Безопасная идентификация рака молочной железы с помощью Enclaves

В этом блоге мы разрабатываем модель логистической регрессии для выявления рака молочной железы, гарантируя при этом, что конфиденциальные медицинские данные, используемые для обучения модели, остаются конфиденциальными, используя платформу конфиденциальных вычислений Cape Privacy.
Проблема конфиденциальности медицинских данных
Выполнение анализа данных и моделирования на основе медицинских данных может дать чрезвычайно полезную информацию как об общественном, так и об индивидуальном здоровье. Однако, когда дело доходит до проведения статистического анализа или разработки прогностических моделей с использованием медицинских данных, возникают две основные проблемы. Первая проблема - это размер наборов медицинских данных. Медицинские испытания часто включают в себя количество участников, которое может быть слишком маленьким для создания сложных моделей машинного обучения. Вторая проблема заключается в том, что медицинские данные регулируются различными правилами конфиденциальности и законами, такими как HIPAA.
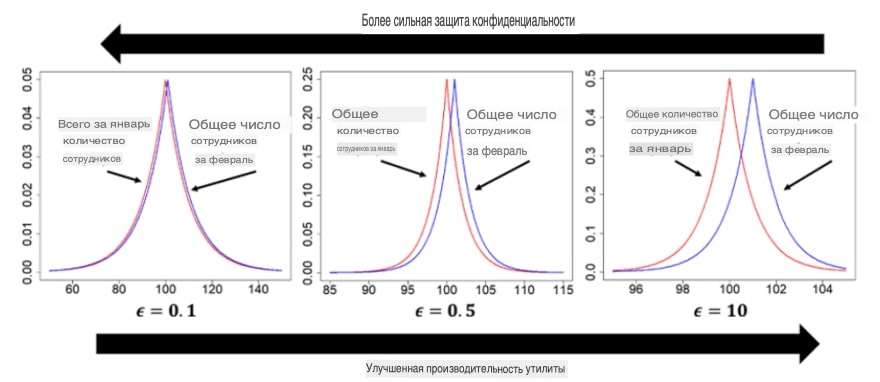
Одним из подходов к решению этой проблемы является использование различных методов обеспечения конфиденциальности, которые скрывают точки данных, относящиеся к конкретным лицам, чтобы сохранить конфиденциальность их информации. Однако недостатком является то, что это позволяет изучать только агрегированные данные на высоком уровне. Более того, шум, добавляемый к отдельным точкам данных для обеспечения конфиденциальности, может привести к тому, что данные будут обработаны слишком далеко от оригинала. Таким образом, существует компромисс между добавленным шумом (также называемым бюджетом конфиденциальности ϵ), который обеспечивает более надежную защиту конфиденциальности, и полезностью данных. На рисунке ниже показан этот компромисс между конфиденциальностью данных и полезностью на примере запроса к базе данных сотрудников, который возвращает общее количество сотрудников за два разных месяца. Мы видим, что по мере увеличения бюджета на конфиденциальность общее количество сотрудников становится неточным, что может помочь скрыть некоторую личную информацию, такую как увольнение конкретного человека, за счет точного представления общей численности персонала.
Именно здесь на помощь приходит конфиденциальная вычислительная платформа Cape, основанная на AWS Nitro enclaves.
Cape гарантирует, что конфиденциальные данные остаются конфиденциальными
Конфиденциальная вычислительная платформа Cape позволяет своим пользователям обрабатывать данные с сохранением конфиденциальности без необходимости идти на компромисс между конфиденциальностью данных и полезностью. С Cape вам не нужно использовать различные методы обеспечения конфиденциальности, вместо этого вы можете обрабатывать свои исходные данные как есть, потому что ваши данные будут зашифрованы и обработаны в безопасном хранилище в облаке.
Cape предоставляет интерфейс командной строки, который позволяет своим пользователям шифровать свои входные данные, а также развертывать и запускать бессерверные функции с помощью простых команд: cape encrypt, cape deploy и cape run. Кроме того, Cape также предоставляет два SDK: pycape и cape-js, которые позволяют использовать cape в программах на Python и JavaScript соответственно.
Подготовка модели идентификации рака молочной железы с помощью Cape
В этой статье мы будем использовать общедоступный набор данных о раке молочной железы, который содержит табличные данные, описывающие несколько атрибутов, которые описывают опухоль молочной железы (например: размер и форма опухоли), наряду с классификацией опухоли как злокачественной или доброкачественной. Например, опухоль, которая однородна и имеет круглую форму, обычно указывает на то, что она не является злокачественной.
Хотя этот набор данных является общедоступным, большинство медицинских данных таковыми не являются, и мы будем использовать его в качестве примера, чтобы продемонстрировать, как Cape можно использовать для обработки частных медицинских данных.
Логистическая регрессия
Поскольку модель, которую мы хотим разработать, представляет собой модель бинарной классификации, которая идентифицирует опухоли молочной железы как злокачественные или доброкачественные, а количество точек данных не очень велико, подходит модель логистической регрессии.
Логистическая регрессия - это модель классификации, которая использует входные атрибуты для прогнозирования категориальной переменной, например, да или нет. В этой демонстрации мы сосредоточимся на бинарной классификации, поскольку существует только два возможных результата.
Создание функции, которая обучает модель логистической регрессии
Любая функция, развернутая с помощью Cape, должна быть названа app.py, где app.py должен содержать функцию с именем cape_handler(), которая принимает входные данные, обрабатываемые функцией, и возвращает результаты. В этом случае входными данными является набор данных о раке молочной железы, который служит в качестве обучающих данных, а выходными данными является обученная модель логистической регрессии.
Приведенный ниже фрагмент кода показывает наш app.py. Сначала мы импортируем некоторые библиотеки следующим образом:
import pandas as pd
import numpy as np
import copyЗатем мы определяем класс логистической регрессии с методами, которые могут выполнять обучение или компьютерную модель точности и потерь:
class LogisticRegression():
def __init__(self):
self.losses = []
self.train_accuracies = []
def accuracy_score(self, y_true, y_pred):
correct = np.sum(y_true == y_pred)
accuracy = correct/y_true.shape[0]
return accuracy
def fit(self, x, y, epochs):
x = self._transform_x(x)
y = self._transform_y(y)
self.weights = np.zeros(x.shape[1])
self.bias = 0
for i in range(epochs):
x_dot_weights = np.matmul(self.weights, x.transpose()) + self.bias
pred = self._sigmoid(x_dot_weights)
loss = self.compute_loss(y, pred)
error_w, error_b = self.compute_gradients(x, y, pred)
self.update_model_parameters(error_w, error_b)
pred_to_class = [1 if p > 0.5 else 0 for p in pred]
self.train_accuracies.append(self.accuracy_score(y, pred_to_class))
self.losses.append(loss)
def compute_loss(self, y_true, y_pred):
# binary cross entropy
y_zero_loss = y_true * np.log(y_pred + 1e-9)
y_one_loss = (1-y_true) * np.log(1 - y_pred + 1e-9)
return -np.mean(y_zero_loss + y_one_loss)
def compute_gradients(self, x, y_true, y_pred):
# derivative of binary cross entropy
difference = y_pred - y_true
gradient_b = np.mean(difference)
gradients_w = np.matmul(x.transpose(), difference)
gradients_w = np.array([np.mean(grad) for grad in gradients_w])
return gradients_w, gradient_b
def update_model_parameters(self, error_w, error_b):
self.weights = self.weights - 0.1 * error_w
self.bias = self.bias - 0.1 * error_b
def predict(self, x):
x_dot_weights = np.matmul(x, self.weights.transpose()) + self.bias
probabilities = self._sigmoid(x_dot_weights)
return [1 if p > 0.5 else 0 for p in probabilities]
def _sigmoid(self, x):
return np.array([self._sigmoid_function(value) for value in x])
def _sigmoid_function(self, x):
if x >= 0:
z = np.exp(-x)
return 1 / (1 + z)
else:
z = np.exp(x)
return z / (1 + z)
def _transform_x(self, x):
x = copy.deepcopy(x)
return x.values
def _transform_y(self, y):
y = copy.deepcopy(y)
return y.values.reshape(y.shape[0], 1)В дополнение к классу логистической регрессии, наш app.py также содержит требуемую функцию cape_handler, которая принимает обучающие данные в качестве входных данных, разбивает их на обучающий и тестовый наборы, создает экземпляр указанного выше класса логистической регрессии, выполняет обучение и выводит обученную модель вместе с ее точностью.
