Полное решение эффекта Dogpile в коде

Эффект Dogpile означает, что когда система находится под большим объемом трафика, всякий раз, когда кэш становится недействительным, будь то очистка или тайм-аут, это будет иметь огромное влияние.
Например, если к записи кэша обращаются 100 запросов одновременно, то по истечении срока действия записи 100 запросов попадут непосредственно в серверную систему, что является серьезной проблемой для серверной системы.
Существует три общих подхода, для борьбы с эффектом Dogpile, которые заключаются в следующем:
- Разогрев кэша
- Увеличение время кэширования
- Эксклюзивная блокировка
Однако также упоминалось, что каждый из трех подходов имеет свой собственный применимый сценарий и соответствующие потенциальные риски. Итак, есть ли способ извлечь преимущества каждого из них и создать более полное решение?
Концепция решения
Увеличение времени кэширования эффективно повышает доступность кэша. Когда кэш недействителен и запрашивается одновременно, только один запрос может пройти через кэш и попасть в серверную систему. Остальные запросы получат исходный результат по мере увеличения времени кэширования.
Однако, когда одновременные запросы выполняются в одно и то же время (что, как правило, бывает редко), по-прежнему существует возможность поступления нескольких запросов в серверную систему, отсюда и подход эксклюзивной блокировки.
Тем не менее, стоимость постоянного использования эксклюзивных замков слишком высока, инеобходимо попытаться свести к минимуму использование эксклюзивных замков, если это возможно. Затем используйте эксклюзивную блокировку только тогда, когда кэш не существует и есть необходимость получить доступ к серверной системе, в противном случае просто используйте extend cache time.
Весь процесс заключается в следующем.
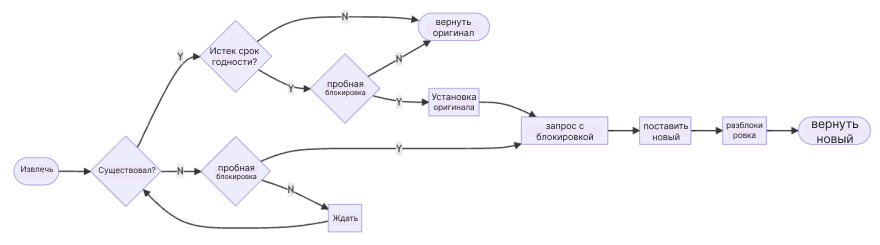
Прежде всего, определите, существует ли кэш, если кэш существует, нам все равно нужно определить, истек ли срок действия кэша. Если все в порядке, мы можем просто взять исходное значение кэша, но если срок действия кэша истек, мы должны войти в процесс обновления кэша.
Чтобы избежать воздействия большого количества одновременных запросов, все процессы кэша обновлений должны пытаться получить блокировку.
С другой стороны, если кэш не существует с самого начала, то процесс обновления кэша будет таким же. Только процесс отличается, как упоминалось выше, потому что нет исходного значения, поэтому те, кто не получил блокировку, должны дождаться блокировки, прежде чем они смогут получить результат.
Обзор решения
Прежде чем мы углубимся в детали реализации, давайте посмотрим на реальную практику.
def read_aside_cached(ttl, lock_period, race_period):
def decorator(func):
def wrap(*args, **kw):
key = f"{func.__name__}_{args}_{kw}"
return cache_factory(key, ttl, lock_period, race_period).handle(func, *args, **kw)
return wrap
return decorator
@read_aside_cached(60 * 5, 30, 60)
def foo(a, b=1, c=2):
return db.query(a, b, c)Это пример на Python, где мы используем декоратор для инкапсуляции реальной операции с базой данных.
Для этого декоратора требуется несколько параметров:
- ttl, это легко понять, это время истечения срока действия этого кэша.
- lock_period, потому что нам нужно получить блокировку, поэтому этот параметр определяет, как долго мы должны блокировать.
- race_period, этот параметр используется для определения того, на какой срок мы хотим расширить кэш.
В приведенном выше примере foo имеет время истечения срока действия кэша 5 минут и сохраняет буфер на 1 минуту. Время блокировки составляет 30 секунд, что соответствует ожидаемому времени работы базы данных.
Детали решения
Далее давайте разберем фактические детали блок-схемы.
def cache_factory(key, ttl, lock_period, race_period):
value, expired_at = Store.get(key)
if expired_at is not None:
handler = ExistedCacheHandler(key, ttl, lock_period, race_period)
else:
handler = NonExistedCacheHandler(key, ttl, lock_period, race_period)
handler.set_meta(value, expired_at)
return handlerВ начале блок-схемы нам нужно сначала попытаться получить кэш и использовать результаты, чтобы увидеть, нужно ли нам увеличивать время кэширования.
