14 приемов, позволяющих ускорить рабочий процесс Pandas

Pandas - одна из самых популярных библиотек Python для исследования и визуализации данных. Pandas предлагает множество API для выполнения задач по обработке данных, но при работе с большими наборами данных это приводит к сбоям или медленным вычислениям.
В этой статье мы обсудим 14 методов ускорения рабочего процесса Pandas с использованием различных техник, хаков или пакетов.
Ввод/вывод:
1) Выборка:
Pandas загружает весь файл в оперативную память сразу, что затрудняет работу с данными большого размера, что может привести к сбоям в работе памяти. Идея состоит в том, чтобы читать только необходимые экземпляры и функции.
df = pd.read_csv("data/MOCK_DATA.csv",
nrows=1000,
usecols=['id', 'email', 'ip_address'])API read_csv() предлагает параметры nrows и usecols для фильтрации количества записей и функций соответственно.
2) Разделение:
Методы выборки будут фильтровать и считывать выборку данных, но если вам нужно обработать все данные, вы можете разделить данные большого размера на фрагменты (что само по себе помещается в памяти). Теперь вы можете выполнять разработку функций, обработку данных и моделирование для каждого фрагмента данных.
import pandas as pd
from sklearn.linear_model import LogisticRegression
models = []
for chunk in pd.read_csv("data/MOCK_DATA.csv", chunksize=100000):
# peform all feature engineering to each chunk
chunk = feature_engineering(chunk)
# A function to clean my data and create my features
model = LogisticRegression()
model.fit(chunk[features], chunk['label'])
models.append(model)
# Inference
df = pd.read_csv("data/TEST_DATA.csv")
df = feature_engineering(df)
predictions = mean([model.predict(df[features]) for model in models], axis=0)3) Оптимизация типов данных:
При считывании данных Pandas автоматически определяет типы данных для каждой функции, однако типы данных не являются оптимальными и занимают больше, чем требуется, памяти. Идея состоит в том, чтобы уменьшить тип данных каждого объекта, соблюдая максимальное и минимальное значения объекта.
4) Оптимизация чтения/записи:
Чтение и запись больших наборов данных CSV, TXT или Excel при работе с библиотекой Pandas утомительны. Другие форматы файлов, такие как parquet, pickle, feather и т.д., могут быть предпочтительнее, поскольку они занимают сравнительно меньше вычислительного времени для операций чтения и записи.
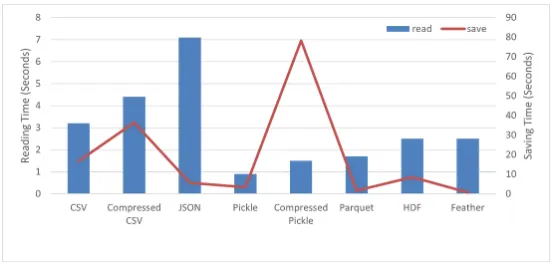
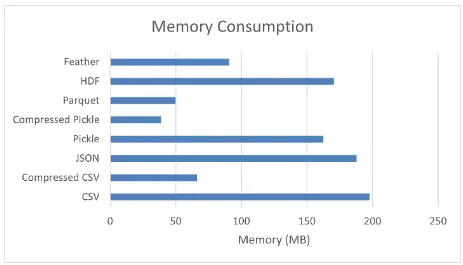
На приведенном выше изображении показаны контрольные цифры для операций чтения, записи и потребления памяти для образца набора данных, содержащего 1 458 644 записи и 12 объектов. Файлы Pickle могут быть предпочтительнее для сохранения и чтения наборов данных или временных файлов.
Итерация:
5) Итерация с использованием Iterrows():
Iterrows() — это встроенный API Pandas, используемый для итерации фрейма данных. Iterrows() выполняет несколько вызовов функций при переборе экземпляров фрейма данных, что делает его вычислительно затратным.
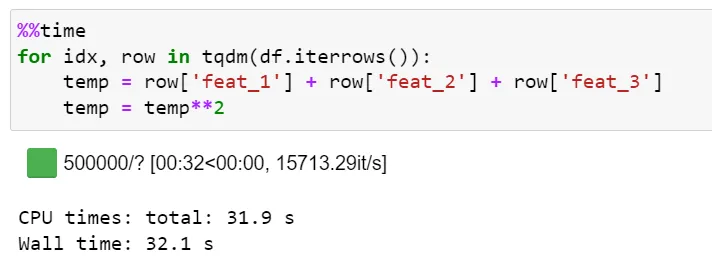
Чтобы перебрать более 500 тысяч экземпляров, iterrows() занимает ~ 32 секунды со скоростью около ~ 16 тысяч итераций в секунду.
6) Итерация с использованием Itertuples():
Itertuples() - это еще один встроенный API Pandas, который выполняет итерацию по фрейму данных путем преобразования каждой строки данных в виде списка кортежей. Itertuples() выполняет сравнительно меньшее количество вызовов функций и, следовательно, несет меньшие накладные расходы.
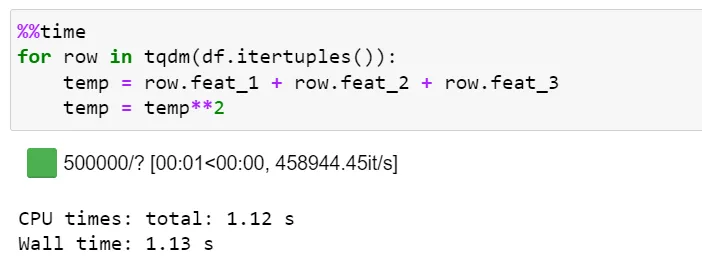
Чтобы перебрать более 500 тыс. экземпляров, itertuples() занимает ~1,12 секунды при скорости около ~ 460 тыс. итераций в секунду. Это примерно в 28 раз быстрее, чем у iterrows() API.
7) Итерация по словарю:
Идея состоит в том, чтобы преобразовать фрейм данных Pandas в словарь и выполнить итерацию по нему. Функциональные издержки фрейма данных Pandas теряются при итерации по словарю, но скорость вычислений повышается по сравнению с предыдущими методами.
Pandas поставляются с функцией df.to_dict('records') для преобразования фрейма данных в формат ключ-значение словаря.
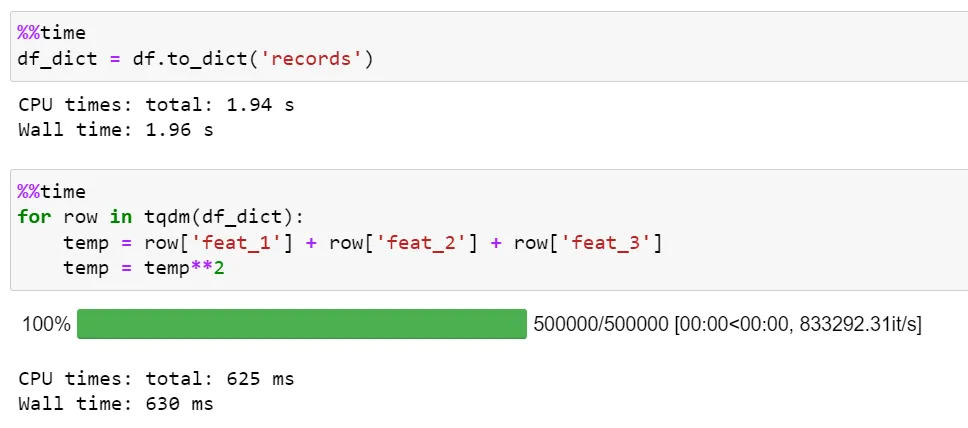
Чтобы перебрать более 500 тыс. экземпляров, итерация по словарю занимает 625 мс со скоростью около ~ 830 тыс. итераций в секунду. Это примерно в ~ 2 раза быстрее, чем у itertuples(), и в ~ 55 раз быстрее, чем у iterrows().
8) Использование apply():
Pandas предлагает apply() API для применения или выполнения функции вдоль оси фрейма данных.
