Как протестировать несколько конвейеров машинного обучения с помощью всего нескольких строк Python

На этапе исследования проекта специалист по обработке данных пытается найти оптимальный конвейер для своего конкретного случая использования. Поскольку заранее узнать, какие преобразования принесут наибольшую пользу модели, практически невозможно, этот процесс обычно включает опробование различных подходов. Например, если мы имеем дело с несбалансированным набором данных, должны ли мы производить избыточную выборку для класса меньшинства или занижать выборку для класса большинства? В этой истории я объясню, как использовать пакет ATOM, чтобы быстро помочь вам оценить производительность модели, обученной на разных конвейерах. ATOM - это пакет Python с открытым исходным кодом, разработанный, чтобы помочь специалистам по обработке данных ускорить исследование конвейеров машинного обучения.
Управление конвейером
Самый простой способ объяснить, как управлять несколькими конвейерами, - это рассмотреть пример. В этом примере мы:
- Создаем несбалансированный набор данных и передаем его в ATOM
2. Уменьшим количество функций с помощью Recursive Feature Elimination (RFE).
3. Обучим три модели Random Forest (RF):
- Один тренировался непосредственно на несбалансированном наборе данных
- Один обучался на наборе данных после применения передискретизации
- Один обучался на наборе данных после применения недостаточной выборки
4. Сравним результаты.
И все это мы сделаем менее чем за 20 строк кода! Давайте начнем.
Создаем набор данных
Мы начинаем создавать набор данных имитационной двоичной классификации с долей образцов 0,95–0,05, отнесенных к каждому классу. Затем данные передаются в ATOM.
from atom import ATOMClassifier
from sklearn.datasets import make_classification
# Create an imbalanced dataset
X, y = make_classification(
n_samples=5000,
n_features=30,
n_informative=20,
weights=(0.95,),
)
# Load the dataset into atom
atom = ATOMClassifier(X, y, test_size=0.2, verbose=2)
Набор данных автоматически делится на состав и тестовый набор. Результат выглядит следующим образом.
<< ================== ATOM ================== >>
Algorithm task: binary classification.
Dataset stats ====================== >>
Shape: (5000, 31)
Scaled: False
Outlier values: 582 (0.5%)
---------------------------------------
Train set size: 4000
Test set size: 1000
---------------------------------------
| | dataset | train | test |
|---:|:------------|:------------|:-----------|
| 0 | 4731 (17.6) | 3777 (16.9) | 954 (20.7) |
| 1 | 269 (1.0) | 223 (1.0) | 46 (1.0) |
Сразу видно, что набор данных несбалансирован, поскольку он содержит почти в 18 раз больше нулей, чем единиц. Посмотрим на данные. Обратите внимание, что, поскольку ввод не был фреймом данных, ATOM присвоил столбцам имена по умолчанию.
atom.dataset.head()

Выполните выбор функции
В целях пояснения мы начнем с этапа преобразования данных, который мы хотим использовать во всех конвейерах, которые мы собираемся тестировать. Часто это может быть что-то вроде масштабирования признаков или вменения пропущенных значений. В этом случае мы уменьшаем размерность данных с 30 до 12 признаков. С ATOM это так же просто.
atom.feature_selection("RFE", solver="RF", n_features=12)
Эта команда запускает RFE с использованием Random Forest в качестве оценщика. Остающийся набор данных содержит наиболее многообещающие функции.
Fitting FeatureSelector...
Performing feature selection...
--> The RFE selected 12 features from the dataset.
>>> Dropping feature Feature 2 (rank 3).
>>> Dropping feature Feature 3 (rank 8).
>>> Dropping feature Feature 5 (rank 10).
>>> Dropping feature Feature 7 (rank 17).
>>> Dropping feature Feature 8 (rank 12).
>>> Dropping feature Feature 11 (rank 19).
>>> Dropping feature Feature 13 (rank 13).
>>> Dropping feature Feature 14 (rank 11).
>>> Dropping feature Feature 15 (rank 15).
>>> Dropping feature Feature 17 (rank 4).
>>> Dropping feature Feature 19 (rank 16).
>>> Dropping feature Feature 20 (rank 2).
>>> Dropping feature Feature 21 (rank 6).
>>> Dropping feature Feature 23 (rank 5).
>>> Dropping feature Feature 24 (rank 9).
>>> Dropping feature Feature 25 (rank 18).
>>> Dropping feature Feature 26 (rank 7).
>>> Dropping feature Feature 27 (rank 14).
