Анализ активности разработчиков и совместной работы с помощью Airbyte Quickstarts ft. Dagster, BigQuery, Google Colab, dbt и Terraform

Airbyte можно использовать как замечательный инструмент для преобразования данных. Эти преобразованные данные могут быть использованы для обучения моделей искусственного интеллекта (примеры в конце).
В этом руководстве в качестве источника используется API GitHub, который преобразуется с учетом тенденций активности разработчиков и может быть использован для обучения ИИ-моделей с целью повышения их предсказательной способности.
Я сделал полный обзор кода на сайте colab reference.
Вы можете либо скачать его как ipynb и запустить с локальным jupyter, либо выполнить пошаговое руководство с локальным cmd.
Начальная часть настройки Airbyte для извлечения данных из источника GitHub в BigQuery и преобразования SQL точно описаны в директории quickstarts.
Архитектура
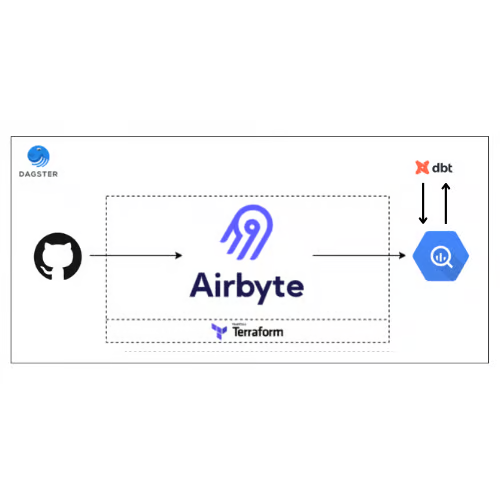
Технологические стеки: Dagster, dbt, Airbyte, GitHub API, BigQuery, Terraform
Мы собираемся извлекать данные из источника GitHub через пользовательский интерфейс Airbyte в набор данных BigQuery. Пользовательский интерфейс Airbyte автоматизирован с помощью провайдера Terraform.
После создания набора данных используется инструмент построения данных (dbt) для преобразования данных с помощью SQL-запросов для получения различных метрик, таких как среднее время на PR, среднее значение общего количества коммитов и т.д.
Часть 1.1: Настройка конвейера данных
Скриншоты прилагаются к блокноту colab, Airbyte и GitHub API:
Для подключения к источнику GitHub требуются три параметра:
- Имя репозитория
- Персональный токен доступа GitHub
- Идентификатор рабочего пространства
Airbyte и BigQuery:
Коннектор назначения BigQuery требует три параметра:
- JSON-ключ учетной записи службы IAM и Admin
- Идентификатор проекта облака Google
- Идентификатор набора данных BigQuery
Если вам интересно узнать, что происходит за кулисами, обратитесь к GitHub, где вы можете увидеть синхронизацию между GitHub и BigQuery.
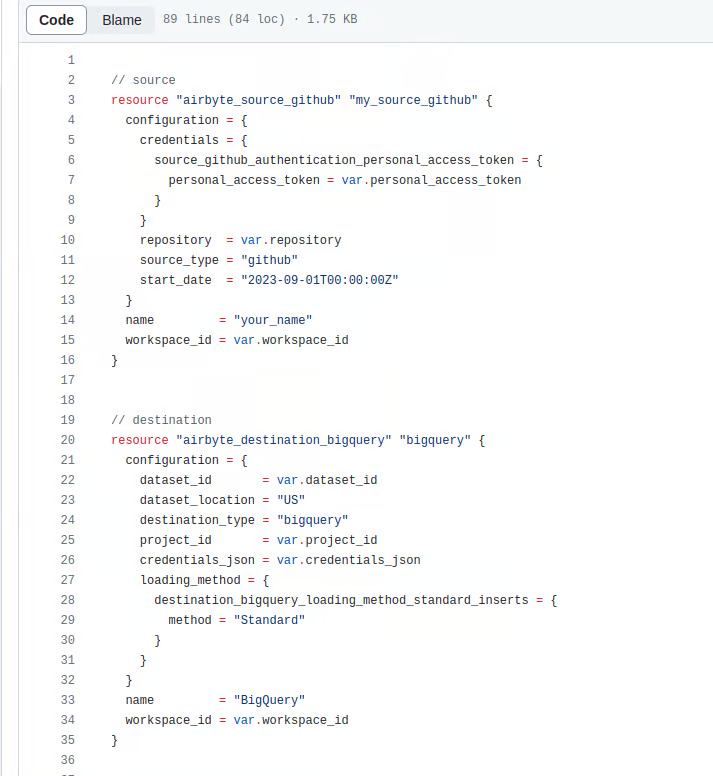
После этого задания Terraform будут завершены, пользовательский интерфейс Airbyte будет готов со всеми конфигурациями, которые были предоставлены, и потоки будут готовы к работе.
