10 малоизвестных концепций и приемов визуализации Python
Добавьте в свой арсенал исследовательского анализа данных

Введение
Визуализация — это операция, при которой мы описываем наши данные в различных визуальных формах от диаграмм, графиков до инфографики. Это одна из наиболее важных частей исследовательского анализа данных (EDA), поскольку она позволяет нам легко понять отношения между переменными и любые уникальные характеристики данных, которые будут полезны для разработки признаков и моделирования на более поздних этапах. В этой статье я познакомлю вас с 10 концепциями и приемами визуализации Python, которые были менее известны, но могут быть полезны для добавления их в ваш арсенал визуализаций!
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
df = pd.read_csv(“../input/mall-customers/Mall_Customers.csv”)
df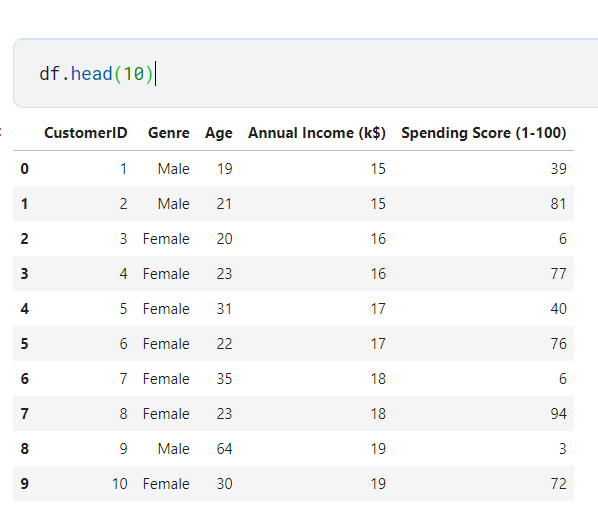
Это набор данных о клиентах торгового центра, который содержит 5 переменных: идентификатор клиента, жанр, возраст, годовой доход (тыс. $) и показатель расходов (1–100).
Мы переименовали столбец «Genre» в «Sex» для удобства.
df.rename(columns={'Genre':'Sex'}, inplace=True)Использование стилей
Matplotlib в Python позволяет нам назначать определенные стили, которые будут использоваться для наших визуализаций. Эти стили делают наши визуализации более доступными и легкими для чтения и интерпретации, а также иногда добавляют к ним эстетические оттенки, чтобы они были более убедительными для зрителей. Ниже приведен список стилей, которые вы можете использовать.
['seaborn-deep',
'seaborn-muted',
'bmh',
'seaborn-white',
'dark_background',
'seaborn-notebook',
'seaborn-darkgrid',
'grayscale',
'seaborn-paper',
'seaborn-talk',
'seaborn-bright',
'classic',
'seaborn-colorblind',
'seaborn-ticks',
'ggplot',
'seaborn',
'_classic_test',
'fivethirtyeight',
'seaborn-dark-palette',
'seaborn-dark',
'seaborn-whitegrid',
'seaborn-pastel',
'seaborn-poster']Вы можете просто запустить следующий код перед тем, как начнете создавать свои визуализации:
plt.style.use("fivethirtyeight")Установка и обновление параметров
Иногда бывает сложно задавать параметры для каждой отдельной визуализации, которую вы делаете, и вы хотели бы иметь набор параметров, определенный для всех визуализаций, которые вы делаете. В этом случае вы можете использовать метод rcParams из matplotlib.
# Setting figure size using matplotlib.pyplot's rcParams method
plt.rcParams['figure.figsize'] = (16, 9)
# Setting linewidth of line graph
import matplotlib as mpl
mpl.rcParams['lines.linewidth'] = 2
##and other settings are available too
##https://matplotlib.org/stable/tutorials/introductory/customizing.htmlВы также можете установить параметры или настройки с помощью метода set Seaborn.
# Another way to set figure size using seaborn's set method
sns.set(rc={'figure.figsize':(10,8)})Мы можем использовать метод pylab из matplotlib для обновления параметров.
import matplotlib.pylab as pylab
# Specify various parameters you want to overwrite/update with
params = {'legend.fontsize': 'large',
'figure.figsize': (16,9),
'axes.labelsize': 'x-large',
'axes.titlesize':'small',
'xtick.labelsize':'medium',
'ytick.labelsize':'x-large'}
pylab.rcParams.update(params)Обратите внимание, что есть 7 различных параметров, которые вы можете использовать для указания размера, как вы можете видеть из следующего:
Size: {'xx-small', 'x-small', 'small', 'medium', 'large', 'x-large', 'xx-large'}Кольцевая диаграмма (Donut Plot)
Это хороший график для визуализации пропорций различных категорий.Это более эффективно, когда вы добавляете аннотации к фактическому значению пропорции для каждой части, поскольку части с похожими пропорциями может быть трудно отличить друг от друга.
size = df['Sex'].value_counts()
colors = ['pink', 'lightblue']
labels = "Male", "Female"
explode = [0.05, 0.03] # It specifies the fraction of the radius with which to offset each wedge for each portion. In this case, we only have two categories and so we specify two values.
# first argument specifies the location of circle center and the second argument specifies the size of the radius. We set color to be white so that the center of the circle becomes empty and hence the name "donut" plot.
donut = plt.Circle((0,0), 0.6, color = 'white')
# The autopct argument allows us to add annotations of proportion values to each portion of the donut plot
plt.pie(size, colors = colors, labels = labels, shadow = True, explode = explode, autopct = '%.2f%%')
plt.title('Distribution of Gender', fontsize = 20)
p = plt.gcf()
p.gca().add_artist(donut)
plt.legend()
plt.show()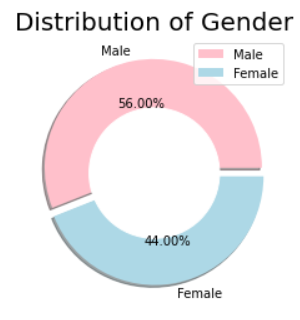
Роевая диаграмма (Swarm Plot)
Swarm Plot — это тип визуализации, который позволяет нам визуализировать распределение значений для каждой категории. Это может быть более полезным, чем другие типы визуализации, такие как диаграммы, из-за его детального отображения (т.е. отображается значение каждой точки данных), как вы можете видеть ниже. Недостатком этого является то, что если имеется слишком много точек данных с одинаковыми диапазонами значений, визуализация может выглядеть слишком сгруппированной и создать трудности при интерпретации визуализации. Я бы рекомендовал использовать его для наборов данных, которые не слишком велики.
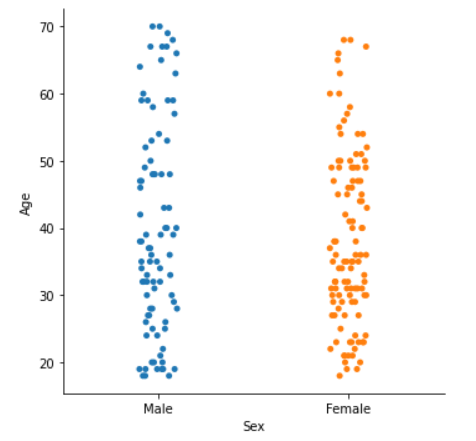
Вы можете создать роевую диаграмму выше с помощью следующего кода:
sns.catplot(x='Sex', y='Age', data=df)Коробочная диаграмма (Boxenplot)
Boxenplot предлагается в пакете seaborn и выглядит почти как box plot. Основное улучшение по сравнению с ящичковой диаграммой — это более детальное отображение квантилей, которые добавляют больше информации к визуализации для пользователя. Дополнительную информацию об этой визуализации можно найти в этой документации.
sns.boxenplot(x='Sex', y='Annual Income (k$)', data=df, palette = 'copper')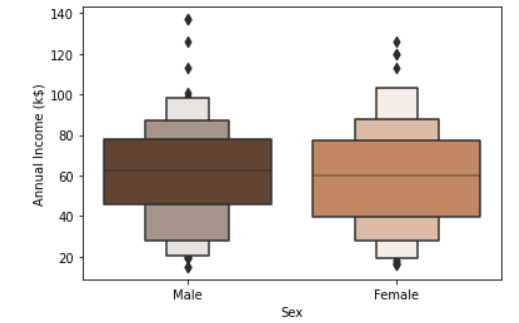
Матрица рассеяния (Scatter Matrix Plot)
Диаграмма матрицы рассеяния содержит как одномерную, так и многомерную визуализацию числовых переменных. Если имеется n числовых переменных, он отображает сетки n x n, а сетки в диагональных местах содержат одномерный график распределения (например, гистограмму) каждой переменной, в то время как другие сетки показывают нам точечные графики, которые объясняют взаимосвязь между различными комбинациями переменных. Смотрите визуализацию ниже!