Теперь мы обучаем нашу первую модель непосредственно на несбалансированном наборе данных. Используя метод run, мы подбираем Random Forest на обучающем наборе и оцениваем его на тестовом наборе.
atom.run(models="RF", metric="balanced_accuracy")
Training ===================================== >>
Models: RF
Metric: balanced_accuracy
Results for Random Forest:
Fit ---------------------------------------------
Train evaluation --> balanced_accuracy: 1.0
Test evaluation --> balanced_accuracy: 0.5326
Time elapsed: 0.733s
-------------------------------------------------
Total time: 0.733s
Final results ========================= >>
Duration: 0.733s
------------------------------------------
Random Forest --> balanced_accuracy: 0.5326
Система ветвления
Прежде чем мы продолжим, пришло время объяснить систему ветвления ATOM. Система ветвления позволяет управлять несколькими конвейерами в одном экземпляре ATOM. Каждый конвейер хранится в отдельной ветви, доступ к которой можно получить через атрибут branch. Ветвь содержит копию набора данных, а также все преобразователи и модели, которые соответствуют этому конкретному набору данных. Методы, вызываемые из ATOM, всегда используют набор данных в текущей ветви, а также атрибуты данных, такие как atom.dataset. По умолчанию ATOM начинается с одной вызываемой ветки master. Отбратитесь к ветви, чтобы узнать о содержащихся в ней преобразователях и моделях.
atom.branch
Branch: master
--> Pipeline:
>>> FeatureSelector
--> strategy: RFE
--> solver: RandomForestClassifier(n_jobs=1, random_state=1)
--> n_features: 12
--> max_frac_repeated: 1.0
--> max_correlation: 1.0
--> kwargs: {}
--> Models: RF
Текущая ветвь содержит класс для выбора функций, который мы вызвали ранее, а также модель, которую мы только что обучили.
Передискретизация
Теперь пора проверить, как модель будет работать после передискретизации набора данных. Здесь мы создаем новую ветку с именем oversample.
atom.branch = "oversample"
New branch oversample successfully created!
ПРИМЕЧАНИЕ. Создание новой ветки автоматически изменяет текущую ветвь на новую. Для переключения между существующими ветвями просто введите имя нужной ветки, например, atom.branch = "master" чтобы вернуться к главной ветке.
Ветвь избыточной выборки отделяется от текущей ветви (ведущей), принимая ее набор данных и преобразователи. Это означает, что преобразователь выбора функции теперь также является этапом конвейера передискретизации. Такое разделение ветвей позволяет избежать пересчета предыдущих преобразований.
Вызовите метод balance для передискретизации набора данных с помощью SMOTE.
atom.balance(strategy="smote")
Oversampling with SMOTE...
--> Adding 7102 samples to class: 1.
Помните, что этот метод преобразует только набор данных в текущей ветви. Набор данных в главной ветке не изменился. Быстро проверьте, сработало ли преобразование.
atom.classes
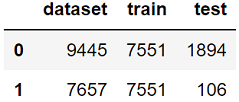
Обратите внимание, что сбалансирован только обучающий набор, поскольку мы хотим сохранить исходное распределение классов в тестовом наборе.
Теперь мы можем обучить модель Random Forest на наборе данных с избыточной выборкой. Чтобы отличить эту модель от первой, которую мы обучили, мы добавляем тег (os для избыточной выборки) после аббревиатуры модели.
atom.run(models="RF_os", metric="balanced_accuracy")
Training ===================================== >>
Models: RF_os
Metric: balanced_accuracy
Results for Random Forest:
Fit ---------------------------------------------
Train evaluation --> balanced_accuracy: 1.0
Test evaluation --> balanced_accuracy: 0.7737
Time elapsed: 1.325s
-------------------------------------------------
Total time: 1.325s
Final results ========================= >>
Duration: 1.341s
------------------------------------------
Random Forest --> balanced_accuracy: 0.7737
Недостаточная дискретизация
Требуется новая ветка, чтобы уменьшить выборку данных. Поскольку текущая ветвь содержит набор данных с избыточной дискретизацией, мы должны отделить новую ветвь от основной ветки, которая содержит только преобразователь RFE.
atom.branch = "undersample_from_master"
New branch undersample successfully created!
Добавьте _from_ между новой ветвью и существующей, чтобы отделить ее от этой, а не от текущей ветви. Убедитесь, что набор данных в ветви недостаточной дискретизации все еще несбалансирован.
atom.classes
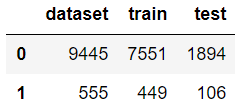
Вызовите метод balance еще раз, чтобы уменьшить выборку данных с помощью NearMiss.
atom.balance(strategy="NearMiss")
Undersampling with NearMiss...
--> Removing 7102 samples from class: 0.
И подгоните Random Forest с помощью нового тега (используется для подвыборки).
atom.run(models="RF_us", metric="balanced_accuracy")
Training ===================================== >>
Models: RF_us
Metric: balanced_accuracy
Results for Random Forest:
Fit ---------------------------------------------
Train evaluation --> balanced_accuracy: 1.0
Test evaluation --> balanced_accuracy: 0.6888
Time elapsed: 0.189s
-------------------------------------------------
Total time: 0.189s
Final results ========================= >>
Duration: 0.189s
------------------------------------------
Random Forest --> balanced_accuracy: 0.6888
Если мы сейчас посмотрим на нашу ветку, мы увидим, что конвейер содержит только два преобразования, которые мы хотим.
atom.branch
Branch: undersample
--> Pipeline:
>>> FeatureSelector
--> strategy: RFE
--> solver: RandomForestClassifier(n_jobs=1, random_state=1)
--> n_features: 12
--> max_frac_repeated: 1.0
--> max_correlation: 1.0
--> kwargs: {}
>>> Balancer
--> strategy: NearMiss
--> kwargs: {}
--> Models: RF_us
Анализируйте результаты
Наконец-то у нас есть три модели, которые мы хотели в нашем экземпляре атома. Система ветвления теперь выглядит следующим образом.
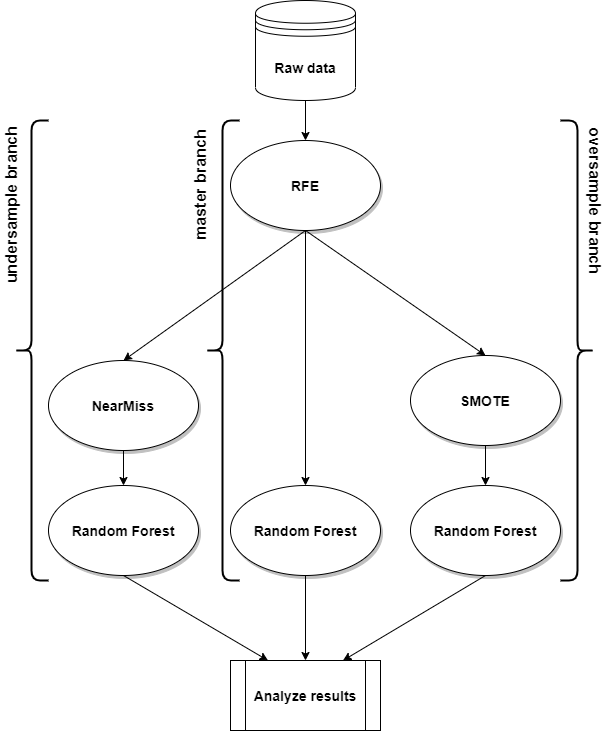
Преобразование RFE разделяется между тремя ветвями, но после этого каждая ветвь идет своим путем. Основная ветвь не имеет дополнительных преобразователей, в то время как две другие ветви применяют разные алгоритмы балансировки. Все три ветви содержат модель Random Forest, каждая из которых обучена на отдельном наборе данных. Осталось только сравнить результаты.
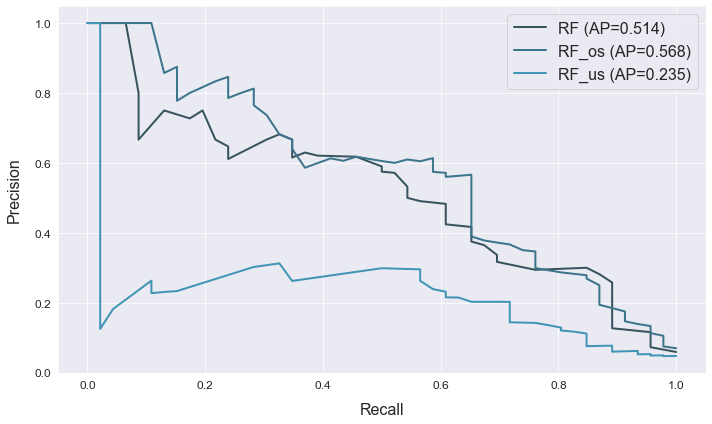
atom.scoring()

atom.plot_prc()
Заключение
Мы узнали, как использовать пакет ATOM, чтобы легко сравнивать несколько конвейеров машинного обучения. Наличие всех конвейеров (и, следовательно, моделей) в одном экземпляре ATOM дает несколько преимуществ:
- Код короче, что позволяет меньше загромождать блокнот и упрощает обзор.
- Преобразования, общие для конвейеров, не нужно пересчитывать.
- Это упрощает сравнение результатов с использованием методов построения ATOM.
Пример, который мы рассмотрели, довольно минималистичен, но ATOM способен на гораздо большее! Для получения дополнительной информации просмотрите документацию к пакету.