def cape_handler(input_data):
csv = input_data.decode("utf-8")
csv = csv.replace('\\t', ',').replace('\\n', '\n')
f = open('data.csv', 'w')
f.write(csv)
f.close()
data = pd.read_csv('data.csv')
data_size = data.shape[0]
test_split = 0.33
test_size = int(data_size * test_split)
choices = np.arange(0, data_size)
test = np.random.choice(choices, test_size, replace=False)
train = np.delete(choices, test)
test_set = data.iloc[test]
train_set = data.iloc[train]
column_names = list(data.columns.values)
features = column_names[1:len(column_names)-1]
y_train = train_set["target"]
y_test = test_set["target"]
X_train = train_set[features]
X_test = test_set[features]
lr = LogisticRegression()
lr.fit(X_train, y_train, epochs=150)
pred = lr.predict(X_test)
accuracy = lr.accuracy_score(y_test, pred)
# trained model
model = {"accuracy": accuracy, "weights": lr.weights.tolist(), "bias": lr.bias.tolist()}
return modelИспользование с Cape
Чтобы развернуть нашу функцию с помощью Cape, нам сначала нужно создать папку, содержащую все необходимые зависимости. Для этого приложения для обучения логистической регрессии эта папка развертывания должна содержать app.py выше. Кроме того, поскольку app.py программа импортирует некоторые внешние библиотеки (в данном случае: numpy и pandas), они также должны быть в папке развертывания. Мы можем сохранить список этих зависимостей в requirements.txt файл и запустите docker, чтобы установить эти зависимости в нашу папку развертывания под названием app следующим образом:
sudo docker run -v `pwd`:/build -w /build --rm -it python:3.9-slim-bullseye pip install -r requirements.txt --target ./app/Теперь, когда у нас все готово, мы можем войти в Cape:
cape login
Your CLI confirmation code is: GZPN-KHMT
Visit this URL to complete the login process: https://login.capeprivacy.com/activate?user_code=GZPN-KHMT
Congratulations, you're all set!И после этого мы можем развернуть приложение:
cape deploy ./app
Deploying function to Cape ...
Success! Deployed function to Cape
Function Checksum ➜ 348ea2008f014b4d62562b4256bf2ddbbebcbd8b958981de5c2e01a973f690f8
Function Id ➜ 5wggR4ZaEBdfHQSbV2RcN5Вызываем с Cape
Теперь, когда приложение развернуто, мы можем передать ему входные данные и вызвать его с помощью cape run:
cape run 5wggR4ZaEBdfHQSbV2RcN5 -f breast_cancer_data.csv
{'accuracy': 0.9197860962566845, 'weights': [10256.691270418847, 19071.613672774896, 63157.95554188486, 97842.31573298419, 106.154850842932, 43.29810217015701, -44.1862890971466, -22.519840356544492, 198.12010662303672, 78.6238754895288, 48.39822623036688, 1508.6634081937177, 342.695612801048, -22814.6600120419, 8.905474463874354, 16.958969184554977, 18.625567417774857, 7.857666827748692, 25.00139435235602, 4.305377619109947, 9667.094831413606, 24077.953801047104, 59698.82218324606, -91019.69570680606, 137.85512994764406, 64.23315269371734, -35.801829085602265, 1.0606119748691598, 287.2889897905756, 89.52499975392664], 'bias': 3.247905759162303}В приведенных выше выходных данных перечислены параметры обученной модели, т.е. ее веса и смещение, которые определяют модель и могут быть использованы для выполнения вывода. Кроме того, мы также можем видеть, что точность обученной модели по данным тестирования составляет 92%.
Заключение
В этом блоге мы обсудили проблемы разработки прогностических моделей для медицинских данных и то, как платформа конфиденциальных вычислений Cape может решить проблемы конфиденциальности, связанные с обработкой медицинских данных. Мы определили модель логистической регрессии и обучились определять опухоли молочной железы как злокачественные или доброкачественные, сохраняя при этом конфиденциальность медицинских данных, которые использовались для обучения.