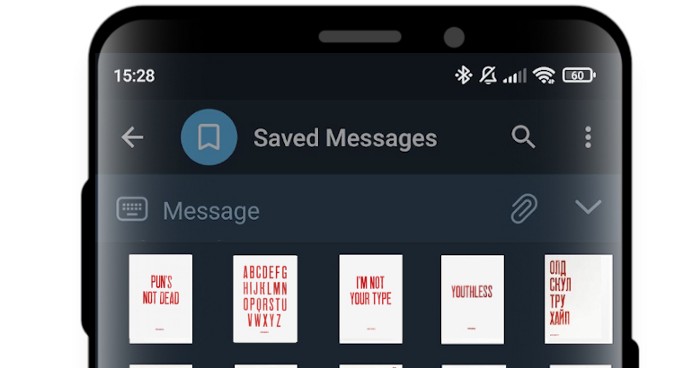
Автоматизация создания стикеров с помощью веб-скрейпинга и обработки изображений в Python

В этой статье я расскажу вам о том, как я создал 42 стикера Telegram из изображений постеров из интернет-магазина. В магазине продаются разные постеры с забавными каламбурами, но нет соответствующих стикеров. Создадим их!
Проблема только в том, что для создания единого стикера нужно скачать картинку с веб-страницы, отделить буквы от фона в фотошопе и сохранить в соответствующих разрешениях для стикеров Telegram. Для 42 изображений это займет очень много времени, поэтому давайте попробуем автоматизировать процесс.
Итак, план такой:
- Веб-скраппинг - проанализируйте все картинки из интернет-магазина.
- Автоматически отделяйте буквы от фона, удаляйте тени с фона и заставьте изображения больше походить на отсканированные изображения.
Скачивание картинок
Прежде всего, создадим список всех ссылок на страницы отдельных постеров. Таким образом, мы сможем загружать изображения в высоком разрешении. Разрешение картинок в основной галерее слишком маленькое.
Для этого сохраним все ссылки с картинок в галерее.
import requests
from bs4 import BeautifulSoup
import urllib.request
url = 'https://demonpress.ecwid.com/%D0%9F%D0%BB%D0%B0%D0%BA%D0%B0%D1%82%D1%8B-c26701164'
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36'}
text = requests.get(url, headers=headers)
soup = BeautifulSoup(text.content, 'html.parser')
urls = []
for i in soup.find_all('a', attrs = {"class": "grid-product__image"}):
urls += [i['href']]Галерея разделена на четыре страницы, каждая из которых содержит 15 плакатов. Чтобы перейти на следующую страницу, достаточно добавить ?offset=15, 30 или 45. Это позволяет нам разобрать оставшиеся ссылки.
for i in ['15','30','45']:
url_next = url + '?offset=' + i
text = requests.get(url_next, headers=headers)
soup = BeautifulSoup(text.content, 'html.parser')
for i in soup.find_all('a', attrs = {"class": "grid-product__image"}):
urls += [i['href']]Последняя часть - это переход по всем ссылкам и загрузка изображений в высоком разрешении со страниц продуктов.
for url in urls:
text = requests.get(url, headers=headers)
soup = BeautifulSoup(text.content, 'html.parser')
for j in soup.find_all('img', {'class':'details-gallery__picture details-gallery__photoswipe-index-0'}):
urllib.request.urlretrieve(j['src'], j['title'].replace('/','').replace('*','').replace('?','')+'.jpg')
Картинки названы по тексту на плакатах, поэтому нам нужно удалить запрещенные символы из имени, такие как «/», «?» а также "*".
Обработка изображений
К сожалению, в интернет-магазине вместо сканов есть фотографии постеров. Поэтому мы не можем использовать их как есть. Вот пример того, как выглядит типичное изображение:

Позер на картинке подсвечивается сбоку. Это делает текстуру бумаги хорошо видимой. В некоторых случаях сложно разделить буквы с помощью порога яркости, потому что при определенных обстоятельствах буквы могут быть ярче некоторых частей фона. В данном случае такой подход не универсален.
Чтобы реализовать подход, который подходил бы для всех возможных условий освещения, воспользуемся тем фактом, что все плакаты содержат большие красные буквы на белом или сером фоне. Каждый пиксель цифрового изображения представляет собой вектор из трех чисел. Серый пиксель, независимо от того, яркий он или тусклый, состоит из трех одинаковых чисел, а цветной пиксель будет содержать числа, которые отличаются друг от друга.
Таким образом, гораздо эффективнее разделять фон на основе порога стандартного отклонения, а не яркости. После нескольких попыток я понял, что хорошей оценкой для такого порога будет 30.
После определения пикселя как части фона, давайте установим его значение на (245, 245, 245). Пиксели, входящие в состав букв, будут установлены ближе к (200, 17, 11). Фон не будет идеально белым, но он выглядит лучше, поскольку идеальной белой бумаги не существует, а набор наклеек должен имитировать плакаты.
def remove_bg(input_img: np.ndarray) -> np.ndarray:
img = input_img.copy()
for i in range(0, img.shape[0]):
for j in range(0, img.shape[1]):
if img[i][j].std() < 30:
img[i][j] = [245, 245, 245]
else:
img[i][j] = img[i][j] + 0.5*([200, 17, 11] - img[i][j])
return img
Вот результат:

Теперь последний шаг - изменить размер изображения так, чтобы наибольшая длина была 512. Чтобы изменить размер всех изображений и сохранить их как файлы png, я воспользуюсь библиотекой PIL.
from PIL import Image
files = []
for i in os.listdir('.'):
if i[-4::] == '.jpg':
files += [i]
for file in files:
img = mpimg.imread(file).copy()
img = remove_bg(img)
x = int(512)
y = int(512 * img.shape[1]/img.shape[0])
img = Image.fromarray((resize(img, (x, y))*255).astype(np.uint8))
img.save(f'result/{file[0:-4]}', 'png')
print('Done!')
Вот результат: