Чтение файлов Excel с помощью Pandas read_excel() в Python

Функция read_excel() входит в состав библиотеки Pandas языка Python и предназначена для чтения данных из файлов Excel. Файлы Excel обычно используются для хранения табличных данных, а функция read_excel() обеспечивает удобный и гибкий способ импорта этих табличных данных для анализа и манипулирования ими в среде Python. В этом уроке мы разберемся, как можно прочитать файл Excel в Pandas DataFrame с помощью функции read_excel(). Давайте начнем.
Синтаксис функции Pandas read_excel()
Функция read_excel() поддерживает форматы .xls и .xlsx и предоставляет различные опции для настройки процесса чтения.
Синтаксис:
read_excel(io,
sheet_name=0,
header=0,
names=None,
index_col=None,
usecols=None,
squeeze=None,
dtype=None,
engine=None,
converters=None,
true_values=None,
false_values=None,
skiprows=None,
nrows=None,
na_values=None,
keep_default_na=True,
na_filter=True,
verbose=False,
parse_dates=False,
date_parser=None,
thousands=None,
decimal='.',
comment=None,
skipfooter=0,
convert_float=None,
mangle_dupe_cols=True,
storage_options=None)Важные параметры:
sheet_name: Имя или индекс листа для чтения.header: Строка для использования в качестве имен столбцов.names: Список имен столбцов для использования.index_col: Столбец для установки в качестве индекса (целое число или имя столбца).usecols: Столбцы для парсинга (int, str, list-like или callable).skiprows: Количество строк, которые нужно пропустить в начале.
Использование файла Excel для создания таблицы данных
У нас есть фиктивный файл Excel под названием Students.xlsx, содержащий два листа, один из которых - студенческий, а другой - преподавательский, как показано ниже.
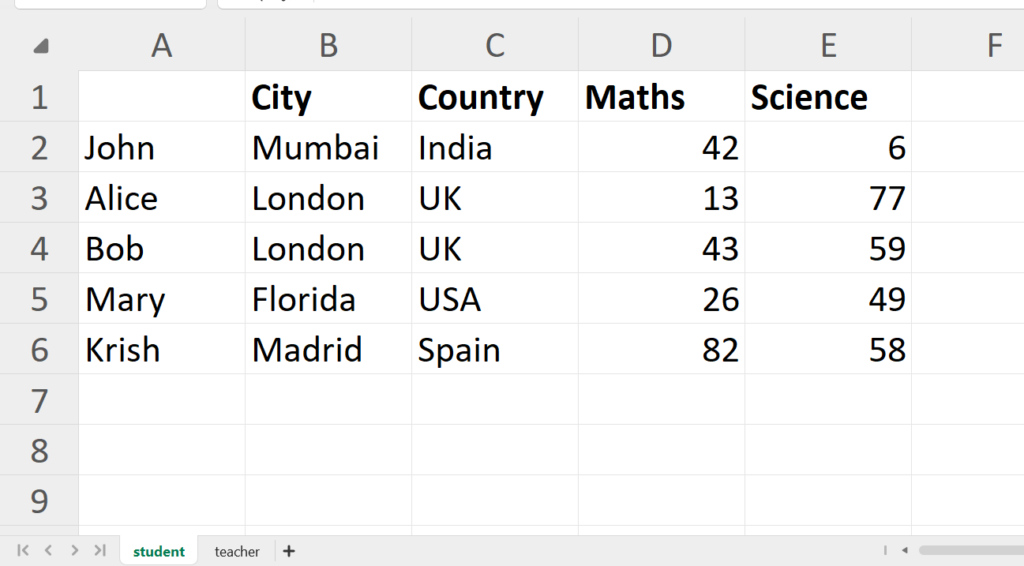
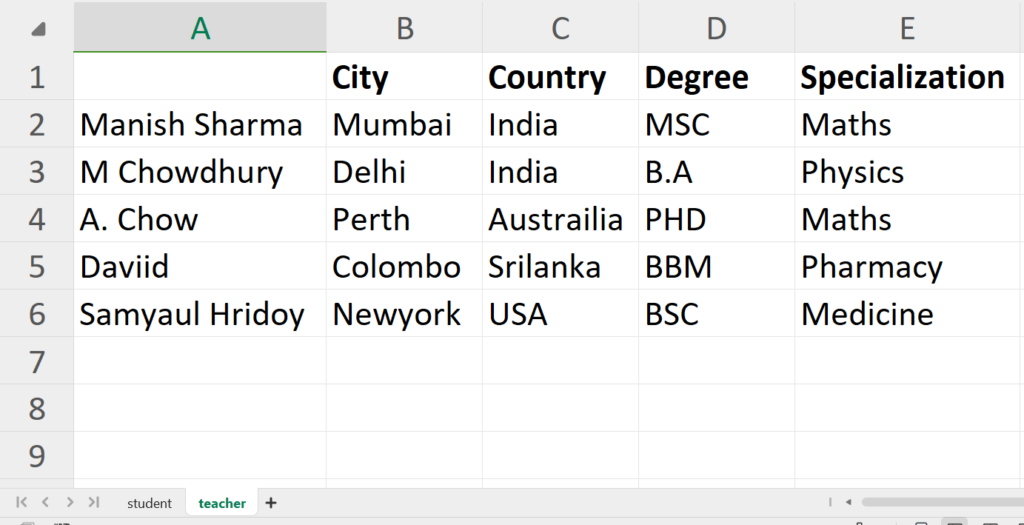
Чтобы прочитать файл Excel, сначала нам нужно импортировать модуль Pandas под именем pd, чтобы мы могли использовать его функцию read_excel() для чтения.
import pandas as pd
pd.read_excel('Students.xlsx')В приведенном выше коде мы передали имя нашего файла Excel Students.xlsx в качестве входных данных в функцию read_excel(), чтобы мы могли прочитать наш файл Excel.
Выходные данные:
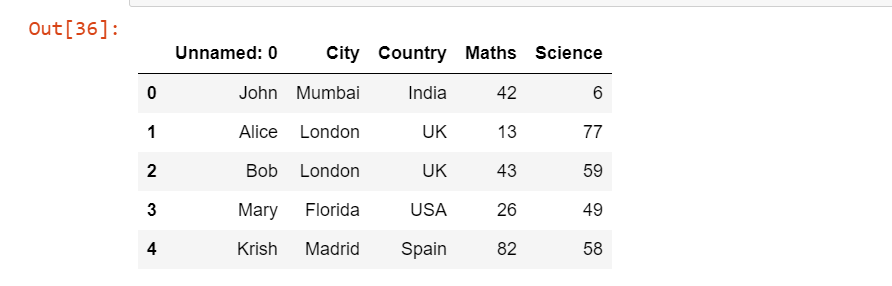
После выполнения кода мы видим, что функция read_excel() успешно прочитала файл Students.xlsx и определила, что первая строка - это строка заголовка. Но всё же есть один столбец, где мы не указали никакого имени заголовка, который считается как Unnamed:0, что является ничем иным, как именем студента.
Установка столбца в качестве индекса
Теперь предположим, что мы хотим сделать столбец Unnamed: 0 индексным столбцом, чтобы мы могли обращаться к отдельным строкам через имена, например, "John" или "Alice". Для этого мы можем просто добавить один аргумент index_col равный 0, чтобы нулевой столбец рассматривался как индексный, а нулевой столбец был Unnamed: 0.
pd.read_excel('Students.xlsx', index_col=0)Выходные данные:
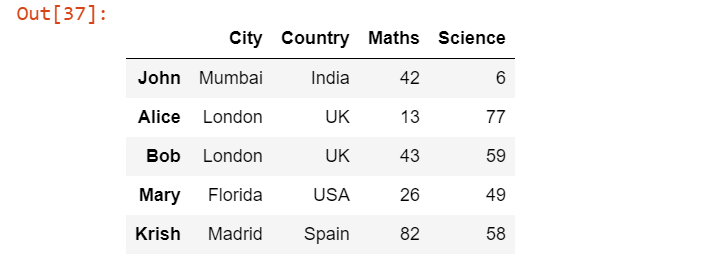
На выходе мы видим разницу в том, что все имена стали индексными столбцами.
Определение нового заголовка
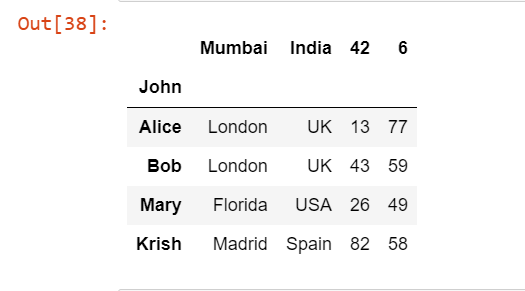
По умолчанию в качестве заголовка рассматривается самая первая строка или, можно сказать, нулевая, но если файл Excel не может рассматривать первую строку в качестве заголовка, то в этом случае можно просто добавить ещё один аргумент, например, что заголовок равен какой-то другой строке.
pd.read_excel('Students.xlsx', index_col=0, header=1)В приведенном выше коде мы приняли заголовок за 1, что означает, что 1-я строка будет теперь заголовком в файле Excel, который по умолчанию был нулевой строкой.
Выходные данные:
Чтение конкретных столбцов
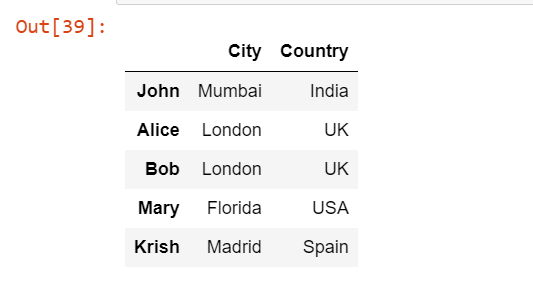
Теперь предположим, что вместо чтения всех этих столбцов мы хотим прочитать только первые несколько столбцов. Скажем, только столбцы Name, City и Country. Для этого мы можем добавить еще один аргумент usecols.
pd.read_excel('Students.xlsx', index_col=0, usecols="A:C")
Мы добавили аргумент usecols в виде A:C в функцию read_excel(), которая будет читать только три столбца с начального.
Выходные данные:
Изменение имен столбцов
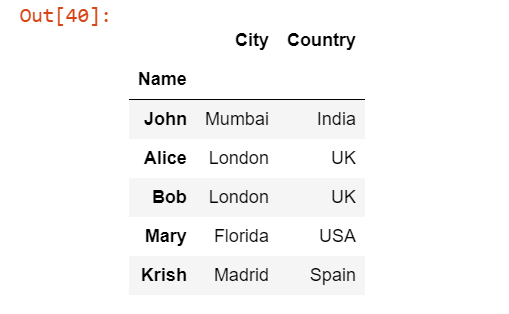
Теперь предположим, что мы хотим дать индивидуальное имя каждому столбцу, для этого мы можем задать аргумент names. В нашем случае мы обращаемся только к первым трем столбцам, поэтому мы должны дать имена только первым трем столбцам. Если мы попытаемся назвать все пять столбцов, то будет выдана ошибка.
pd.read_excel('Students.xlsx', index_col=0, usecols="A:C", names=["Name","City","Country"])
Мы передали аргумент names в виде ["Name", "City", "Country"] в функцию read_excel(), которая присвоит собственные имена первым трем столбцам, поскольку мы считываем только три столбца с начала.
Выходные данные:
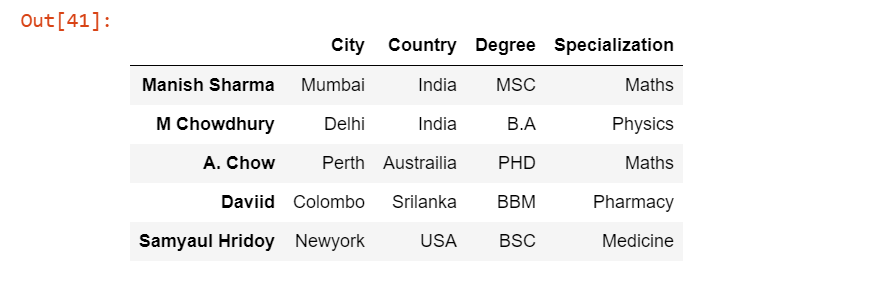
Задание имени листа для извлечения данных
До сих пор мы имели дело только с первым листом, имя которого - student, но в файле Excel Students.xlsx есть и второй лист, имя которого - teacher. Поэтому, чтобы прочитать второй лист, нам нужно передать аргумент sheet_name равным 1, а по умолчанию значение sheet_name равно 0, что означает первый лист.
pd.read_excel('Students.xlsx', index_col=0, sheet_name=1)Выходные данные:
Переходящие ряды
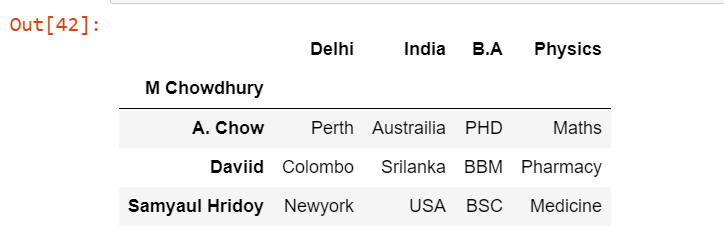
Допустим, нам не нужны некоторые строки из нашего дата-фрейма. Для этого мы можем присвоить аргументу skiprows целое число или список целых чисел.
pd.read_excel('Students.xlsx', index_col=0, sheet_name='teacher', skiprows=[0,1])Мы передали skiprows как [0,1], что означает, что первые две строки из массива данных будут пропущены.
Выходные данные:
Заключение
В этой статье мы познакомились с функцией Pandas read_excel() в Python. Мы узнали, как читать файлы Excel в фреймах данных, включая такие приемы, как установка столбца в качестве индекса, пропуск строк, указание имен листов, изменение имен столбцов и выборочное чтение определенных столбцов. В нашем последующем посте вы познакомитесь с функцей to_excel(), предоставляемую библиотекой Python Pandas для экспорта фрейма данных в файл Excel. Мы надеемся, что после прочтения этой статьи вы сможете легко читать файлы Excel в Pandas DataFrame в Python.