Ссылку на количество потоков можно найти на GitHub.
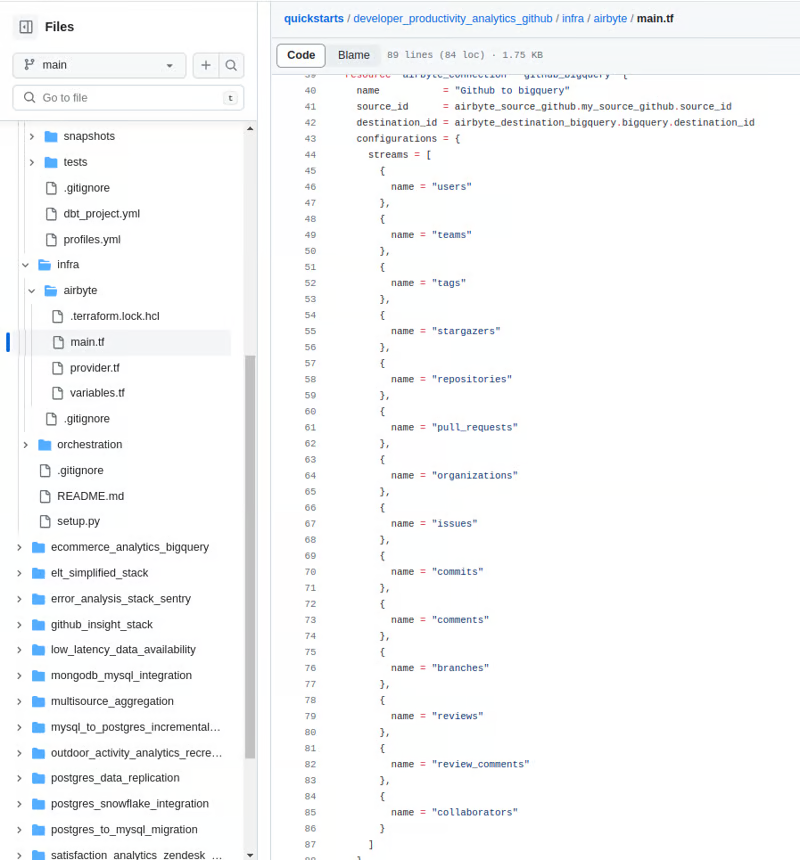
После запуска terraform apply пользовательский интерфейс Airbyte настроен и потоки готовы к работе.
Часть 1.2: Преобразования с помощью dbt
Установите переменные окружения, используемые для настройки dbt, в данный момент их всего три:
Либо установите эти переменные env, либо жестко пропишите их в файлах для следующих шагов.
Запустите dbt debug для подтверждения настройки.
Схему таблицы для каждого потока можно посмотреть на GitHub.
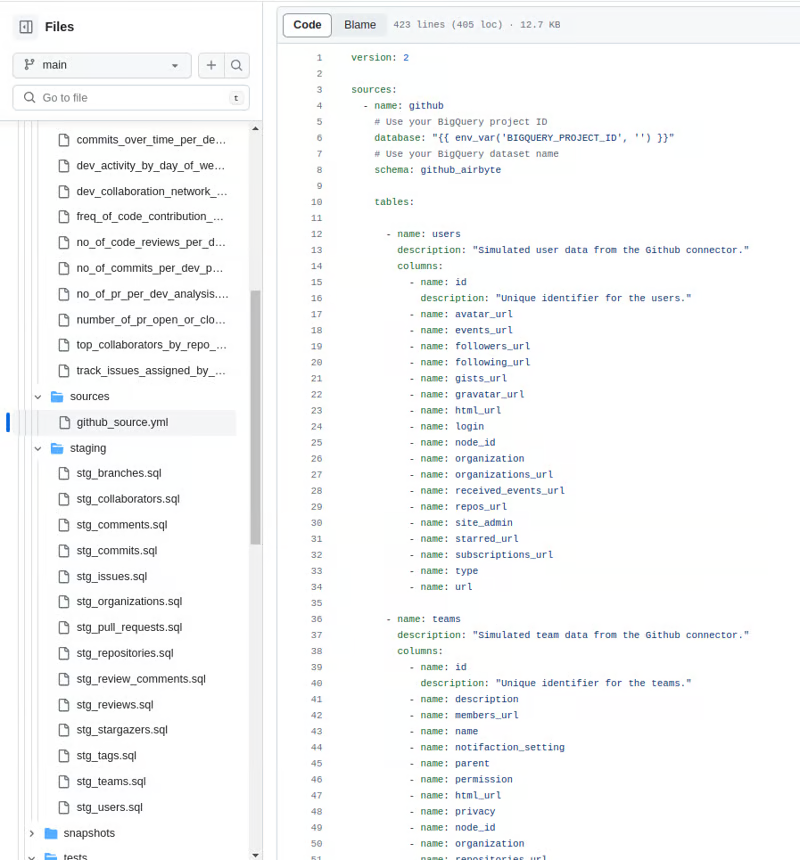
После выполнения dbt run --full-refresh в наборе данных BigQuery появились преобразованные таблицы.
Марты dbt очень полезны, когда из полученных данных извлекаются выводы, которые можно использовать для обучения ИИ.
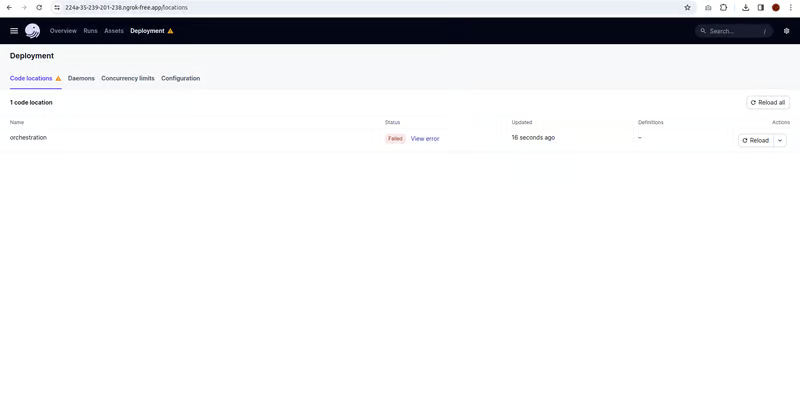
Часть 1.3: Оркестровка с помощью Dagster
Dagster и BigQuery:
Dagster – это современный оркестратор данных, предназначенный для создания, тестирования и мониторинга рабочих процессов с данными.
После запуска dagster dev будет открыт локальный порт или dagster, где можно будет увидеть рабочий процесс и проследить за синхронизацией.
Часть 1.4: Создание моделей искусственного интеллекта в Colab ft. Tensorflow
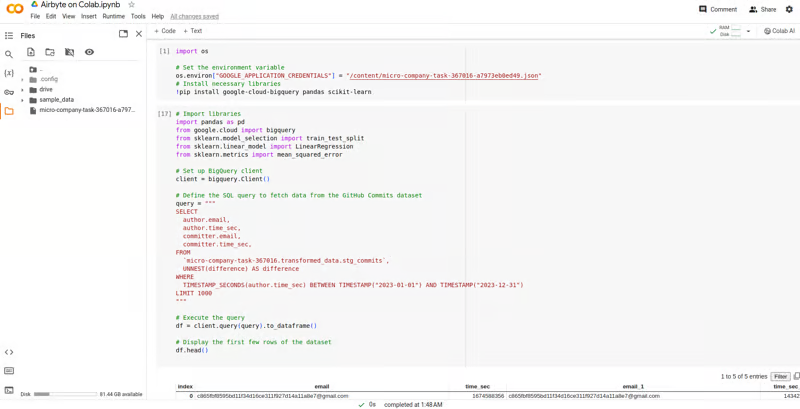
Экспорт данных BigQuery в Colab:
- Используйте коннектор BigQuery в Colab для загрузки нужных данных из таблиц анализа.
- Предварительно обработайте данные, очистив, отфильтровав и преобразовав их для конкретных входных данных модели.
- Постройте модель Tensorflow для оценки динамики и продуктивности команды:
- Выберите подходящую архитектуру, например LSTM или RNN, для анализа временных рядов активности разработчиков или используйте scikit-learn для количественного анализа.
- Обучите модель на исторических данных, используя такие характеристики, как время слияния PR, количество коммитов в день, частота рецензирования кода и т.д.
- Оцените эффективность модели на валидных данных.
Конкретный пример кода приведен в Colab.
