Когда "Zoë" !== "Zoë". Или зачем вам нужно нормализовать строки Unicode?
Никогда не слышал о нормализации Unicode? Ты не одинок. Но это избавит вас от многих неприятностей.
Рано или поздно, это поражает каждого разработчика:
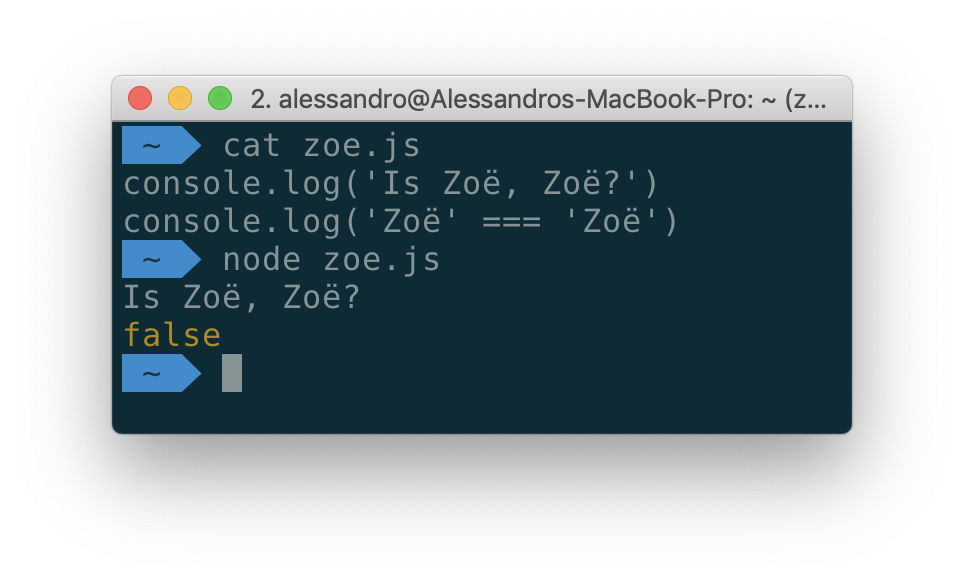
Это не одна из странностей JavaScript, я мог бы показать вам тот же результат с кодом практически на любом другом языке программирования, включая Python, Go и даже сценарии оболочки.
Впервые это случилось со мной много лет назад, когда я создавал приложение (в Objective-C), которое импортировало список людей из адресной книги пользователя и социальных сетей, в конце отфильтровывая дубликаты. В некоторых ситуациях один и тот же человек добавлялся дважды, потому что имена не сравнивались бы как одинаковые строки.
На самом деле, хотя две приведенные выше строки на экране выглядят одинаково, способ их представления на диске, байты, сохраненные в файле, различны. В первом «Zoë» символ «ë» (e с умлаутом) представлял собой единую кодовую точку Unicode, а во втором случае он был в разложенном виде. Если вы имеете дело со строками Unicode в своем приложении, вы должны принять во внимание, что символы могут быть представлены несколькими способами.
Как мы добрались до смайликов: краткое объяснение кодировки символов
Компьютеры работают с байтами, которые являются просто числами. Чтобы иметь возможность представлять текст, мы сопоставляем каждый символ с определенным числом, и у нас есть соглашения о том, как их отображать.
Первым из таких соглашений или кодировок символов был ASCII (американский стандартный код для обмена информацией). Он использует 7 бит и может представлять в общей сложности 128 символов, включая латинский алфавит (как в верхнем, так и в нижнем регистре), цифры и основные знаки пунктуации. Он также включает в себя набор «непечатных» символов, таких как перевод строки, табуляция, возврат каретки и т.д. Например, в стандарте ASCII буква M (заглавная буква m) кодируется как число 77 (4D в шестнадцатеричном формате).
Проблема в том, что 128 символов может быть достаточно для представления всех символов, которые обычно используют носители английского языка, но это на порядок меньше, чтобы представлять каждый символ каждого сценария по всему миру, включая эмодзи 😫
Решение состояло в том, чтобы принять стандарт под названием Unicode с целью включения каждого символа каждого современного и исторического сценария, а также различных символов. Unicode 12.0 был выпущен всего несколько дней назад и содержит более 137 000 символов.
Юникод может быть реализован в нескольких стандартах кодирования символов. Наиболее распространенными являются UTF-8 и UTF-16; в сети UTF-8 значительно более популярен.
