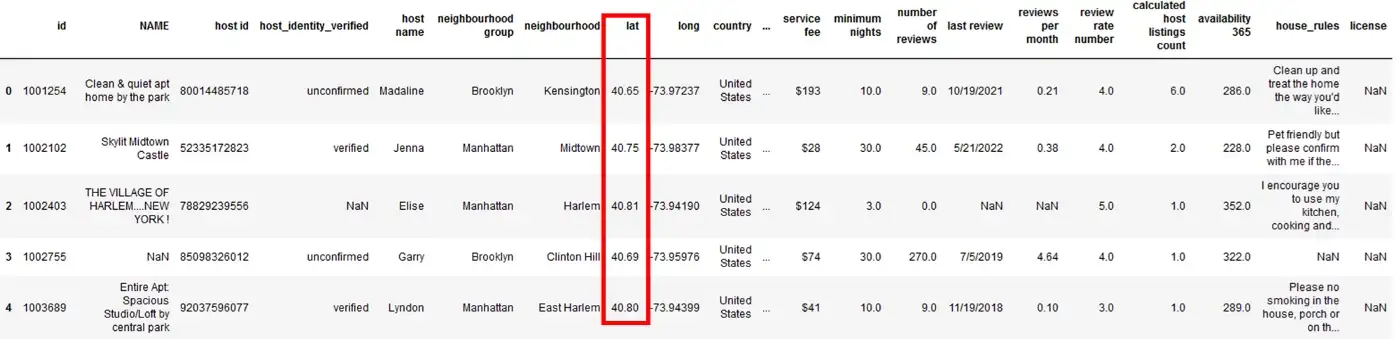
Он изменил только значения в столбце lat на 2 цифры после запятой, в то время как значения в столбце long остаются неизменными.
Продолжая манипулировать данными столбца, давайте рассмотрим другой метод explode(), который имеет более конкретный вариант использования — для преобразования каждого элемента списка значений в отдельную строку.
Распаковка значений списка с помощью метода explode()
Иногда вы сталкиваетесь с набором данных, где значения в столбце представляют собой списки. В долгосрочной перспективе трудно иметь дело с такими значениями, и всегда лучше создавать одну строку для каждого значения списка.
Чтобы лучше понять эту концепцию, давайте создадим фрейм данных.
df = pd.DataFrame({"Country":["India","Germany"],
"State":[["Maharashtra", "Telangana", "Gujarat"],
["Bavaria", "Hessen"]]})
df
Состояние столбца в приведенном выше фрейме данных содержит список в качестве значения. Чтобы получить одну строку для каждого значения в каждом столбце списка состояний, вы можете использовать метод pandas.DataFrame.explode, как показано ниже.
df.explode("State")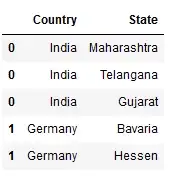
Все, что вам нужно сделать, это указать имя столбца, содержащего списки, в качестве его значений в explode(). Вы можете заметить, что в приведенном выше выводе он просто воспроизвел значения индекса для каждого элемента в списке.
Обычной задачей после очистки данных является визуализация данных. Диаграммы и графики позволяют легко определить основные тенденции, закономерности и корреляции.
Когда вы используете pandas для анализа данных, вам не нужно импортировать какую-либо другую библиотеку для создания диаграмм. pandas имеет свои собственные методы и гибкие опции для быстрого создания разнообразных диаграмм.
Создание быстрых графиков с помощью метода plot()
Часто целью вашей аналитической задачи является не визуализация данных, а то, что вы хотите увидеть простые диаграммы из ваших данных. Pandas - это настолько гибкий пакет, что он позволяет вам визуализировать содержимое фрейма данных, используя свои собственные методы.
Предположим, вы хотели бы увидеть среднее количество отзывов для каждого типа номера. Вы можете достичь этого с помощью метода pandas.DataFrame.plot, который создает графики серии или фрейма данных.
Вы можете создать меньший и более простой фрейм данных — df_room — только с обязательными двумя столбцами, как мы сделали здесь.
df_room = pd.DataFrame(df.groupby('room type')['number of reviews'].mean())
df_room.reset_index(drop=False, inplace=True)
display(df_room)
df_room.plot(x='room type', y='number of reviews', kind='bar')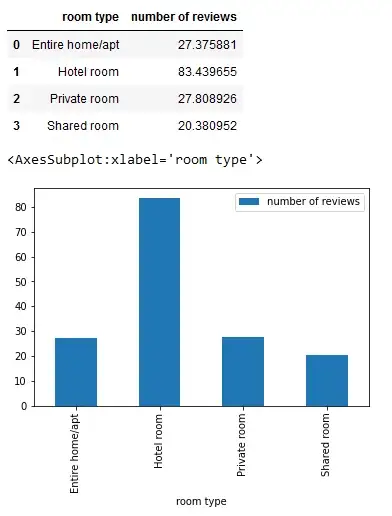
Оба — вновь созданный фрейм данных и диаграмма — отображаются в выходных данных.
Вы всегда можете изменить тип диаграммы с гистограммы на линейку, используя параметр kind в .plot().
Но как pandas создала столбчатую диаграмму без каких-либо данных о стиле диаграммы?
pandas.DataFrame.plot использует серверную часть, указанную параметром plotting.backend. Серверная часть построения графиков - это библиотека построения графиков, которую pandas использует для создания диаграмм, и она использует matplotlib в качестве библиотеки по умолчанию.
Вы можете изменить его в любое время, установив pd.options.plotting.backend или используя опцию pd.set_option(‘plotting_backend’, ‘name_of_backend’).
Возвращаясь к работе с фреймами данных в целом, давайте посмотрим, как вы можете отображать несколько фреймов данных одновременно.
Возвращение нескольких фреймов данных с помощью display()
Часто вы создаете несколько фреймов данных, но когда вы упоминаете их имена или используете для них метод .head()/.tail() в одной ячейке, в выходных данных отображается только последний фрейм данных.
Для примера давайте создадим два фрейма данных и попытаемся просмотреть их в выходных данных.
df1 = pd.DataFrame({"Country":["India","Germany"],
"State":[["Maharashtra", "Telangana", "Gujarat"],
["Bavaria", "Hessen"]]})
df2 = df1.explode("State")
# Get both DataFrames as output
df1
df2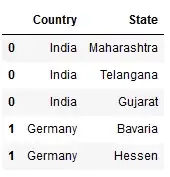
Хотя вы упомянули df1 и df2 в конце своего кода; в выходных данных отображался только df2.
Но вы хотите видеть оба фрейма данных, один под другим. Вот где полезна функция display(). Вам нужно только передать фрейм данных функции display(), как показано ниже.
df1 = pd.DataFrame({"Country":["India","Germany"],
"State":[["Maharashtra", "Telangana", "Gujarat"],
["Bavaria", "Hessen"]]})
df2 = df1.explode("State")
# Get both DataFrames as output
display(df1)
display(df2)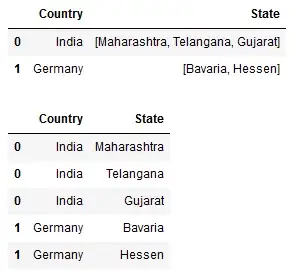
Теперь вы можете видеть оба (или все) DataFrames в выходных данных, расположенных один поверх другого.
Предыдущий трюк также является хорошим примером функции display(), где вы можете увидеть фрейм данных и столбчатую диаграмму, наложенные друг на друга в выходных данных.
Как только вы изучите набор данных и исследуете тенденции, закономерности в нем, следующим шагом будет проведение описательного анализа. Это может быть достигнуто с помощью преобразования данных.
Начнем с одного из базовых преобразований данных — для исследования различных значений в категориальных столбцах с использованием различных встроенных функций.
Подсчет уникальных значений с помощью unique()
Когда у вас есть категориальные столбцы в наборе данных, вам иногда нужно проверить, сколько различных значений присутствует в столбце.
Вы можете получить его с помощью простейшей функции —nunique(). Например, предположим, что вы хотели бы посмотреть, сколько различных типов комнат имеется в наборе данных, вы можете быстро проверить это с помощью nunique().
df['room type'].nunique()
#Output
4Ну, это говорит вам только о том, сколько уникальных значений доступно, но для получения разных значений, т.е. типа комнат, вы можете использовать другую функцию — unique()
df['room type'].unique()
#Output
array(['Private room', 'Entire home/apt', 'Shared room', 'Hotel room'],
dtype=object)Он возвращает массив со всеми уникальными значениями.
После проверки уникальных значений было бы также интересно проверить, сколько раз каждое значение появлялось в наборе данных, т.е. сколько раз каждый тип комнаты записывался в наборе данных.
Вы можете получить его с помощью другого метода — value_counts() — как показано ниже.
df.value_counts('room type')
#Output
room type
Entire home/apt 53701
Private room 46556
Shared room 2226
Hotel room 116Таким образом, вы можете получить количество уникальных значений и количество раз, когда они появлялись, используя одну строку кода.
Преобразование данных никогда не ограничивается категориальными столбцами, фактически большая часть полезной информации получается из числовых столбцов.
