3 Способа хранения данных в приложениях компьютерного зрения

Когда дело доходит до компьютерного зрения, хранение данных является критически важным компонентом. Вы должны иметь возможность хранить изображения для обучения модели, а также результаты обработки для проверки модели. Есть несколько способов добиться этого, каждый из которых имеет свои преимущества и недостатки. В этом посте мы рассмотрим три различных способа хранения данных в приложениях компьютерного зрения: файловую систему, хранилище объектов, подобное S3, и Reduct Storaget. Мы также обсудим некоторые плюсы и минусы каждого варианта.
Простое приложение для компьютерного зрения
В демонстрационных целях мы будем использовать простое приложение для компьютерного зрения, которое подключается к CV-камере и работает на периферийном устройстве:
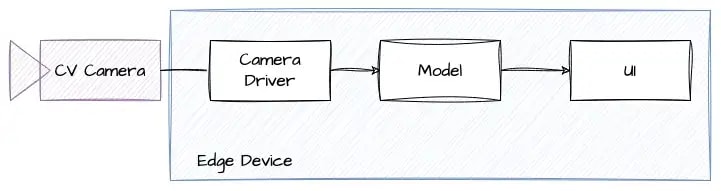
Драйвер камеры ежесекундно захватывает изображения с камеры CV и отправляет их модели. Модель что-то обнаруживает и показывает результаты в пользовательском интерфейсе.
Пока это не слишком сложно, давайте посмотрим, как мы можем работать с данными здесь.
Файловая система
Если приложению необходимо сохранить изображение с камеры CV, оно может просто сохранить его на жестком диске. Мы можем использовать временную метку в качестве уникального идентификатора и организовать папки и файлы таким образом, чтобы мы могли получить к ним доступ позже через определенный интервал времени.
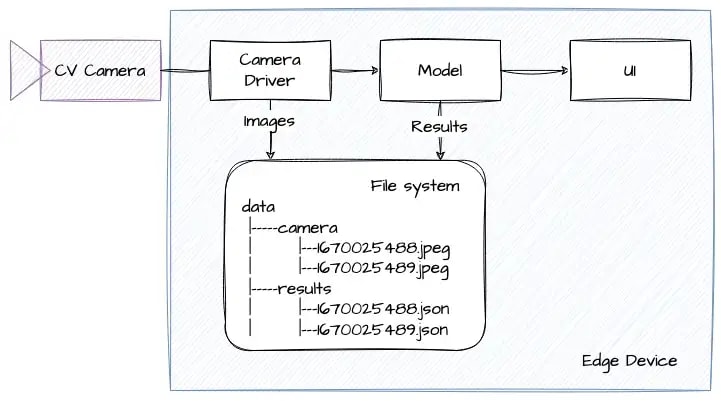
Одним из преимуществ этого метода является то, что он очень прост. Вам не нужны никакие дополнительные компоненты для вашей системы. Однако у него также есть несколько недостатков.
- ** Data reduction**. Рано или поздно у нас заканчивается место на диске. Мы должны удалить старые данные вручную, с помощью команды chron или включив эту функцию в приложение.
- Data accessibility. У нас есть соглашение об именовании для поиска данных, но нам все равно нужно пройти по дереву файлов. Чем больше у нас файлов, тем медленнее это работает. Мы могли бы создать индексный файл, но, похоже, мы начинаем создавать нашу собственную базу данных.
- Replication. Можно скопировать данные на другой узел с помощью утилит scp или rsync, однако это все еще ручной подход, и вам нужен прямой доступ к вашей машине через SSH.
- Security. Если кто-то хочет использовать сохраненные данные, мы должны предоставить либо доступ к устройству, которое во многих случаях небезопасно, либо предоставить копию данных, которая может быть огромной.
Хранилище объектов, подобных S3
Более продвинутый подход заключается в использовании системы хранения объектов для изображений. Это позволяет нам организовывать наши данные в механизме хранения точно так же, как папки и файлы, но получать к ним доступ и управлять ими с помощью HTTP API.
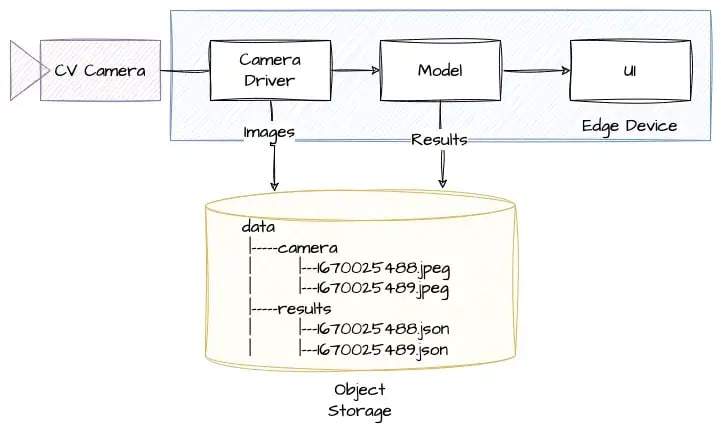
Это более гибкий подход, чем простая файловая система, и имеет некоторые преимущества:
- Remote storage. Мы можем хранить данные где-нибудь в облаке или на удаленном сервере, где у нас больше места на диске. Более того, если у вашей компании или клиента есть собственное озеро данных, основанное на объектном хранилище, мы можем записывать данные непосредственно туда.