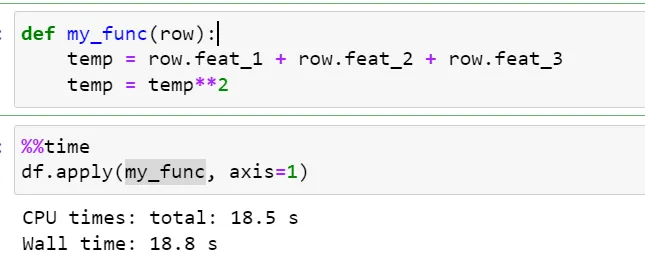
Чтобы перебрать более 500 тыс. экземпляров, apply() занимает ~18 секунд, что примерно в 2 раза быстрее, чем у iterrows() API, но медленнее, чем другие методы.
Распараллеливание:
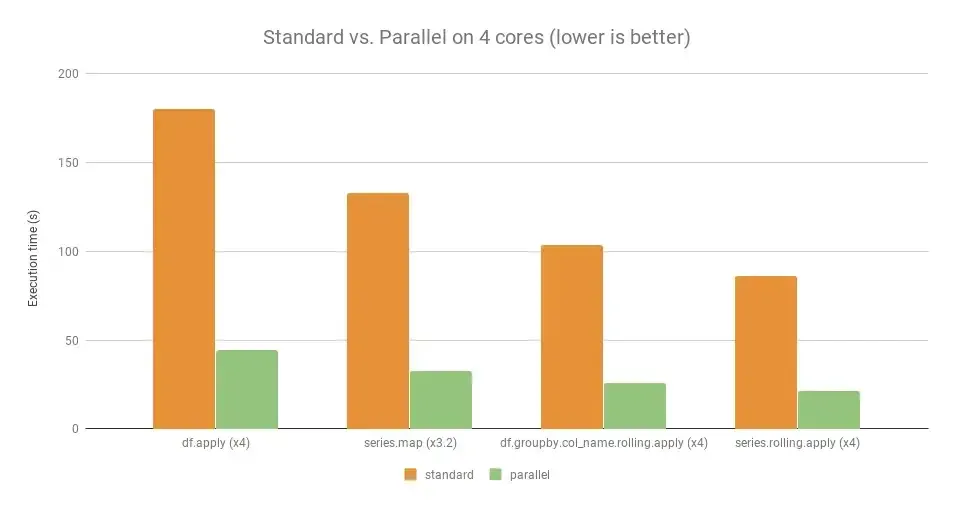
9) Многопроцессорность:
В python код интерпретируется во время выполнения вместо того, чтобы быть скомпилированным в машинный код во время компиляции, что делает его медленнее, чем в других языках программирования.
Идея состоит в том, чтобы использовать распределенные вычисления для ускорения вычислений на всех ядрах центрального процессора. Python предлагает многопроцессорный модуль, который обеспечивает такие функциональные возможности.
10) Pandarallel:
Pandarellel — это инструмент с открытым исходным кодом для распараллеливания операций pandas между всеми ядрами ЦП для значительного увеличения скорости.
С простым вариантом использования с pandas DataFrame и функцией для применения, просто замените классическое apply на parallel_apply.
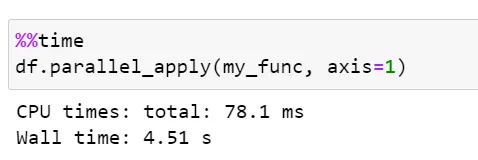
Чтобы перебрать более 500 тысяч экземпляров, apply() занимает ~5 секунд, что примерно в 4 раза быстрее, чем у apply() API.
11) Modin:
Modin — это многопроцессорный пакет с открытым исходным кодом и API-интерфейсами, идентичными Pandas, для ускорения рабочего процесса Pandas за счет изменения 1 строки кода. Modin предлагает ускоренную производительность примерно для 90+% API Pandas.
Модин использует Рэя и Даска под капотом для распределенных вычислений.
12) Dask:
Dask — это пакет Python с открытым исходным кодом, который предлагает многоядерное и распределенное параллельное выполнение для наборов данных с нехваткой памяти. Он следует концепции ленивых вычислений, отображения памяти и заблокированных алгоритмов под капотом для более быстрых вычислений.
