Философия поэтапного обучения машинному обучению с помощью River

Если вы устали от переобучения моделей и хотите вместо этого создавать динамические модели, то машинное онлайн-обучение (и, следовательно, River!) может быть тем, что вам нужно. Если цель состоит в том, чтобы учиться и делать прогнозы по одному экземпляру за раз. River на порядок быстрее, чем PyTorch, Tensorflow и scikit-learn.
Традиционный подход машинного обучения
Машинное обучение часто выполняется в пакетном режиме, когда модель подгоняется к набору данных за один раз. Это приводит к статической модели, которую необходимо переобучить, чтобы учиться на новых данных.
Некоторые недостатки традиционного машинного обучения
Во многих случаях это не элегантно и неэффективно и обычно влечет за собой значительный технический долг. Действительно, если вы используете пакетную модель, вам нужно подумать о поддержке обучающего набора, мониторинге производительности в реальном времени, переобучении модели и т. д.
Постепенный подход к River
Используя River, вы можете постоянно учиться на потоке данных. Это означает, что модель обрабатывает одно наблюдение за раз и поэтому может обновляться на лету. Это позволяет учиться на массивных наборах данных, которые не помещаются в основную память.
В настройках потоковой передачи масштабирование функций выполняется с использованием текущей статистики — структуры данных, которая позволяет постепенно обновлять среднее значение и стандартное отклонение.
Для постепенного обучения модели распространенным алгоритмом обучения является стохастический градиентный спуск (SGD). SGD — популярный алгоритм обучения нейронных сетей, имеющий несколько вариантов. Его также можно использовать для обучения других моделей, таких как линейная регрессия. Основная идея SGD заключается в том, что на каждом этапе обучения веса параметров модели корректируются в направлении, противоположном градиенту, который вычисляется с использованием ошибки прогнозирования модели на этом этапе.
Случаи применения
Подход River прекрасно интегрируется в случаях, когда постоянно поступают новые данные. Он великолепен во многих случаях использования, таких как прогнозирование временных рядов, фильтрация спама, рекомендательные системы, прогнозирование CTR и приложения IoT.
Вот некоторые преимущества использования River (и машинного онлайн-обучения в целом):
- Инкрементальный: модели могут обновляться в режиме реального времени.
- Адаптивный: модели могут адаптироваться к изменению концепции
- Готовность к производству: работа с потоками данных упрощает воспроизведение производственных сценариев во время разработки модели.
- Эффективный: модели не нуждаются в переобучении и требуют небольшой вычислительной мощности, что снижает их углеродный след.
- Быстрый: когда цель состоит в том, чтобы учиться и прогнозировать по одному экземпляру за раз, то River на порядок быстрее, чем PyTorch, Tensorflow и scikit-learn.
Предсказания River
Учиться и предсказывать — две основные функции всех прогностических моделей. Метод Learn One используется для обучения (обновляет внутреннее состояние модели). predict one(классификации, регрессия и кластеризация), predict proba one (классификация) и score one(обнаружение аномалий) алгоритмы дают прогнозы в зависимости от цели обучения. Стоит отметить, что river включает в себя преобразователи, которые являются объектами с сохранением состояния, которые используют метод transform one для преобразования входных данных
Чтобы установить river, вы можете использовать pip, как показано ниже.
pip install riverRiver, как и creme, имеет аналогичный API, такой как Scikit-learn, и также называется Scikit-learn для потокового или онлайн-машинного обучения. Он поддерживает почти все различные оценки и преобразователи ML, но предназначен для потоковой передачи данных.
Тот простой факт, что мы получаем данные в виде потока, означает, что мы не можем делать многие вещи так же, как в традиционном пакетном режиме.
Масштабирование
Например, предположим, что мы хотим масштабировать данные так, чтобы они имели среднее значение 0 и дисперсию 1, как мы делали ранее. Для этого нам просто нужно вычесть среднее значение каждой функции из каждого значения, а затем разделить результат на стандартное отклонение функции. Проблема в том, что мы не можем узнать значения среднего и стандартного отклонения до того, как проверим все данные! Один из способов продолжить — выполнить первый проход по данным для вычисления необходимых значений, а затем масштабировать значения во время второго прохода. Проблема в том, что это противоречит нашей цели, которая состоит в том, чтобы учиться, только взглянув на данные один раз. Хотя это может показаться довольно ограничительным, в будущем это принесет значительные преимущества.
То, как мы выполняем масштабирование функций в river, включает в себя вычисление текущей статистики (также известной как статистика перемещения). Идея состоит в том, что мы используем структуру данных, которая оценивает среднее значение и обновляется при получении значения. То же самое касается дисперсии (и, следовательно, стандартного отклонения). Теперь идея состоит в том, что мы можем вычислить текущую статистику каждой функции и масштабировать их по мере их появления. Способ сделать это с помощью river - использовать класс StandardScaler из модуля preprocessing.
Вот некоторые из методов, которые мы будем использовать:
naive_bayes- это алгоритм, который мы будем использовать для построения нашей модели классификации текста.preprocessing- будет использоваться при обработке нашего набора данных, используемого для обучения нашей модели.metrics- используется для расчета показателя точности нашей модели.stream- используется для имитации потоковой передачи нашего набора данных.anomaly- используется для обнаружения ошибок и аномалий в нашей модели.compose- используется для построения конвейера для автоматизации рабочих процессов машинного обучения.
Теперь, когда мы масштабируем данные, мы можем приступить к реальному машинному обучению.
Пример 1. Быстрый старт
В качестве быстрого примера мы обучим логистическую регрессию для классификации набора данных о фишинге веб-сайта. Вот посмотрите на первое наблюдение в наборе данных.
>>> from pprint import pprint
>>> from river import datasets
>>> dataset = datasets.Phishing()
>>> for x, y in dataset:
... pprint(x)
... print(y)
... break
{'age_of_domain': 1,
'anchor_from_other_domain': 0.0,
'empty_server_form_handler': 0.0,
'https': 0.0,
'ip_in_url': 1,
'is_popular': 0.5,
'long_url': 1.0,
'popup_window': 0.0,
'request_from_other_domain': 0.0}
True
Теперь давайте запустим модель в наборе данных в потоковом режиме. Мы последовательно чередуем прогнозы и обновления модели. Тем временем мы обновляем показатель производительности, чтобы увидеть, насколько хорошо работает модель.
>>> from river import compose
>>> from river import linear_model
>>> from river import metrics
>>> from river import preprocessing
>>> model = compose.Pipeline(
... preprocessing.StandardScaler(),
... linear_model.LogisticRegression()
... )
>>> metric = metrics.Accuracy()
>>> for x, y in dataset:
... y_pred = model.predict_one(x) # make a prediction
... metric = metric.update(y, y_pred) # update the metric
... model = model.learn_one(x, y) # make the model learn
>>> metric
Accuracy: 89.20%
Пример 2. Несбалансированный набор данных (мошенничество с кредитными картами)
В машинном обучении довольно часто приходится иметь дело с несбалансированным набором данных. Это особенно верно в отношении онлайн-обучения для таких задач, как обнаружение мошенничества и классификация спама. В этих двух случаях, которые представляют собой проблемы бинарной классификации, обычно нулей намного больше, чем единиц, что обычно снижает производительность классификаторов, которые мы им бросаем.
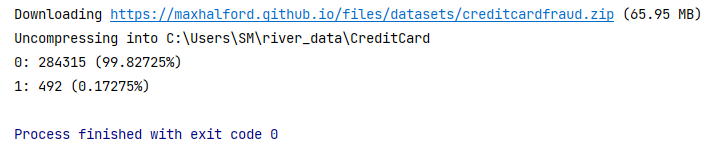
В качестве примера мы будем использовать набор данных кредитных карт, доступный в river. Сначала мы будем использовать collections. Счетчик для подсчета количества нулей и единиц, чтобы получить представление о балансе классов.