- Security. Мы можем назначить различные разрешения для доступа к данным. Например, наше приложение может иметь доступ только на запись, а пользователи могут только читать его.
- Replication. Многие решения для хранения объектов допускают автоматическое или ручное зеркальное отображение данных на другой узел.
К сожалению, это решение тоже не идеально.
- Data reduction. У нас есть больше места для наших данных, но у нас по-прежнему нет никакого решения для удаления старых данных.
- Data accessibility. Поскольку данные в хранилище объектов имеют ту же структуру, что и файловая система, возникают те же проблемы с доступом. Более того, это еще медленнее, потому что мы используем HTTP-уровень.
Сокражение объема хранения
Reduce Storage - это база данных временных рядов с открытым исходным кодом для хранения истории больших двоичных объектов. Он предназначен для решения проблемы сокращения объема данных и их доступности для приложений AI/ML, где у нас есть данные различных размеров и форматов, непрерывно поступающие из источников данных.
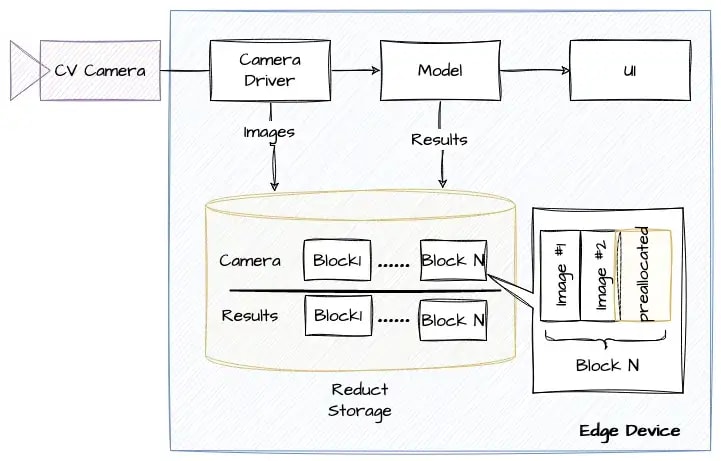
Как вы можете видеть, структура нашего приложения аналогична структуре при использовании системы хранения данных, подобной S3, но работает она по-другому. Вместо того, чтобы хранить большие двоичные объекты по отдельности, он предварительно выделяет блоки фиксированного размера и записывает несколько больших двоичных объектов в каждый блок. Это более эффективный способ записи и хранения данных, особенно при работе с небольшими двоичными объектами. Такой подход имеет следующие преимущества:
- Data Accessibility. Он использует временные метки записей в качестве уникального идентификатора и предоставляет HTTP API для простого доступа к данным через временную метку или временной интервал.
- Data reduction. Мы можем указать квоту для каждого сегмента, чтобы механизм хранения начинал удалять старые данные, когда размер сегмента достигает квоты.
- Security. Как и в случае с хранилищем объектов, мы можем получать доступ к данным с различными разрешениями.
- Replication. Reduce Storage предоставляет клиент CLI для зеркального отображения данных вручную.
Заключительные мысли
Все подходы к хранению исторических данных для изображений, которые мы обсуждали в этом посте, имеют свои сильные и слабые стороны и могут быть полезны в различных ситуациях. Например, использование файловой системы может быть простым и эффективным способом хранения данных на этапе прототипирования или проверки концепции приложения для компьютерного зрения. Он прост в настройке и использовании и не требует каких-либо дополнительных компонентов или инфраструктуры. Однако это может оказаться не самым эффективным или масштабируемым решением в долгосрочной перспективе.
Использование системы хранения объектов, подобной S3, может быть хорошим вариантом, если у вас уже есть инфраструктура такого типа и если вам необходимо хранить большие объемы данных или получать доступ к данным из нескольких местоположений. Он обеспечивает множество преимуществ, таких как масштабируемость, долговечность и безопасность, что может сделать его хорошим выбором для многих различных приложений. Однако это может потребовать дополнительной установки и конфигурирования и может быть более сложным в использовании, чем файловая система.
Reduce Storage - это специализированная база данных временных рядов для больших двоичных объектов данных в приложениях AI/ML. Он предназначен для решения проблем, связанных с сокращением объема данных и их доступностью. Это хороший вариант, если вам нужно хранить данные на периферийном устройстве и если вы хотите использовать расширенные функции, такие как дисковая квота в режиме реального времени и высокая производительность.