Как включить мощный полнотекстовый поиск для ваших приложений - MySQL против Elasticsearch

Вы когда-нибудь ходили в супермаркет или универмаг, но не могли найти то, что искали? Вы можете испытать то же самое, когда дело доходит до покупок в Интернете. Хотя большинство веб-сайтов упорядочивают продукты по категориям, просмотр категорий по-прежнему является утомительной работой, если вы не имеете представления о категории ваших целевых продуктов. Панель поиска экономит нам много времени, поскольку мы можем просто ввести ключевые слова или текстовые фразы, и тогда она покажет нам все соответствующие элементы. Без сомнения, полнотекстовый поиск - важная функция для всех веб-сайтов электронной коммерции.
Полнотекстовый поиск - популярная функция, поддерживаемая многими базами данных, такими как MySQL и Elasticsearch. Однако в чем разница между MySQL и Elasticsearch в отношении возможности полнотекстового поиска? Вы не можете принять правильное решение, не понимая различий, если ищете решение для реализации полнотекстового поиска. В этой статье я покажу вам использование полнотекстового поиска в MySQL и Elasticsearch и выделю различия.
Что такое полнотекстовый поиск?
Вы вряд ли получите какие-либо результаты поиска, если поисковые системы будут искать записи данных по точному совпадению. Например, приведенный ниже оператор SQL вряд ли вернет какие-либо записи, потому что, вероятно, не существует такого продукта с названием или описанием, точно таким же, как текстовая фраза «canned food with fish and tomato» в названии или описании.
SELECT *
FROM products
WHERE name = ‘canned food with fish and tomato’
OR description = ‘canned food with fish and tomato’
Это может немного помочь, если мы будем использовать подстановочный знак «LIKE%», но вы будете получать только те записи, которые содержат точную текстовую фразу в полях данных.
SELECT *
FROM products
WHERE name LIKE ‘%canned food with fish and tomato%’
OR description LIKE ‘%canned food with fish and tomato%’
Идея полнотекстового поиска состоит в том, чтобы разбивать текстовые фразы на токены. Текстовая фраза в приведенном выше примере разбита на следующие токены: «консервы», «еда», «с», «рыба», «и» и «помидоры». Затем поисковые системы ищут все записи, соответствующие любому из токенов. Чем больше токенов соответствует записи, тем больше она релевантна текстовой фразе. Следовательно, поисковые системы указывают на релевантность, выставляя оценку в результатах поиска. Вы можете получить результат поиска с огромным количеством записей, если токены в строке запроса содержат общие слова, такие как «еда», и многие продукты могут соответствовать одному или нескольким токенам. Однако вы всегда можете отфильтровать результат по баллам, чтобы получить наиболее релевантные записи.
Полнотекстовый поиск - популярная функция, поддерживаемая многими базами данных, такими как MySQL и Elasticsearch. На самом деле настройка для включения этой функции довольно проста и понятна. Например, вы можете включить функцию полнотекстового поиска для выбранных полей данных в MySQL, не внося никаких изменений в схему таблицы. Когда дело доходит до Elasticsearch, это еще проще, потому что он по умолчанию поддерживает полнотекстовый поиск, не нужно беспокоиться о какой-либо дополнительной настройке.
Краткий обзор полнотекстового поиска - MySQL против Elasticsearch
Короче говоря, и MySQL, и Elasticsearch разделяют схожие идеи полнотекстового поиска. Он предназначен для создания индексов путем разложения текстового содержимого на токены. Затем запрос разбивает текст запроса на токены и сопоставляет его с индексами. На основе результата сопоставления поисковые системы вычисляют оценку и присваивают результату поиска, который представляет релевантность.
Ключевым отличием является подход к решению между фиксированным решением и настраиваемым. MySQL предлагает фиксированную функцию полнотекстового поиска в 3 различных режимах - естественный язык, логический запрос и расширенный запрос. Это оставляет мало места для регулировки и точной настройки.
Напротив, дизайн Elasticsearch легко настраивается. Процесс декомпозиции токена и выполнения запроса выполняется на основе набора анализаторов, токенизаторов и фильтров. Эти компоненты можно настроить и собрать вместе, чтобы реализовать более сложные функции.
У меня будет пошаговое руководство по использованию полнотекстового поиска в MySQL и Elasticsearch.
Образец набора данных
Демонстрация функций полнотекстового поиска основана на образце набора данных, который представляет собой набор записей библиотечной книги. Схема довольно проста со следующими столбцами: id, title и publishingPlace.

MySQL
Выполните приведенные ниже операторы SQL, чтобы создать таблицу библиотечной книги и импортировать образцы данных.
CREATE TABLE `library-book` (
`id` int(11) NOT NULL,
`title` text COLLATE utf8_unicode_ci,
`publicationPlace` text COLLATE utf8_unicode_ci
);
INSERT INTO `library-book` (`id`, `title`, `publicationPlace`) VALUES ('1', 'How To Grow Your Own Fruit and Veg: A Week-by-week Guide to Wild-life Friendly Fruit and Vegetable Gardening - Recipes Of Natural Balance Gardening', 'London');
INSERT INTO `library-book` (`id`, `title`, `publicationPlace`) VALUES ('2', 'The Life of God in the Soul of the Church: The Root and Fruit of Spiritual Fellowship', 'Edinburgh');
INSERT INTO `library-book` (`id`, `title`, `publicationPlace`) VALUES ('3', 'Fruit and vegetable production in Africa - The important fruits are bananas, pineapples, dates, figs, olives, and citrus; the principal vegetables include tomatoes and onions', 'London');
INSERT INTO `library-book` (`id`, `title`, `publicationPlace`) VALUES ('4', 'Silver fruit upon silver trees', 'London');
INSERT INTO `library-book` (`id`, `title`, `publicationPlace`) VALUES ('5', 'A life to live', 'New York');
INSERT INTO `library-book` (`id`, `title`, `publicationPlace`) VALUES ('6', 'The emergency medical services in Edinburgh', 'New York');
INSERT INTO `library-book` (`id`, `title`, `publicationPlace`) VALUES ('7', 'SIMPLE GREEN SUPPERS: A FRESH STRATEGY FOR ONE-DISH VEGETARIAN MEALS BY SUSIE MIDDLETON - Delicious Dishes And Unusual Herb Recipes', 'Auckland');
INSERT INTO `library-book` (`id`, `title`, `publicationPlace`) VALUES ('8', 'Good Food For Bad Days - Tasty vegan meals really don''t have to take all the time in the world or grand ingredients', 'Edinburgh');
MySQL нуждается в настройке индекса для полнотекстового поиска, выполните приведенную ниже инструкцию, чтобы создать полнотекстовый индекс для 'title' и 'publishingPlace', предполагая, что читатели заинтересованы в поиске книг на основе этих двух полей данных.
ALTER TABLE `library`.`books` ADD FULLTEXT `book_free_text_index` (`title`, `publicationPlace`);
Elasticsearch
Все операции CRUD в Elasticsearch выполняются с помощью вызовов REST API. Чтобы загрузить тот же набор записей образцов книги в Elasticsearch, запустите команду curl ниже, которая отправляет запрос POST для массовой вставки данных.
В отличие от MySQL, Elasticsearch - это база данных NoSQL, вставка данных может выполняться без предварительного создания схемы таблицы. «Индекс» в Elasticsearch означает базу данных в реляционной базе данных, он автоматически создает индекс, называемый «library-book», как указано в запросе, если он еще не существует. Кроме того, нет необходимости создавать индекс полнотекстового поиска, поскольку Elasticsearch разбивает текстовое содержимое на токены и сохраняет его в индексе во время процесса вставки или обновления данных.
