Оптимизация анализа данных: Руководство по эффективной работе с отсутствующими данными

Работа с недостающими данными является важнейшим этапом процесса подготовки данных.
Поскольку в реальном мире редко можно ожидать 100%-ной полноты данных, крайне редко мы получаем 100% точные данные без шумов, пропущенных значений и т.д.
Например: Некоторые пользователи заполняют формы обратной связи и часто, обнаружив поле с 1%-ным процентом согласия, пропускают его и отправляют, в результате чего в базе данных остаются недостающие данные.
Почему важно обрабатывать отсутствующие данные?
Наша модель машинного обучения получает свои знания из данных, поэтому, если значительная часть данных отсутствует, её точность будет снижаться, делая модель бесполезной.
Как обрабатывать отсутствующие данные?
- Если 1% наших данных составляют нулевые значения, то мы исключим эти данные, удалив строку или столбец. Однако этот метод неэффективен, так как приводит к потере данных, имеющих решающее значение для эффективности нашей модели машинного обучения.
- Наиболее эффективным подходом является замена нулевого значения средним и медианой этого столбца в случае числовых данных и модой в случае категориальных данных.
Обработка недостающих данных с помощью Scikit-Learn:
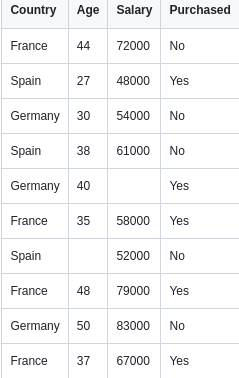
Чтобы продемонстрировать это, воспользуемся небольшой выборкой данных, хотя на самом деле их гораздо больше.
Шаг 1: Импорт библиотек
import numpy as np
import pandas as pd
import matplotlib.pyplot as pltШаг 2: Импорт массива данных
Загрузить массив данных можно отсюда.
dataset = pd.read_csv('Data.csv')
X = dataset.iloc[:,:-1].values
y = dataset.iloc[:,-1].valuesЗдесь я отделил независимые переменные (X) от зависимой переменной (y).
Шаг 3: Учёт недостающих данных
- Импортируйте из
sklearn.impute SimpleImputer: КлассSimpleImputerимпортируется этой строкой из модуляsklearn.imputeбиблиотеки scikit-learn. С помощью заранее определенных процедурSimpleImputerиспользуется для восполнения недостающих значений в наборе данных. imputer = SimpleImputer('mean' в качестве стратегии,missing_values=np.nan): В этой строке создается экземпляр классаSimpleImputer. В ней указывается, что np.nan, что в общем случае означает "Not a Number", будет использоваться для представления отсутствующих или неопределенных значений в числовых данных. Подход к вменению установлен на 'mean', что означает, что среднее значение (average) не пропущенных значений в том же столбце будет использоваться для замены всех отсутствующих значений.imputer.fit(X[:,1:3]): В этой строке производится подгонка (или обучение) механизма на определенном подмножестве набора данных, X[:,1:3].
imputer.transform(X[:,1:3]) = X[:,1:3]: Эта строка использует преобразование для заполнения недостающих значений в выбранных столбцах (1 и 2) исходного набора данных X после обучения механизма. При этом вместо отсутствующих значений подставляются соответствующие средние значения столбцов, определенные на этапе подгонки.
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(missing_values=np.nan,strategy='mean')
imputer.fit(X[:,1:3])
X[:,1:3] = imputer.transform(X[:,1:3])Ниже приведен вывод:
[['France' 44.0 72000.0]
['Spain' 27.0 48000.0]
['Germany' 30.0 54000.0]
['Spain' 38.0 61000.0]
['Germany' 40.0 63777.77777777778]
['France' 35.0 58000.0]
['Spain' 38.77777777777778 52000.0]
['France' 48.0 79000.0]
['Germany' 50.0 83000.0]
['France' 37.0 67000.0]] Наконец-то мы освоили работу с отсутствующими данными!
Полный код можно получить из этого репозитория GitHub: Ссылка на репозиторий.
Не стесняйтесь исследовать код и узнавать больше о других способах предварительной обработки данных!