UTF-8 использует от 1 до 4 байтов для представления всех символов. Это расширенный набор ASCII, поэтому первые 128 символов идентичны символам в таблице ASCII. С другой стороны, UTF-16 использует от 2 до 4 байтов.
Зачем использовать оба? Западные языки, как правило, наиболее эффективно кодируются с помощью UTF-8 (поскольку большинство символов будут представлены только одним байтом), в то время как азиатские языки обычно могут создавать файлы меньшего размера при использовании UTF-16 в качестве кодировки.
Кодовые точки Unicode и кодировка символов
Каждому символу в стандарте Unicode присваивается идентификационный номер или кодовая точка. Например, смайлик собаки имеет кодовую точку U + 1F436.
При кодировании собачьи эмодзи могут быть представлены в нескольких байтовых последовательностях:
- UTF-8: 4 bytes,
0xF0 0x9F 0x90 0xB6 - UTF-16: 4 bytes,
0xD83D 0xDC36
В исходном файле JavaScript следующие три оператора выводят один и тот же результат, заполняя вашу консоль большим количеством щенков:
// Это включает в себя последовательность байтов в файле
console.log('🐶') // => 🐶
// Это использует кодовую точку Unicode (ES2015 и новее)
console.log('\u{1F436}') // => 🐶
// При этом используется представление UTF-16 с двумя кодовыми единицами (каждый из 2 байтов).
console.log('\uD83D\uDC36') // => 🐶Большинство интерпретаторов JavaScript (включая Node.js и современные браузеры) используют UTF-16 для внутреннего использования. Это означает, что собачьи эмодзи хранятся с использованием двух кодовых единиц UTF-16 (по 16 бит каждая). Итак, это не должно вас удивлять
console.log('🐶'.length) // => 2Объединение персонажей
Это возвращает нас к тому, что наши персонажи выглядят одинаково, но имеют разные представления.
Некоторые символы в кодировке Unicode объединяют символы, предназначенные для изменения других символов. Например:
n + ˜ = ñu + ¨ = üe + ´ = é
Не все комбинирующие символы добавляют диакритические знаки. Например, лигатуры позволяют присоединить ae к æ, или ffi в ffi.
Проблема в том, что некоторые из этих символов могут быть представлены несколькими способами.
Например, символ é может быть представлено с помощью:
- Одна кодовая точка U + 00E9
- Сочетание буквы
eи острого акцента, в сумме две кодовые точки: U + 0065 и U + 0301
Два символа выглядят одинаково, но не сравниваются как одинаковые, а строки имеют разную длину. В JavaScript:
console.log('\u00e9') // => é
console.log('\u0065\u0301') // => é
console.log('\u00e9' == '\u0065\u0301') // => false
console.log('\u00e9'.length) // => 1
console.log('\u0065\u0301'.length) // => 2Это может привести к непредвиденным ошибкам, таким как записи, не найденные в базе данных, несоответствие паролей, что делает невозможным аутентификацию пользователей и т.д.
Нормализующие строки
К счастью, есть простое решение, которое переводит строку в «каноническую форму».
Существует четыре стандартных формы нормализации:
NFC: Нормализация формы канонического составаNFD: Нормализация формы канонического разложенияNFKC: Форма совместимости формы нормализацииNFKD: Разложение совместимости форм нормализации
Наиболее распространенным из них является NFC, то есть сначала все символы разлагаются, а затем все объединяющие последовательности перестраиваются в определенном порядке, как определено стандартом. Вы можете выбрать любую форму, какую пожелаете, если вы последовательны, один и тот же ввод всегда приводит к одному и тому же результату.
JavaScript предлагает встроенный метод String.prototype.normalize([form]) с ES2015 (ранее известный как ES6), который теперь доступен в Node.js и во всех современных веб-браузерах. Аргументом является строка form, идентификатор формы нормализации, чтобы использовать, по умолчанию 'NFC'.
Вернемся к предыдущему примеру, но на этот раз нормализуем строку:
const str = '\u0065\u0301'
console.log(str == '\u00e9') // => false
const normalized = str.normalize('NFC')
console.log(normalized == '\u00e9') // => true
console.log(normalized.length) // => 1TL; DR
Короче говоря, если вы создаете веб-приложение и принимаете ввод от пользователей, вы всегда должны нормализовать его в каноническую форму в Юникоде.
С JavaScript вы можете использовать метод String.prototype.normalize(), который встроен в ES2015.