curl --request POST \
--url 'http://localhost:9200/_bulk?pretty=' \
--header 'Content-Type: application/json' \
--data '{ "index" : { "_index" : "library-book", "_type" : "_doc", "_id" : "1" } }
{ "title" : "How To Grow Your Own Fruit and Veg: A Week-by-week Guide to Wild-life Friendly Fruit and Vegetable Gardening - Recipes Of Natural Balance Gardening", "publicationPlace": "London"}
{ "index" : { "_index" : "library-book", "_type" : "_doc", "_id" : "2" } }
{ "title" : "The Life of God in the Soul of the Church: The Root and Fruit of Spiritual Fellowship", "publicationPlace": "Edinburgh" }
{ "index" : { "_index" : "library-book", "_type" : "_doc", "_id" : "3" } }
{ "title" : "Fruit and vegetable production in Africa - The important fruits are bananas, pineapples, dates, figs, olives, and citrus; the principal vegetables include tomatoes and onions", "publicationPlace": "London"}
{ "index" : { "_index" : "library-book", "_type" : "_doc", "_id" : "4" } }
{ "title" : "Silver fruit upon silver trees", "publicationPlace": "London" }
{ "index" : { "_index" : "library-book", "_type" : "_doc", "_id" : "5" } }
{ "title" : "A life to live", "publicationPlace": "New York" }
{ "index" : { "_index" : "library-book", "_type" : "_doc", "_id" : "6" } }
{ "title" : "The emergency medical services in Edinburgh", "publicationPlace": "New York" }
{ "index" : { "_index" : "library-book", "_type" : "_doc", "_id" : "7" } }
{ "title" : "SIMPLE GREEN SUPPERS: A FRESH STRATEGY FOR ONE-DISH VEGETARIAN MEALS BY SUSIE MIDDLETON - Delicious Dishes And Unusual Herb Recipes", "publicationPlace": "Auckland" }
{ "index" : { "_index" : "library-book", "_type" : "_doc", "_id" : "8" } }
{ "title" : "Good Food For Bad Days - Tasty vegan meals really don'\''t have to take all the time in the world or grand ingredients", "publicationPlace": "Edinburgh" }
Простой поиск по ключевым словам
Начнем с простого поиска, допустим, мы ищем одно ключевое слово «edinburgh».
MySQL
Чтобы найти все записи, соответствующие этому ключевому слову, используйте match() в MySQL для выполнения полнотекстового запроса в логическом режиме. Запустите этот оператор SQL, чтобы найти «edinburgh».
SELECT id, title, publicationPlace,
MATCH (title, publicationPlace) AGAINST ('edinburgh' IN BOOLEAN MODE) AS score
FROM `library-book`
ORDER BY score DESC
Результат поиска присваивает каждой записи оценку, чтобы показать актуальность. Чем выше оценка, тем больше запись релевантна ключевому слову. Есть 3 записи с оценкой > 0 как название и публикация, которые соответствуют ключевому слову «edinburgh», в то время как другие записи не соответствуют ключевому слову, поэтому присваивается НУЛЕВОЙ балл.

Elasticsearch
Elasticsearch поддерживает широкий спектр методов запроса, таких как ключевое слово, текстовая фраза, префикс и т.д. В этом примере мы используем тип запроса «multi_match» для поиска по нескольким полям данных - «title» и «publishingPlace». Отправьте этот запрос POST для поиска по ключевому слову «edinburgh».
curl --request POST \
--url http://localhost:9200/library-book/_search \
--header 'Content-Type: application/json' \
--data '{
"query": {
"multi_match": {
"query": "edinburgh",
"fields": [
"title",
"publicationPlace"
]
}
}
}'
Результат совпадает с результатом MySQL. 3 записи соответствуют ключевому слову «edinburgh», но присвоенные оценки не совпадают из-за другого механизма расчета релевантности в Elasticsearch.

Оценка точной настройки на основе указанных полей данных
Для некоторых случаев использования определенные поля данных более важны, и совпадениям ключевых слов в этих полях следует давать более высокий балл. Хотя MySQL не предлагает такой гибкости, ее можно достичь в Elasticsearch, добавив в поле данных символ вставки «^». В приведенном здесь примере показано, что поле «заголовок» в 3 раза важнее.
curl --request POST \
--url http://localhost:9200/library-book/_search \
--header 'Content-Type: application/json' \
--data '{
"query": {
"multi_match": {
"query": "edinburgh",
"fields": [
"title^3",
"publicationPlace"
]
}
}
}'Поскольку «заголовок» более важен, записи с полем «заголовок», совпадающим с ключевым словом, получают более высокий балл.

Поиск с логическими условиями
Вы можете указать определенные критерии поиска, такие как И / ИЛИ / НЕ. Скажем, мы хотим найти книги, которые соответствуют ключевым словам «life» и «live». Для этого мы добавляем символ «+» перед каждым ключевым словом, чтобы указать, что это условие «И».
MySQL
BOOLEAN режим, предоставляемый MySQL, поддерживает запросы с логическими условиями. Давайте искать книги по ключевым словам «life» и «live».
SELECT id, title, publicationPlace,
MATCH (title, publicationPlace) AGAINST ('+life +live' IN BOOLEAN MODE) AS score
FROM `library-book`
ORDER BY score DESC;Сейчас актуальна только книга «A life to live» с оценкой > 0, а все остальные книги с оценкой = 0.

Логический режим поддерживает не только оператор AND (+), но и другие символы, такие как NOT (~), более высокую релевантность (>), более низкую релевантность (<) и т.д. За подробностями обращайтесь к официальной документации MySQL.
Elasticsearch
Тот же набор символов можно применить к Elasticsearch. Мы можем использовать тип запроса «simple_query_string» в запросе POST для текстовой фразы с логическими условиями.
curl --request POST \
--url http://localhost:9200/library-book/_search \
--header 'Content-Type: application/json' \
--data '{
"query": {
"simple_query_string": {
"query": "+life +live",
"fields": [
"title",
"publicationPlace"
]
}
}
}'
Результат показывает только одну запись, и он такой же, как результат MySQL.

Поиск текстовой фразы
Каков результат поиска текстовой фразы, скажем, «Recipes Of A Delicious And Tasty Meal»? Поскольку текстовая фраза разбита на лексемы в нижнем регистре «recipes», «of», «a», «delicious», «and», «tasty» и «meal». Записи соответствуют большему количеству токенов, что означает, что они более релевантны текстовой фразе.
Люди обычно набирают текстовые фразы для запросов на человеческом языке. Принимая во внимание человеческий язык, для получения точных результатов необходимо особое внимание. Например, сопоставление тех слов, которые часто встречаются в английском языке, таких как «a», «an», «of», «the» и т.д., вряд ли приведет к значимым результатам. Эти слова называются «стоп-словами», поисковые системы должны игнорировать их в запросах текстовых фраз.
MySQL
MySQL поддерживает режим естественного языка, который игнорирует «стоп-слова» и выполняет поиск без учета регистра. Запустите этот оператор запроса, чтобы найти текстовую фразу.
SELECT id, title, publicationPlace,
MATCH (title, publicationPlace) AGAINST ('Recipes Of A Delicious And Tasty Meal' IN NATURAL LANGUAGE MODE) AS score
FROM `library-book`
ORDER BY score DESC;
Первые 3 записи с наибольшим количеством очков соответствуют большинству токенов во фразе поискового текста.

Elasticsearch
Настройки индекса по умолчанию Elasticsearch не содержат таких функций, как режим естественного языка, предлагаемых MySQL.
Вы увидите другой результат, когда отправите этот POST-запрос в Elasticsearch для поиска той же текстовой фразы.
curl --request POST \
--url http://localhost:9200/library-book/_search \
--header 'Content-Type: application/json' \
--data '{
"query": {
"multi_match": {
"query": "Recipes Of A Delicious And Tasty Meal",
"fields": [
"title",
"publicationPlace"
]
}
}
}'
Настройки по умолчанию учитывают стоп-слова при сопоставлении и подсчете очков. В результате результат поиска с наивысшим баллом, совпадающим с большинством стоп-слов, таких как «of» и «and», по-видимому, не имеет отношения к делу.
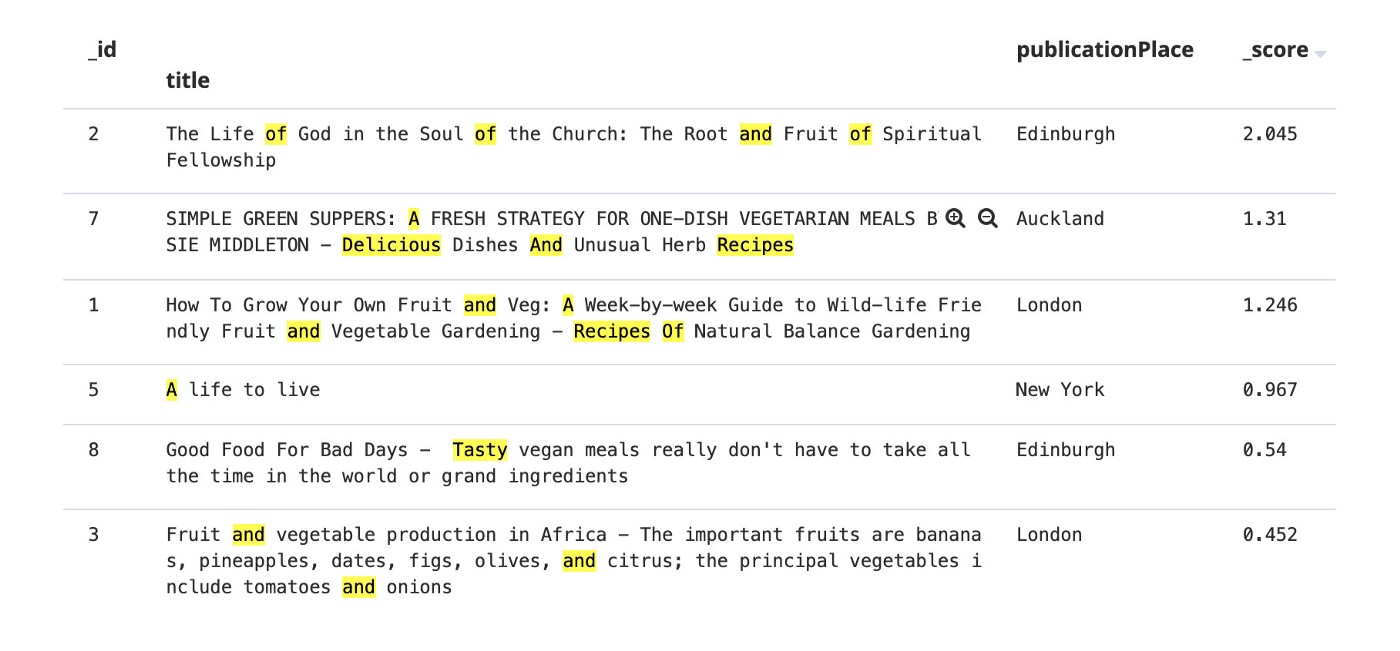
Не беспокойтесь, Elasticsearch на самом деле является очень мощной поисковой системой, поддержка поиска на естественном языке может быть осуществлена путем настройки фильтров токенов для стоп-слов в настройках индекса.
Elasticsearch предлагает 15 токензеров и более 50 фильтров токенов, которые подходят для различных сценариев использования. Чтобы добиться полнотекстового поиска, аналогичного MySQL, достаточно просто добавить в анализатор фильтр маркеров стоп-слов. На схеме ниже показано, что анализатор состоит из следующих компонентов:
- Стандартный анализатор - Разложите текстовую фразу на токены
- Фильтр токенов в нижнем регистре - преобразование токенов в нижний регистр для поиска без учета регистра
- Фильтр маркеров стоп-слов - удалите маркеры общих слов, таких как «of», «a», «and» и т.д.
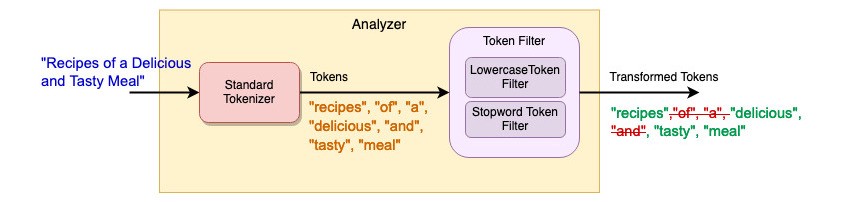
Анализатор настраивается в настройках индекса и сопоставляется с полями данных «title» и «publishingPlace».
Отправьте этот запрос PUT, чтобы создать новый индекс с названием «library-book-text-phrase» (т.е. База данных в Elasticsearch) с новой конфигурацией анализатора и сопоставлением полей.
curl --request PUT \
--url http://localhost:9200/library-book-text-phrase \
--header 'Content-Type: application/json' \
--data '
{
"settings": {
"analysis": {
"analyzer": {
"english_analyzer": {
"tokenizer": "standard",
"filter": ["lowercase", "english_stop_filter"]
}
},
"filter": {
"english_stop_filter": {
"type": "stop",
"stopwords": "_english_"
}
}
}
},
"mappings": {
"_doc": {
"properties": {
"title": {
"type": "text",
"analyzer": "english_analyzer"
},
"description": {
"type": "text",
"analyzer": "english_analyzer"
},
"publicationPlace": {
"type": "text",
"analyzer": "keyword"
}
}
}
}
}'
Затем отправьте этот запрос POST для копирования данных из исходного индекса «library-book» во вновь созданный индекс «library-book-text-phrase».
curl --request POST \
--url 'http://localhost:9200/_reindex \
--header 'Content-Type: application/json' \
--data '{
"source": {
"index": "library-book"
},
"dest": {
"index": "library-book-text-phrase"
}
}'
Давайте запустим тот же запрос по новому индексу «library-book-text-phrase». Теперь результат имеет больше смысла.
curl --request POST \
--url http://localhost:9200/library-book-text-phrase/_search \
--header 'Content-Type: application/json' \
--data '{
"query": {
"multi_match": {
"query": "Recipes Of A Delicious And Tasty Meal",
"fields": [
"title",
"publicationPlace"
]
}
}
}'

MySQL - Расширьте критерии поиска
Мощная поисковая система способна не только выполнять поиск по соответствию токенов, но также понимать ключевые слова и расширять поиск других ключевых слов с аналогичным значением. Например, ожидается, что поисковые системы должны искать записи, которые соответствуют другим аналогичным ключевым словам, таким как «timber», «lumber» и «trees», при поиске по ключевому слову «woods».
MySQL может угадать, что вы ищете, используя режим «QUERY EXPANSION».
SELECT id, title, publicationPlace,
MATCH (title, publicationPlace) AGAINST ('green' WITH QUERY EXPANSION) AS score
FROM `library-book`
ORDER BY score DESC
Когда мы ищем ключевое слово «зеленый». Будут возвращены 3 записи. Поле заголовка 2-й и 3-й записи на самом деле не содержит ключевого слова «green», но поисковая система каким-то образом предполагает, что содержание этой записи имеет отношение к ключевому слову «green».

Однако результаты поиска будут содержать больше «шума», если мы добавим больше ключевых слов в критерии поиска. Практически все книжные записи попадают в текстовую фразу «a good life» при поиске в режиме расширения запроса.
Невозможно точно настроить результат поиска, если вас не устраивает точность.
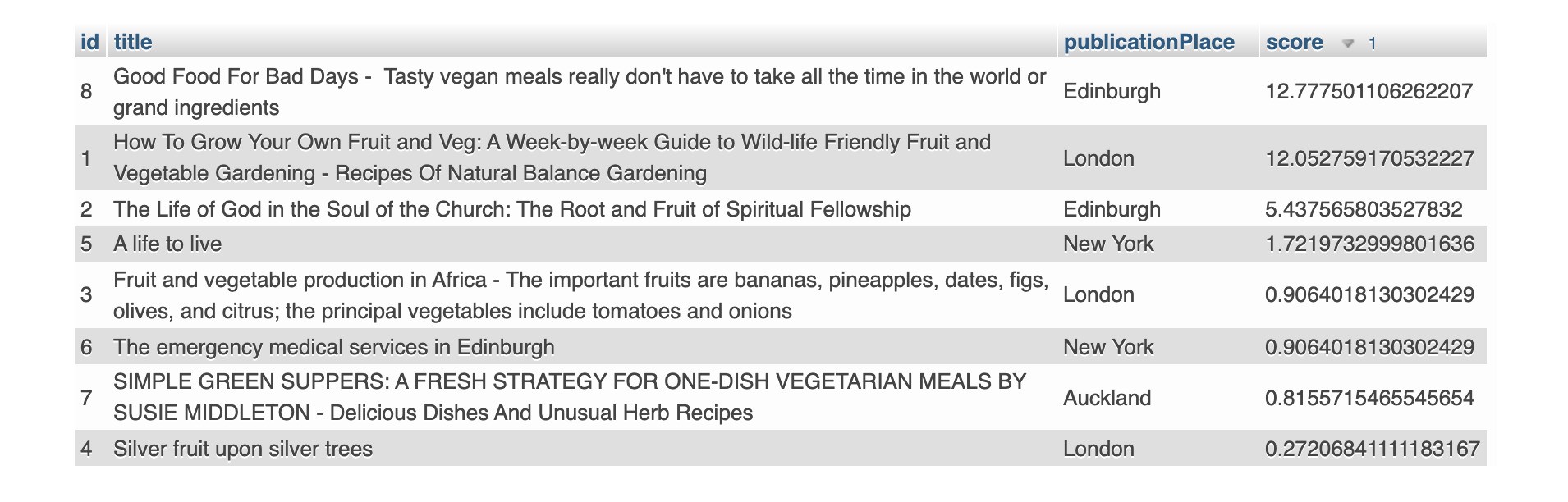
Elasticsearch - расширенный поиск с использованием фильтра токенов синонимов
Elasticsearch предлагает несколько способов выполнить расширенный поиск, аналогичный режиму расширения, поддерживаемому MySQL. Вместо того, чтобы предоставлять фиксированное решение, использование токен-фильтров позволяет реализовать расширенный полнотекстовый поиск.
Давайте посмотрим на поддержку поиска по синонимам. Мы настраиваем фильтр токенов так, чтобы он расширял поиск до синонимов. Мы используем бесплатную лексическую базу данных WordNet. В целом в нем хранится более 20 тыс. слов и сопоставление с синонимами.
Конфигурация заключается в добавлении нового фильтра токенов для синонимов, и фильтр считывает сопоставления синонимов из файла WordNet.
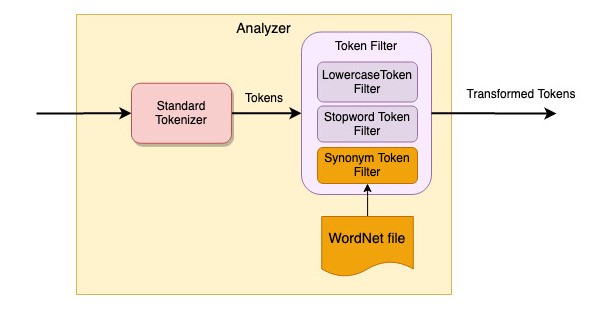
Чтобы включить новые настройки индекса, загрузите файл WordNet и скопируйте его в elasticsearch/config/analysis, затем отправьте этот запрос PUT, чтобы создать новый индекс под названием «library-book-synonym-wordnet».
curl --request PUT \
--url http://localhost:9200/library-book-synonym-wordnet \
--header 'Content-Type: application/json' \
--data '
{
"settings": {
"analysis": {
"analyzer": {
"english_analyzer": {
"tokenizer": "standard",
"filter": ["lowercase", "english_stop_filter", "synonym_filter"]
}
},
"filter": {
"english_stop_filter": {
"type": "stop",
"stopwords": "_english_"
},
"synonym_filter": {
"type": "synonym",
"format": "wordnet",
"lenient": true,
"synonyms_path": "analysis/wn_s.pl"
},
}
}
},
"mappings": {
"_doc": {
"properties": {
"title": {
"type": "text",
"analyzer": "english_analyzer"
},
"description": {
"type": "text",
"analyzer": "english_analyzer"
},
"publicationPlace": {
"type": "text",
"analyzer": "keyword"
}
}
}
}
}'
Затем отправьте этот запрос POST для копирования данных из исходного индекса «library-book» во вновь созданный индекс «library-book-synonym-wordnet».
curl --request POST \
--url 'http://localhost:9200/_reindex' \
--header 'Content-Type: application/json' \
--data '{
"source": {
"index": "library-book"
},
"dest": {
"index": "library-book-synonym-wordnet"
}
}'
Теперь найдите ключевое слово «green» в новом индексе. Затем вы получите список записей, который соответствует синониму «green».
curl --request POST \
--url http://localhost:9200/library-book-synonym-wordnet/_search \
--header 'Content-Type: application/json' \
--data '{
"query": {
"multi_match": {
"query": "green",
"fields": [
"title",
"publicationPlace"
]
}
}
}'
Результат:

Фильтр синонимов токенов Elasticsearch с настраиваемыми сопоставлениями слов
Elasticsearch поддерживает настраиваемое сопоставление синонимов, если WordNet не соответствует вашим потребностям. Мы настраиваем фильтр токенов синонимов так, чтобы он сопоставлял ключевое слово «fruit» со списком ключевых слов - «banana», «pineapple», «date», «fig», «olive» и «citrus». Следовательно, поиск по ключевому слову «banana» будет соответствовать любым записям с «fruit».
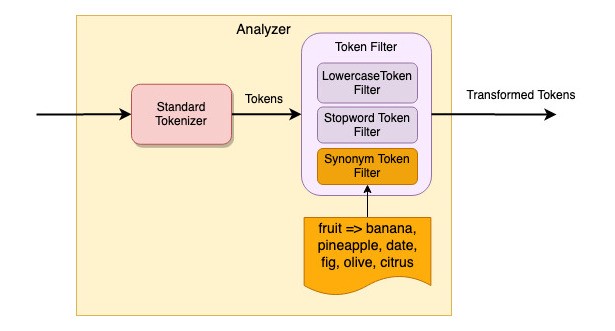
Отправьте этот запрос PUT, чтобы создать новый индекс и настраиваемый анализатор с фильтром токенов «synonym_filter».
curl --request PUT \
--url http://localhost:9200/library-book-custom-synonym \
--header 'Content-Type: application/json' \
--data '
{
"settings": {
"analysis": {
"analyzer": {
"english_analyzer": {
"tokenizer": "standard",
"filter": ["lowercase", "english_stop_filter", "synonym_filter"]
}
},
"filter": {
"english_stop_filter": {
"type": "stop",
"stopwords": "_english_"
},
"synonym_filter": {
"type": "synonym",
"lenient": true,
"synonyms": [
"fruit => banana, pineapple, date, fig, olive, citrus"
]
},
}
}
},
"mappings": {
"_doc": {
"properties": {
"title": {
"type": "text",
"analyzer": "english_analyzer"
},
"description": {
"type": "text",
"analyzer": "english_analyzer"
},
"publicationPlace": {
"type": "text",
"analyzer": "keyword"
}
}
}
}
}'
После копирования данных во вновь созданный индекс отправьте этот запрос POST для поиска по ключевому слову «banana». Затем вы увидите, что результат содержит все записи, соответствующие ключевому слову «fruit».
curl --request POST \
--url http://localhost:9200/library-book-custom-synonym/_search \
--header 'Content-Type: application/json' \
--data '{
"query": {
"bool": {
"must": [
{
"multi_match": {
"query": "banana"
}
}
]
}
}
}'
Результат:

Последние мысли
И MySQL, и Elasticsearch предоставляют мощные возможности полнотекстового поиска. Если ваша система использует MySQL в качестве хранилища данных, функцию полнотекстового поиска можно быстро включить, создав полнотекстовые индексы для целевых полей данных. Решение отлично работает для большинства случаев использования, поскольку оно предлагает пользователям быстрый способ поиска ключевых слов и текстовых фраз в нескольких полях данных. Однако, когда дело доходит до точной настройки и настройки результатов поиска, в MySQL доступны ограниченные возможности. Следовательно, Elasticsearch, вероятно, является лучшим вариантом для расширенных функций и индивидуального поведения поиска, поскольку решение легко настраивается и гораздо более гибкое.