Следовательно, давайте рассмотрим две обычно необходимые операции, связанные с числовыми столбцами. Первое, что нужно сделать, это посмотреть, как вы можете получить совокупную сводку по столбцу в DataFrame.
Возвращение совокупной сводки с помощью cumsum()
Накопительные суммы также называются текущими итогами, которые используются для отображения общей суммы данных по мере ее увеличения со временем. Таким образом, в любой момент времени он сообщает вам общее количество всех значений до этого момента.
pandas DataFrame имеет свой собственный метод pandas.DataFrame.cumsum, который возвращает совокупную сумму столбца DataFrame.
Давайте создадим простой фрейм данных с датами и количеством проданных товаров.
daterange = pd.date_range('2022-11-24', periods=5, freq='2D')
df1 = pd.DataFrame({ 'Date': daterange,
'Products_sold' : [10, 15, 20, 25, 4]})
df1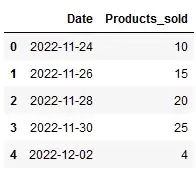
Это фиктивный набор данных, который имеет диапазон дат с 24.11.2022 по 02.12.2022 и соответствующее количество продуктов, проданных на каждую дату.
Теперь предположим, что вы хотите увидеть общее количество товаров, проданных до 30.11.2022. Вам не нужно вычислять его вручную, скорее используйте метод pandas.DataFrame.cumsum получит это для вас всего за одну строку кода.
df1["Products_sold"].cumsum()
#Output
0 10
1 25
2 45
3 70
4 74Он просто вернул текущий итог по определенному столбцу. Но это трудно понять, так как вы не видите никаких дат или исходных значений в выходных данных.
Поэтому вам следует назначить накопительную сумму новому столбцу в том же фрейме данных, как показано здесь.
df1["Total_products_sold"] = df1["Products_sold"].cumsum()
df1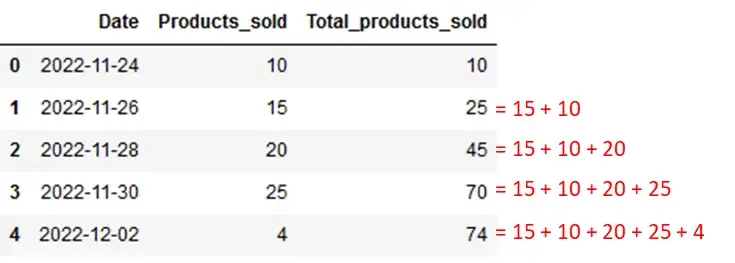
Вы получили общий объем вашего столбца всего в одной строке кода!
Обычно наблюдаемые варианты использования кумулятивной суммы заключаются в том, чтобы понять, «сколько до сих пор», например:
- Насколько повысился уровень воды в реке до сих пор
- Сколько продаж, продуктов продано до определенного времени
- Какой остаток остается на счете после каждой транзакции
Таким образом, знание того, как получить cumsum в вашем наборе данных, может стать настоящим спасением в вашем аналитическом проекте.
Кроме того, при работе с числовыми данными вы должны знать, как вы можете агрегировать данные и представлять их в сводной форме.
Агрегирование несколькими функциями с помощью agg()
Вы всегда можете объединить необработанные данные, чтобы представить статистические данные, такие как минимум, максимум, сумма и количество. Но вам действительно не нужно делать это вручную, когда вы используете pandas для анализа данных.
Pandas предлагает функцию — agg() — которая может быть использована для объекта pandas DataFrame groupby. Этот объект создается, когда метод DataFrame groupby() используется для группировки данных по категориям.
Используя функцию agg(), вы можете применить агрегатную функцию ко всем числовым столбцам в наборе данных.
Например, вы можете сгруппировать набор данных Airbnb по типу комнаты, чтобы создать объект pandas.DataFrame.groupby.
df_room = df.groupby('room type')
df_room
#Output
<pandas.core.groupby.generic.DataFrameGroupBy object at 0x0000029860741EB0>Теперь вы можете применить агрегатную функцию — sum — к столбцам number of reviews и minimum nights, как показано ниже.
df_room.agg({'number of reviews': sum,
'minimum nights': sum})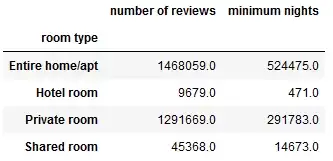
Все, что вам нужно сделать, это передать словарь функции agg(), в котором ключами являются имена столбцов, а значениями - имена агрегированных функций, такие как sum, max, min.
Вы также можете применить несколько функций к одному столбцу или даже разные функции к разным столбцам.