import collections
from river import datasets
X_y = datasets.CreditCard()
counts = collections.Counter(y for _, y in X_y)
for c, count in counts.items():
print(f'{c}: {count} ({count / sum(counts.values()):.5%})')
Базовая модель
Набор данных довольно несбалансирован. На каждую единицу приходится около 578 нулей. Давайте теперь обучим логистическую регрессию с параметрами по умолчанию и посмотрим, насколько хорошо она работает. Мы измерим показатель ROC AUC.
from river import linear_model
from river import metrics
from river import evaluate
from river import preprocessing
X_y = datasets.CreditCard()
model = (
preprocessing.StandardScaler() |
linear_model.LogisticRegression()
)
metric = metrics.ROCAUC()
evaluate.progressive_val_score(X_y, model, metric)
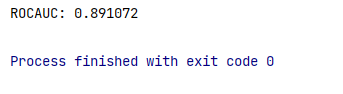
Производительность уже вполне приемлемая, но, как мы сейчас увидим, мы можем добиться еще большего.
Выборка с желаемым размером выборки и распределением по классам
Недостатком как RandomUnderSampler, так и RandomOverSampler является то, что у вас нет никакого контроля над объемом данных, на которых обучается классификатор. Количество выборок корректируется таким образом, чтобы можно было достичь целевого распределения либо за счет недостаточной, либо за счет избыточной выборки. Однако вы можете сделать и то, и другое одновременно и выбрать, сколько данных будет видеть классификатор. Для этого мы можем использовать класс RandomSampler. В дополнение к желаемому распределению классов мы можем указать, на каком количестве данных обучаться. Образцы будут как недовыборочными, так и перевыборочными, чтобы соответствовать вашим ограничениям. Это мощно, потому что позволяет вам контролировать как распределение классов, так и размер обучающих данных (и, следовательно, время обучения). В следующем примере мы установим его так, чтобы модель обучалась с 1 процентом данных.
StandardScaler в River
Масштабирует данные так, чтобы они имели нулевое среднее значение и единичную дисперсию. Под капотом сохраняются среднее значение и дисперсия. Масштабирование немного отличается от масштабирования данных в пакетном режиме, поскольку точные средние значения и отклонения заранее неизвестны. Однако это не оказывает пагубного влияния на производительность в долгосрочной перспективе.
Этот преобразователь поддерживает как мини-пакеты, так и отдельные экземпляры. В случае мини-пакета количество столбцов и порядок столбцов могут изменяться между последующими вызовами. Другими словами, этот преобразователь будет продолжать работать, даже если вы будете добавлять и/или удалять функции каждый раз, когда вы вызываете learn_manyи transform_many.
Параметры Imblearn
- Классификатор ( base.Classifier)
- desired_dist ( словарь)
- Желаемое распределение классов. Ключи - это классы, а значения - желаемые проценты классов. Значения должны суммироваться до 1. Если установлено значение
None, то наблюдения будут отбираться равномерно случайным образом, что строго эквивалентно использованиюensemble.BaggingClassifier. - sample_rate — по умолчанию
1.0 - Желаемое соотношение данных к выборке.
- seed ( inthttps://medium.com/codex/philosophy-of-incremental-ml-learning-with-river-f309050ccbc) — по умолчанию
None - Случайное начальное значение для воспроизводимости.
#Under Sampling & Oversmapling
model = (
preprocessing.StandardScaler() |
imblearn.RandomSampler(
classifier=linear_model.LogisticRegression(),
desired_dist={0: .8, 1: .2},
sampling_rate=.01,
seed=42
)
)
metric = metrics.ROCAUC()
print(evaluate.progressive_val_score(X_y, model, metric))

Посмотрите, как улучшились наши показатели.
Вывод
River предоставляет несколько современных методов обучения, генераторов/преобразователей данных, показателей производительности и оценщиков для различных задач потокового обучения. Это результат слияния двух самых популярных пакетов для потокового обучения в Python: Creme и scikit-multiflow. River представляет обновленную архитектуру, основанную на уроках, извлеченных из основополагающих пакетов. Задача River — стать популярной библиотекой для машинного обучения потоковых данных.