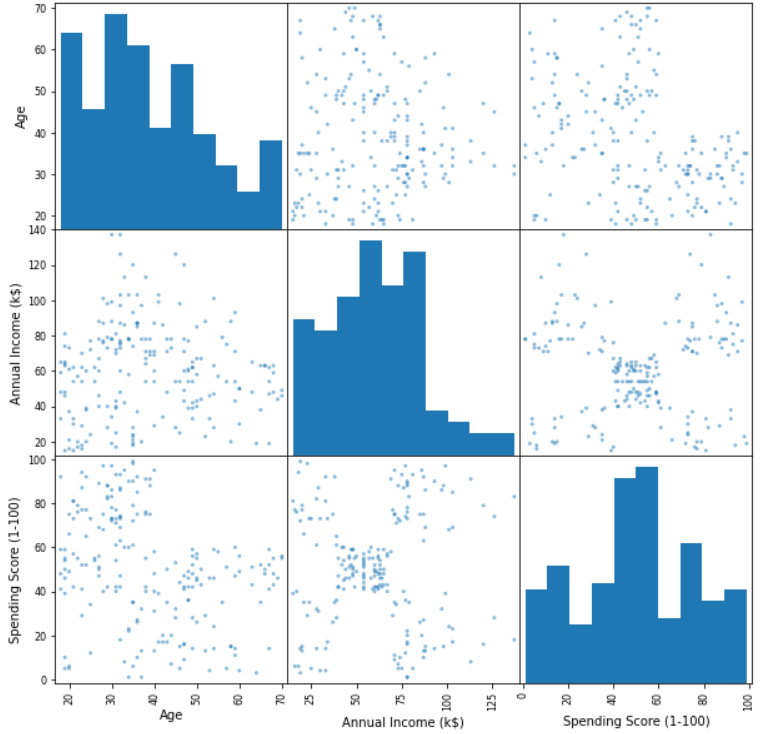
from pandas.plotting import scatter_matrix
pd.plotting.scatter_matrix(df.drop('CustomerID',axis=1), figsize=(10,10))Графики плотности (Density Plots)
График оценки распределения ядра — это тип графика распределения, похожий на гистограмму, но отличающийся тем, что он отображает функцию плотности вероятности, а не чистые числа или пропорции. Согласно документации pandas, «это непараметрический способ оценки функции плотности вероятности (PDF) случайной величины, который использует ядра Гаусса для оценки и включает автоматическое определение пропускной способности».
fig, ax = plt.subplots(1,1,figsize=(9,5))
sns.kdeplot(df[df['Sex']=='Male']['Annual Income (k$)'], ax=ax)
sns.kdeplot(df[df['Sex']=='Female']['Annual Income (k$)'], ax=ax)
plt.legend(['Sex == Male', 'Sex == Female'])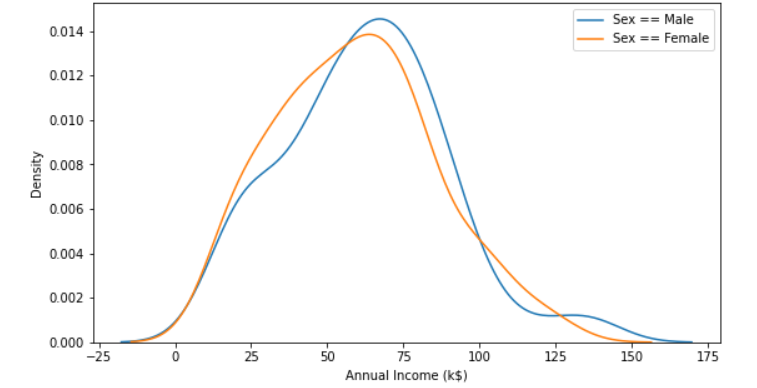
Эта визуализация, как вы можете видеть выше, полезна для сопоставления графиков плотности для разных категорий и просмотра различий в распределениях. Это может дать нам полезную информацию о самой переменной и потенциально идеи о том, как спроектировать эту функцию для повышения производительности модели.
Кривая Эндрюса (Andrews Curve)
Поскольку максимальное количество измерений, которые люди могут воспринимать и понимать, равно трем, любые комбинации признаков, которые превышают это количество измерений, становится очень сложно разместить на холсте. Чтобы обойти эту проблему, существует несколько визуализаций, которые описывают многомерные данные в трех измерениях так, чтобы мы могли их переварить. Кривая Эндрюса — одна из них. Он преобразует многомерные наблюдения следующим образом:
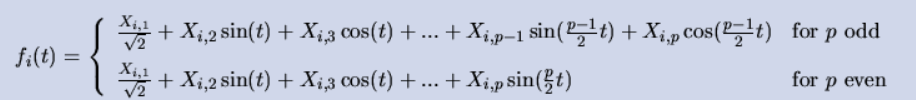
Взгляните на другой пример из этого руководства. Линии, соответствующие разным видам в данных IRIS, отмечены разными цветами, и мы видим, что некоторые линии сильно перекрываются, а другие нет. Это дает нам представление о том, какие категории в переменной имеют несопоставимые лежащие в основе распределения или закономерности по сравнению с другими.
from pandas.plotting import andrews_curves
# Only used 30 sampled data points to create the visualization because using the entire data makes the display too cluttered
andrews_curves(df.drop(“CustomerID”, axis=1).sample(30), ‘Sex’,colormap=’rainbow’)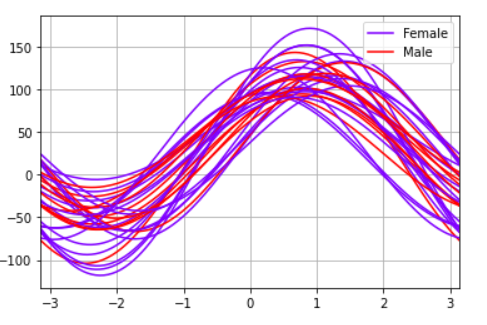
Диаграмма с областями с накоплением (Stacked Area Chart)
Диаграмма с областями с накоплением полезна для отображения разбивки пропорций или значений различных категорий с течением времени.Взгляните на следующую визуализацию.
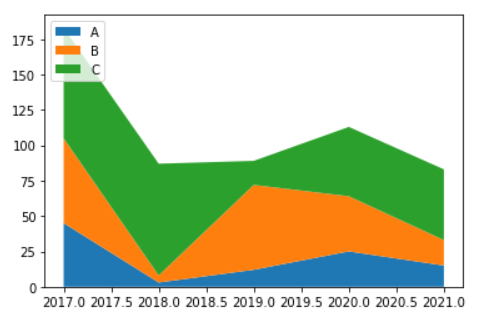
Как вы можете видеть выше, мы можем легко увидеть, как разбивка по категориям и A, B и C менялась с течением времени. Например, разбивка A, B и C была относительно равномерной, начиная с 2017 года. Однако доли B и C экспоненциально уменьшались до 2018 года, в то время как доля A оставалась относительно неизменной.
Карта дерева (Tree Map)
Подобно круговой диаграмме, столбчатой диаграмме и кольцевой диаграмме, древовидная карта показывает нам визуальное отображение различных пропорций категорий.Я лично думаю, что это может быть более эффективным, чем три вышеупомянутых сюжета, особенно когда у вас есть много категорий для сравнения.Например, в кольцевом графике многие категории с одинаковыми пропорциями, отображаемые в виде углов в круге, могут быть трудно уловимы.С другой стороны, карта с тремя деревьями, которая отображает пропорции в виде прямоугольников разного размера внутри одного большого прямоугольника, позволяет нам сразу узнать, как категории соотносятся друг с другом с точки зрения их размера.

import matplotlib.pyplot as plt
import seaborn as sns
import folium
import squarify
# Create a new variable that assigns random categories from 1 to 4 for the purpose of illustrating this example
df['rand_assignment'] = [randint(1,5) for e in range(len(df))]
y = df['rand_assignment'].value_counts( )
# The alpha argument sets the transparency of the visualization. If you would like to form the graph plot less transparent, make alpha greater than 1. This solidifies the graph plot, making it less transparent and dense. On the other hand, ff you would like to form the graph plot more transparent, make alpha smaller than 1.
squarify.plot(sizes = y.values, label = y.index, alpha=.8, color = ['red','orange','lightblue','green','pink'])
plt.axis('off')
plt.show()Вывод
В этой статье я объяснил вам 10 визуализаций и приемов, которые менее известны и используются, но их полезно добавить в ваш арсенал наборов инструментов для визуализации данных. Прежде всего, понимание того, что делает каждая визуализация, какую информацию она отображает, когда она будет наиболее эффективной и как ее можно использовать для передачи нужной информации аудитории, важнее, чем гордиться количеством визуализаций. вы умеете создавать.