Поиск по сходству в DQL

Dgraph v24 представляет векторный тип данных и поиск по сходству в языке запросов DQL.
В этом посте показан простой пример использования векторных вложений и поиска по сходству.
В этом примере используется Racel для обновления схемы, мутаций и запросов, но вы можете использовать любой подход.
Настройка и установка dgraph и ratel
Получите док-контейнер Dgraph для альфа-версии v24.
docker pull dgraph/standalone:v24.0.0-alpha2 Запустите докер-контейнер, сохраняющий данные на вашем локальном компьютере.
mkdir ~/dgraph
docker run -d --name dgraph-v24alpha2 -p "8080:8080" -p "9080:9080" -v ~/dgraph:/dgraph dgraph/standalone:v24.0.0-alpha2Затем получите и запустите инструмент ratel
docker pull dgraph/ratel
docker run -d --name ratel -p "8000:8000" dgraph/ratel:latestРател теперь будет работать на localhost:8000
Добавьте схему, данные и тестовые запросы
Определите схему DQL. Вы можете установить это на вкладке схемы Racel, используя опцию массового редактирования.
<Issue.description>: string .
<Issue.vector_embedding>: float32vector @index(hnsw(metric:"euclidean")) .
type <Issue> {
Issue.description
Issue.vector_embedding
}Обратите внимание, что используется новый тип float32vector с новым типом индекса hnsw. Индекс hnsw может использовать различные метрики расстояния: косинус, евклидово значение или скалярное произведение. Здесь мы используем евклидово расстояние в качестве индекса.
На этом этапе база данных будет принимать и индексировать векторы с плавающей запятой для предиката Issue.vector_emebedding.
Вставьте некоторые данные, содержащие короткие встраивания только для тестирования, используя эту мутацию DQL.
Вы можете вставить это в Ratel как мутацию или использовать Curl, pydgraph или что-то подобное:
{
"set":
[
{
"dgraph.type": "Issue",
"Issue.vector_embedding": "[0.25, 0.47, 0.8, 0.27]",
"Issue.description":"Intermittent timeouts. Logs show no such host error."
},
{ "dgraph.type": "Issue",
"Issue.vector_embedding": "[0.57, 0.23, 0.68, 0.41]",
"Issue.description":"Bug when user adds record with blank surName. Field is required so should be checked in web page."
},
{
"dgraph.type": "Issue",
"Issue.vector_embedding": "[0.26, 0.12, 0.77, 0.57]",
"Issue.description":"Delays on responses every 30 minutes with high network latency in backplane"
},
{
"dgraph.type": "Issue",
"Issue.vector_embedding": "[0.45, 0.49, 0.72, 0.2]",
"Issue.description":"vSlow queries intermittently. The host is not found according to logs."
},
{ "dgraph.type": "Issue",
"Issue.vector_embedding": "[0.52, 0.05, 0.22, 0.82]",
"Issue.description":"Some timeouts. It seems to be a DNS host lookup issue. Seeing No Such Host message."
},
{
"dgraph.type": "Issue",
"Issue.vector_embedding": "[0.33, 0.64, 0.16, 0.68]",
"Issue.description":"Host and DNS issues are causing timeouts in the User Details web page"
}
]
} Простой запрос, который находит похожие вопросы
Вы готовы выполнять запросы на сходство, чтобы находить Проблемы на основе семантического сходства с новым описанием Проблемы! Для простоты мы не вычисляем большие векторы из LLM. Приведенные выше вложения просто представляют четыре понятия, которые находятся в четырех векторных измерениях: которые соответственно:
- Медлительность или задержки
- Ведение журнала или сообщений
- Сети
- Графические интерфейсы или веб-страницы
Вариант использования и запрос
Допустим, возникла новая проблема, и вы хотите использовать текстовое описание, чтобы найти другие похожие проблемы, с которыми вы сталкивались в прошлом. Используйте запрос сходства ниже.
Если новым описанием проблемы является «Медленный ответ и задержка в моей сети!», мы представляем эту новую проблему как вектор [0,28 0,75 0,35 0,48]. Обратите внимание, что первый параметр функции like_to — это имя поля DQL, второй параметр — это количество возвращаемых результатов, а третий параметр — это вектор для поиска.
query slownessWithLogs() {
simVec(func: similar_to(Issue.vector_embedding, 3, "[0.28 0.75 0.35 0.48]"))
{
uid
Issue.description
}
}Если вы хотите отправлять данные с использованием параметров, перепишите это как
query test($vec: float32vector) {
simVec(func: similar_to(Issue.vector_embedding, 3, $vec))
{
uid
Issue.description
}
}И сделайте запрос (опять же с помощью Racel) с переменной с именем «vec», установленной в значение JSON float[]:
vec: [0.28 0.75 0.35 0.48]Вычисление векторных расстояний и оценок сходства
Следующий запрос находит 3 наиболее похожих результата на основе входных данных $vect. Он использует индекс hnsw, объявленный в схеме с метрикой расстояния (в нашем случае евклидово расстояние).
В некоторых случаях вам нужно получить это расстояние или вычислить показатель сходства. Имейте в виду, что для расстояния, чем ниже, тем более похоже, для показателя сходства, чем выше, тем более похоже.
В Dgraph v24 представлена новая математическая функция DQL dot для вычисления скалярного произведения векторов. Используя функцию точки, вы можете вычислить выбранную вами оценку сходства в вашем запросе.
Учитывая два вектора
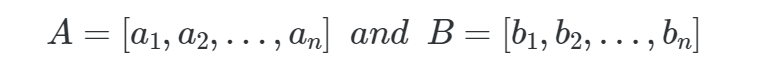
Евклидово расстояние — это норма L2 для A — B.
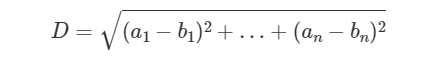
Его легко выразить в виде скалярного произведения
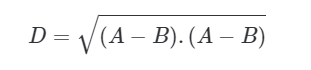
Другой вариант измерения близости двух векторов — использовать косинусное сходство. Косинусное подобие — это мера угла между двумя векторами.
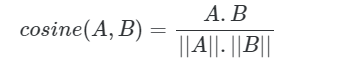
Косинус будет между -1 и 1 (идентичный вектор). Поэтому мы обычно превращаем его в косинусную меру расстояния:
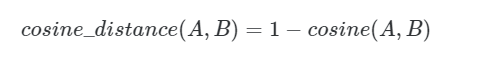
Когда векторы нормализованы ( ||A|| = 1 и ||B|| = 1 ), что обычно имеет место с векторными вложениями, созданными моделями ML. Вычисление косинуса можно упростить, используя только скалярное произведение.
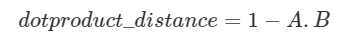
Распространенным вариантом использования является вычисление показателя сходства или достоверности. При использовании нормализованного вектора мы можем использовать
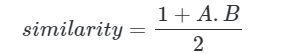
Эта метрика имеет приятное свойство: находиться в диапазоне от 0 до 1, при этом 1 соответствует максимально возможному сходству, обеспечивая простую оценку для применения пороговых значений.
Вычисление расстояний в DQL с использованием точечной функции
Вот пример вычисления евклидова, косинусного и скалярного произведения расстояний из нашего предыдущего запроса.
Нам просто нужно добавить переменную в запрос vemb как Issue.vector_embedding, чтобы получить векторное встраивание каждой похожей задачи и использовать ее в математических функциях.
Запрос также иллюстрирует использование промежуточной переменной для вычисления cosine_distance.
query slownessWithLogs($vec: float32vector) {
simVec(func: similar_to(Issue.vector_embedding, 3, $vec))
{
uid
Issue.description
vemb as Issue.vector_embedding
euclidean_distance: Math (sqrt( ($vec - vemb) dot ($vec - vemb)) )
dotproduct_distance: Math (1.0 - (($vec) dot vemb))
cosine as Math( ( ($vec) dot vemb) / sqrt((($vec) dot ($vec)) *(vemb dot vemb) ))
cosine_distance: Math(1.0 - cosine)
similarity_score: Math ((1.0 + (($vec) dot vemb)) / 2.0)
}
}Обычно вы просто вычисляете то же расстояние, которое определено в индексе или показателе сходства.
Следующий запрос показывает, как вычислить показатель сходства в переменной и использовать его для получения трех ближайших узлов, упорядоченных по сходству:
query slownessWithLogs($vec: float32vector) {
var(func: similar_to(Issue.vector_embedding, 3, $vec))
{
vemb as Issue.vector_embedding
score as Math ((1.0 + (($vec) dot vemb)) / 2.0)
}
# score is now a map of uid -> similarity_score
simVec(func:uid(score), orderdesc:val(score)){
uid
Issue.description
score:val(score)
}
}Подводя итоги
В этом комплексном примере показано, как можно вставлять данные с векторными векторными представлениями, соответствующие схеме, определяющей векторный индекс, и выполнять семантический поиск с помощью новой функции like\_to() в Dgraph. Он также показывает, как вычислять различные показатели с помощью новой функции точки.