Верхний и нижний пути блок-схемы инкапсулируются каждым классом. Давайте сначала посмотрим на реализацию ExistedCacheHandler.
class ExistedCacheHandler(BaseCacheHandler):
def handle(self, func, *args, **kw):
if self.now > self.expired_at and Store.try_lock(self.key, self.lock_period):
result = func(*args, **kw)
Store.set(self.key, result, self.ttl + self.race_period)
Store.unlock(self.key)
return result
return self.orig_valЕсли срок действия кэша истек и он успешно получает блокировку, он отвечает за обновление кэша.
Существует такой подход Rails, при котором Rails снова записывает исходное значение обратно в кэш и немного увеличивает допустимое время. Но здесь мы напрямую задаем время кэширования (ttl + race_period), поэтому нам не нужно увеличивать время кэширования вручную.
Напротив, если срок действия кэша не истек или он не был заблокирован, то используется исходный результат в кэше.
С другой стороны, логика отсутствия кэша более сложна.
class NonExistedCacheHandler(BaseCacheHandler):
def handle(self, func, *args, **kw):
while self.expired_at is None:
if Store.try_lock(self.key, self.lock_period):
result = func(*args, **kw)
Store.set(self.key, result, self.ttl + self.race_period)
Store.unlock(self.key)
return result
else:
while not Store.try_lock(self.key, self.lock_period):
time.sleep(0.01)
self.orig_val, self.expired_at = Store.get(self.key)
Store.unlock(self.key)
else:
return self.orig_valКогда обнаруживается, что кэш не существует, мы все равно должны получить блокировку, чтобы обновить кэш. Но если блокировка не была получена успешно, мы должны дождаться либо блокировки, либо обновления кэша.
Почему мы должны ждать любого из этих двух условий?
Причина в том, что человек, который приобрел блокировку, возможно, не снял блокировку по «какой-то причине». Наша конечная цель - получить результат кеширования, поэтому, даже если мы не получим блокировку, мы все равно получим результат. Конечно, если блокировка будет успешно получена, ответственность за обновление кэша будет взята на себя
Наконец, давайте рассмотрим два общих компонента.
class Store:
@staticmethod
def get(k):
value = redis.get(k)
expired_at = redis.pttl(k) / 1000 + time.time() if value is not None else None
return value, expired_at
@staticmethod
def set(k, v, ttl):
return redis.set(k, v, "EX", ttl)
@staticmethod
def try_lock(k, lock_period):
r = redis.set(k, 1, "NX", "EX", lock_period)
return r == "OK"
@staticmethod
def unlock(k):
redis.del(k)
class BaseCacheHandler:
def __init__(self, key, ttl, lock_period, race_period):
self.key = key
self.ttl = ttl
self.lock_period = lock_period
self.race_period = race_period
def set_meta(self, value, expired_at):
self.orig_val = value
self.expired_at = expired_atBaseCacheHandler определяет конструкторы и вспомогательную функцию.
Store — это ядро всей реализации, и используется Redis в качестве демонстрации.
get(): в дополнение к получению значения кэша, нам также необходимо получить время истечения срока действия кэша.set(): запишите значение, а также установите время истечения срока действия.try_lock(): Используйте атомарное обновление Redis для блокировки с помощьюNX.unlock(): просто извлекает ключ.
Собрав все эти элементы, cache decorator становится завершенным, не только с возможностью увеличения времени работы кэша, но и с эксклюзивной поддержкой блокировки.
Вывод
Это работоспособный пример, и мы расположили его более интуитивно понятным образом, чтобы его было легче понять. Однако есть некоторые вещи, которые можно было бы усовершенствовать.
Например, во многих местах в настоящее время используется одна команда для непосредственного управления Redis, и было бы лучше записать ее в конвейере Redis. Более того, было бы неплохо написать какую-нибудь простую логику в виде скрипта на Lua.
Такая реализация на самом деле очень сложна, но действительно ли кэш, предназначенный для чтения, должен это делать?
Это зависит от загрузки приложения и того, что какие ожидания от приложения.
Если серверная система надежна и может справиться с внезапным скачком, то может сработать обычное увеличенное время кэширования. Но если серверная часть слаба, необходимо рассмотреть более солидный подход.
Улучшение механизма кэширования - это один из вариантов, но улучшение серверной системы также является вариантом. Существует несколько распространенных способов повышения доступности серверной системы:
- Схема автоматического выключателя
- Ухудшение качества обслуживания
- Многоуровневое кэширование
В этой статье предлагается вариант улучшения кэша, без необходимости развертывания новых компонентов и просто изменения логики, на наш взгляд, это все же стоит.