Подключение к базам данных AWS Athena с помощью Python
ПРИМЕЧАНИЕ. Полный код, относящийся к этой статье, можно найти в этом репозитории Github.
AWS Athena - это сервис, который позволяет создавать базы данных и запрашивать данные из файлов данных, хранящихся в корзинах AWS S3. Это очень полезно, если у вас есть большой набор данных, хранящийся, скажем, в виде CSV или parquet файлов, и вы не хотите тратить дни на написание заданий ETL и загрузку их в стандартную базу данных SQL. По сути, он позволяет писать стандартные запросы SQL для извлечения данных из файлов с плоскими данными, хранящихся на S3.
Только что начав работать с базами данных Athena и столкнувшись с проблемой предоставления нашей команде доступа к Athena через Python и, в частности, через Jupyterlab, я придумал два разных метода разработки оболочки Python для простого и эффективного доступа к базам данных Athena.
Метод 1: PyAthena + SQLAlchemy
Если вы, как и я, поклонник SQLAlchemy, то наверняка знаете, что это отличная библиотека для абстрагирования подключений к различным базам данных, поддержки уровня ORM и многих других интересных преимуществ. Всякий раз, когда я сталкиваюсь с новой базой данных и мне нужно написать оболочку для подключения к ней, я думаю: «Может ли SQLAlchemy это сделать?» а в случае с Athena оказалось, что может. Большинству разработчиков Python очень удобно использовать SQLAlchemy для подключения к базам данных и запросов к ним, поэтому всегда полезно проверить, есть ли способ подключиться к любой новой базе данных с его помощью.
PyAthena - это библиотека, которая использует REST API Athena для подключения к Athena и получения результатов запроса. Его можно напрямую обернуть внутрь SQLAlchemy, и вы можете создать объект подключения SQLAlchemy, который можно напрямую связать с любыми обычно используемыми методами запроса, такими как загрузка данных в DataFrame pandas:
from urllib.parse import quote_plus
from sqlalchemy.engine import create_engine
AWS_ACCESS_KEY = "AWS_ACCESS_KEY"
AWS_SECRET_KEY = "AWS_SECRET_KEY"
SCHEMA_NAME = "schema_name"
S3_STAGING_DIR = "s3://s3-results-bucket/output/"
AWS_REGION = "us-east-1"
conn_str = (
"awsathena+rest://{aws_access_key_id}:{aws_secret_access_key}@"
"athena.{region_name}.amazonaws.com:443/"
"{schema_name}s3_staging_dir{s3_staging_dir}&work_group=primary"
)
# Create the SQLAlchemy connection. Note that you need to have pyathena installed for this.
engine = create_engine(
conn_str.format(
aws_access_key_id=quote_plus(AWS_ACCESS_KEY),
aws_secret_access_key=quote_plus(AWS_SECRET_KEY),
region_name=AWS_REGION,
schema_name=SCHEMA_NAME,
s3_staging_dir=quote_plus(S3_STAGING_DIR),
)
)
athena_connection = engine.connect()
Итак, вам нужно будет выяснить ключ доступа и секретный ключ для учетной записи AWS IAM, которая имеет доступ для запроса базы данных Athena, к которой вы подключаетесь, а также корзины результатов S3, которую вы настроили для Athena. Например, Athena требует, чтобы корзина результатов S3 записывала файлы физических результатов, откуда она и извлекает свои результаты. Вы заметили выше, что мы даже не импортируем PyAthena, но его необходимо установить в качестве основного драйвера базы данных для SQLAlchemy, когда мы используем синтаксис awsathena+rest для строки подключения.
Теперь, когда у нас есть подключение к вашей базе данных, все, что вам нужно сделать, это запросить ее, используя созданный вами объект подключения. Я предпочитаю использовать pandas:
import pandas as pd
df_data = pd.read_sql_query("select * from table", conn)
Очень простой в использовании, но, возможно, не лучший метод, так как он оказался очень медленным при запросе больших наборов данных. Метод Athena REST API GetQueryResults может возвращать только до 1000 записей за раз, что означает, что PyAthena должна поддерживать курсор и запрашивать следующие 1000 результатов и так далее. Когда мы переходим к запросам миллионов строк данных, это может занять много времени.
Это подводит нас к следующему:
Метод 2: используйте Boto3 и загрузите файл результатов
Прежде чем мы начнем говорить о следующем методе, давайте посмотрим, как работает Афина (на очень высоком уровне):
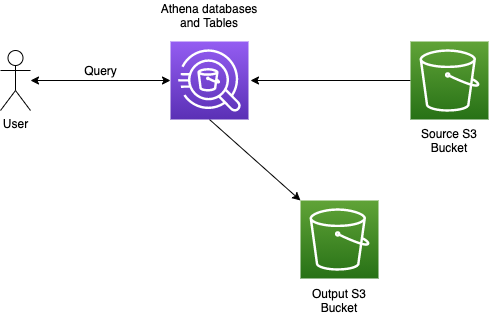
Когда пользователь делает запрос к базе данных Athena, Athena извлекает исходные данные из исходной корзины S3, возвращает результат пользователю, а также записывает результат (в виде CSV-файла большую часть времени) в выходную корзину S3, которое также является частью конфигурации экземпляра Athena.
Мы собираемся немного использовать то, как это работает, и использовать boto3, библиотеку AWS для Python, чтобы выполнить наш запрос, получить обратно идентификатор запроса, который только что был выполнен, и использовать его для получения связанного файла CSV по этому идентификатору.
Сначала мы создаем клиент Athena с помощью boto3:
import boto3
AWS_ACCESS_KEY = "AWS_ACCESS_KEY"
AWS_SECRET_KEY = "AWS_SECRET_KEY"
AWS_REGION = "us-east-1"
athena_client = boto3.client(
"athena",
aws_access_key_id=AWS_ACCESS_KEY,
aws_secret_access_key=AWS_SECRET_KEY,
region_name=AWS_REGION,
)
Затем мы используем клиент для выполнения запроса:
query_response = athena_client.start_query_execution(
QueryString="SELECT * FROM table",
QueryExecutionContext={"Database": SCHEMA_NAME},
ResultConfiguration={
"OutputLocation": S3_STAGING_DIR,
"EncryptionConfiguration": {"EncryptionOption": "SSE_S3"},
},
)
while True:
try:
# This function only loads the first 1000 rows
client.get_query_results(
QueryExecutionId=query_response["QueryExecutionId"]
)
break
except Exception as err:
if "not yet finished" in str(err):
time.sleep(0.001)
else:
raise errОбратите внимание, что у функции get_query_results нет обратного вызова, который позволяет нам узнать, что запрос выполнен; мы должны продолжать проверять цикл while. Мы полностью игнорируем возвращаемое значение, генерируемое функцией get_query_results, поскольку все, что нам нужно сделать, это выяснить, когда запрос перестает выполняться, а затем загрузить файл результатов.
Затем мы создаем клиент S3 с помощью boto3 и используем его для загрузки файла результатов запроса непосредственно с S3.
import pandas as pd
S3_BUCKET_NAME = "s3-results-bucket"
S3_OUTPUT_DIRECTORY = "output"
temp_file_location: str = "athena_query_results.csv"
s3_client = boto3.client(
"s3",
aws_access_key_id=AWS_ACCESS_KEY,
aws_secret_access_key=AWS_SECRET_KEY,
region_name=AWS_REGION,
)
s3_client.download_file(
S3_BUCKET_NAME,
f"{S3_OUTPUT_DIRECTORY}/{query_response['QueryExecutionId']}.csv",
temp_file_location,
)
return pd.read_csv(temp_file_location)
Это загружает результаты в файл в вашей рабочей области с именем athena_query_results.csv который вы затем можете загрузить в pandas DataFrame.
Более организованная версия этого кода доступна в репозитории Github.
Сравнение двух
Вот сравнение двух методов: выборка одного столбца из таблицы, содержащей более 2 миллионов записей, выборка 100, 1000, 10 000, 100 000 и 1 миллиона записей:
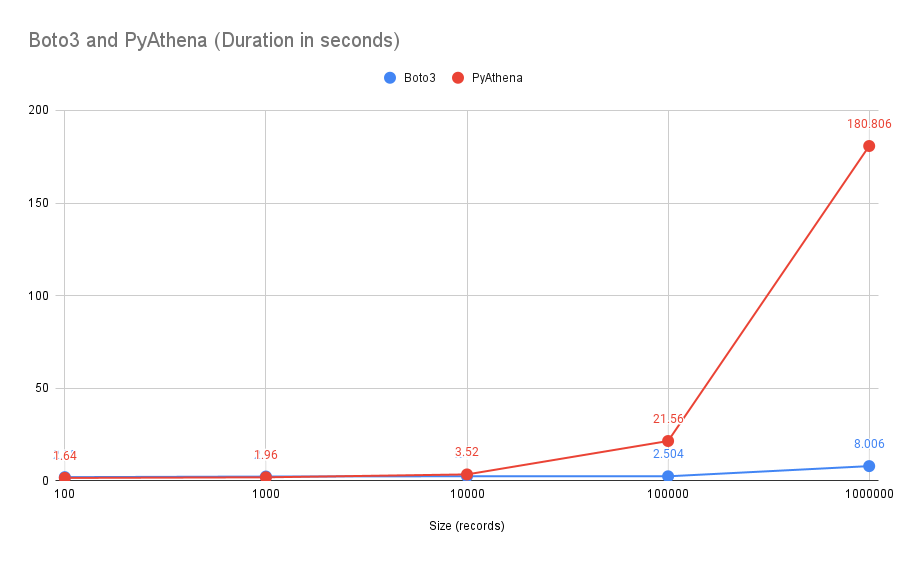
Как видите, по мере того, как размер данных, которые мы пытаемся получить, увеличивается и превышает отметку в 10 000 записей, Boto3 явно представляет собой лучший вариант. Тот факт, что PyAthena должна продолжать возвращаться к Athena с помощью курсоров, действительно, кажется, сдерживает ее при больших запросах.
Похоже, мы собираемся загружать файлы результатов с S3.