Некоторые из коллекций высокого уровня, которые предлагает Dask:
- Dask Arrays: Состоит из нескольких массивов numpy, хранящихся в виде блоков
- Dask Data frame: Состоит из нескольких фреймов данных Pandas в виде фрагментов
- Dask Bag: Используется для работы с полуструктурированными или неструктурированными данными
- Dask Delayed: Распараллеливание пользовательских функций и циклов
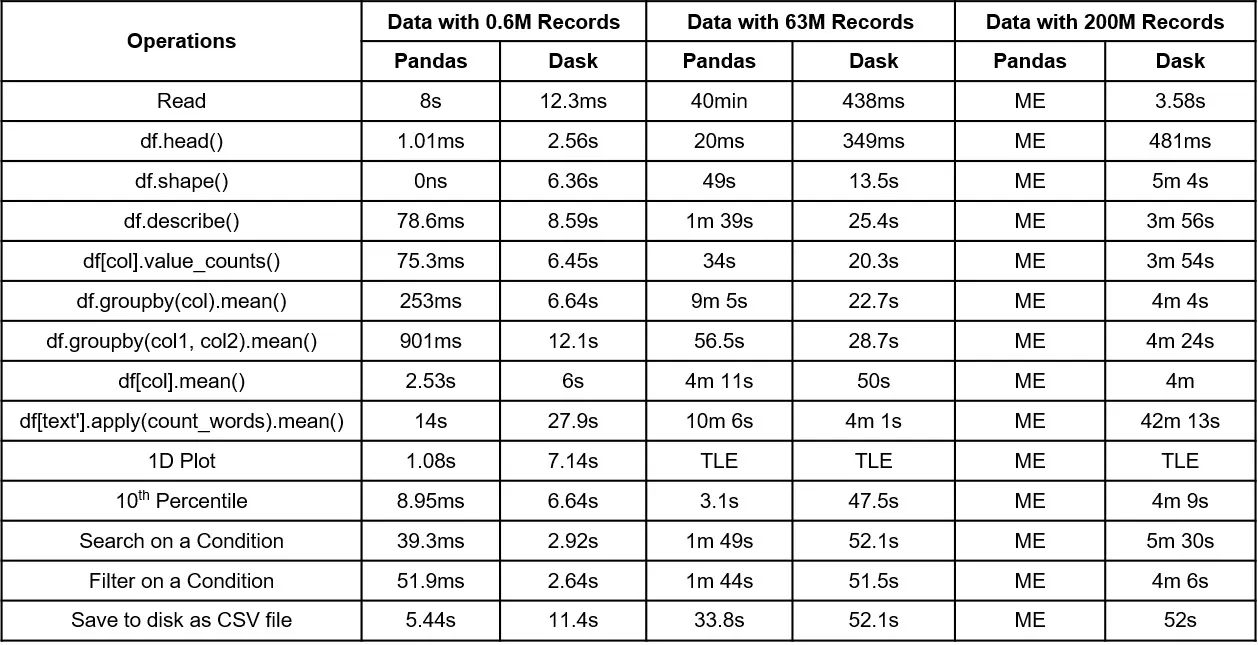
Ниже приведены результаты сравнительного анализа для Pandas и Dask Dataframe для небольших (600 тыс. записей), средних (63 млн записей) и больших (200 млн записей) наборов данных.
13) Vaex:
Vaex — это еще один высокопроизводительный пакет Python с открытым исходным кодом, заменяющий Pandas, который использует систему выражений и сопоставление памяти, чтобы позволить разработчикам выполнять операции с наборами данных с нехваткой памяти.
Большинство Vaex фокусируется на задачах обработки и исследования данных, но охватывает очень мало API-интерфейсов Pandas.
14) Swifter:
Swifter — еще один пакет Python с открытым исходным кодом, который можно интегрировать с объектами Pandas и ускорить выполнение. Swifter автоматически определяет наилучшую стратегию реализации для ускорения объектов Pandas путем векторизации или распараллеливания с помощью Dask.
Резюме:
Pandas - популярный пакет Python, используемый для задач разработки и анализа данных, но ему не хватает производительности и масштабируемости. В этой статье мы обсудили 14 хаков/техник для ускорения рабочего процесса Pandas. Все упомянутые методы довольно удобны и просты в реализации.