Другой пример модели Tensorflow:
import tensorflow as tf
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
import matplotlib.pyplot as plt
# Load data from BigQuery
client = bigquery.Client()
query = """
SELECT
author.email,
author.time_sec AS time_sec,
committer.email,
committer.time_sec AS time_sec_1,
committer.time_sec - author.time_sec AS time_difference
FROM
`micro-company-task-367016.transformed_data.stg_commits`,
UNNEST(difference) AS difference
WHERE
TIMESTAMP_SECONDS(author.time_sec) BETWEEN TIMESTAMP("2023-01-01") AND TIMESTAMP("2023-12-31")
LIMIT 1000
"""
data = client.query(query).to_dataframe()
# Preprocess data
features = ['time_sec', 'time_sec_1']
target = 'time_difference'
# Drop rows with missing values
data = data.dropna(subset=features + [target])
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(data[features], data[target], test_size=0.2, random_state=42)
# Standardize features
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# Define TensorFlow model architecture
model = Sequential([
Dense(32, activation='relu', input_shape=(len(features),)),
Dense(16, activation='relu'),
Dense(1) # Output layer, no activation for regression
])
# Compile the model
model.compile(optimizer='adam', loss='mean_squared_error')
# Convert y_train to a NumPy array with a compatible dtype
y_train_np = y_train.values.astype('float32')
scaler_y = StandardScaler()
y_train_scaled = scaler_y.fit_transform(y_train_np.reshape(-1, 1))
y_test_scaled = scaler_y.transform(y_test.values.reshape(-1, 1))
# Train the model
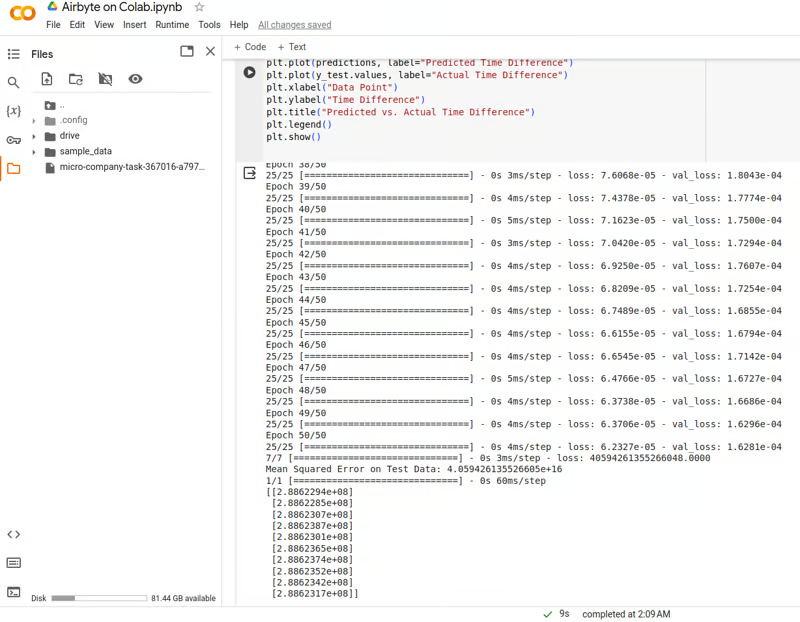
model.fit(X_train_scaled, y_train_scaled, epochs=50, batch_size=32, validation_data=(X_test_scaled, y_test_scaled))
# Convert y_test to a NumPy array with a compatible dtype
y_test_np = y_test.values.astype('float32')
# Evaluate the model
mse = model.evaluate(X_test_scaled, y_test_np)
print(f'Mean Squared Error on Test Data: {mse}')
# Generate synthetic new data
new_data = pd.DataFrame({
'time_sec': np.random.rand(10) * 1000, # Adjust the range as needed
'time_sec_1': np.random.rand(10) * 1000 # Adjust the range as needed
})
# Preprocess new data
new_data_scaled = scaler.transform(new_data[features])
# Make predictions on new data
predictions = model.predict(new_data_scaled)
predictions_inverse = scaler_y.inverse_transform(predictions)
# Display predictions
print(predictions_inverse)
# Plot model predictions
plt.plot(predictions, label="Predicted Time Difference")
plt.plot(y_test.values, label="Actual Time Difference")
plt.xlabel("Data Point")
plt.ylabel("Time Difference")
plt.title("Predicted vs. Actual Time Difference")
plt.legend()
plt.show()
Результаты моделирования:
Другие случаи использования:
- Прогнозировать будущие тенденции в динамике и продуктивности команд.
- Выявить факторы, влияющие на совместную работу и производительность отдельных разработчиков.
- Визуализировать результаты с помощью диаграмм, графиков и сетчатых визуализаций.
Заключительные мысли
350+ исходных коннекторов и огромное хранилище данных - это, безусловно, плюс для Airbyte. Мы могли бы использовать эту мощь преобразованных данных в качестве обучающих данных для многих AI-модулей, специально предназначенных для прогнозирования, особенно в анализе поведения разработчиков, прогнозировании акций и другом.
Ссылки: