Понимание Timeline базы данных временных рядов

В современную эпоху бурного распространения данных данные временных рядов стали неотъемлемой частью бизнеса и организаций. Они включают в себя огромные объемы данных из различных источников, таких как датчики, устройства мониторинга, системы регистрации и финансовые транзакции, которые расположены в хронологическом порядке и фиксируют возникновение и изменения различных событий и действий. Анализ и обработка данных временных рядов имеют решающее значение для принятия бизнес-решений и повышения операционной эффективности в организации. Чтобы лучше управлять этими данными и использовать их, была изобретена система баз данных временных рядов (TSDB).
В системе TSDB данные временных рядов обычно абстрагируются и организуются в виде временных рядов, и разработка и внедрение TSDB также основаны на временных рядах, поэтому понимание временных рядов является необходимым условием для более глубокого понимания системы баз данных временных рядов.
В этой статье я познакомлюсь с концепцией временных рядов в TSDB и использую InfluxDB (2.x) в качестве примера для изучения организации и представления временных рядов в этой базе данных.
1. Что такое данные временного ряда
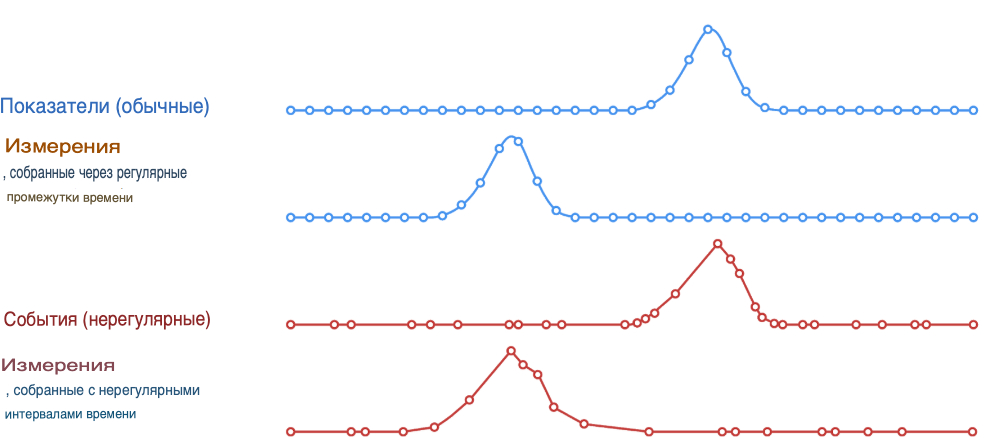
Данные временных рядов - это точки данных, которые записываются в хронологическом порядке и имеют временную метку. Эти точки данных могут быть непрерывными (показатели в верхней части диаграммы ниже), например, записываться один раз в секунду, или нерегулярными, например, записываться при возникновении определенного события (события в нижней части диаграммы ниже).
Данные Time-series имеют широкий спектр применений в ряде областей, таких как цены акций на финансовых рынках, метеорологические данные в науке о климате, эксплуатационные данные промышленного оборудования, данные IoT и Telematic данные, как показано ниже (это изображение взято из Интернета).
Данные Time-series обладают несколькими отличительными характеристиками:
- Временные метки
Данные временных рядов - это данные, связанные со временем, где каждой точке данных присваивается временная метка или временной диапазон для определения времени, когда она была сгенерирована или записана.
- Большие объемы данных
Объем временных данных, поступающих из источника, часто является непрерывным.
- Объем данных непредсказуем
Может наблюдаться внезапный приток данных через нерегулярные промежутки времени. Это очень распространено на финансовых рынках, где за событиями следуют резкие скачки объемов торгов, которые трудно предсказать.
- В режиме реального времени
Данные временных рядов часто необходимо обрабатывать и анализировать в режиме реального времени, чтобы можно было своевременно принимать меры или выдавать предупреждения при возникновении изменений в данных. Хорошим примером этого является обнаружение аномалий.
- Добавление написанного
Новые точки данных добавляются в конец существующих данных, а не изменяются или удаляются (очень редко) существующие данные. И в подавляющем большинстве случаев данные временных рядов располагаются в хронологическом порядке.
Мы можем видеть, что данные временных рядов и традиционные данные OLTP (онлайн-обработка транзакций) имеют много различных характеристик, и эти различия определяют модель данных, используемую в системах управления базами данных на основе данных time series, размер обрабатываемых данных, способ доступа к данным, частоту обработки данных и многое другое. как обрабатываются данные.
Итак, как современные основные базы данных time series хранят, обрабатывают данные временных рядов и управляют ими? Давайте продолжим по списку.
2. Timeline: базы данных Time-Series, моделирующие данные временных рядов
Когда вы впервые узнаете и изучите базу данных временных рядов (tsdb), вы узнаете термин, называемый Time Series, независимо от того, изучаете ли вы InfluxDB, Prometheus, TDengine или что-то еще.
Пол Дикс, соучредитель Influxdb, понимает временные рамки в ttsdb следующим образом:

Пол рассматривает временные рамки как способ интерпретации и понимания данных временных рядов. Фактически, временные рамки - это способ моделирования данных временных рядов в сообществе tsdb. Базы данных временных рядов разработаны и реализованы на основе этой модели временной шкалы, хотя, конечно, разные базы данных временных рядов создают несколько разные модели временной шкалы и обладают разными возможностями моделирования.
Используя временную шкалу в качестве модели, мы можем переопределить базу данных временных рядов как систему для хранения временных линий.
Здесь мы рассмотрим модель временной шкалы в базе данных временных рядов в реальном времени, используя Influxdb 2.x в качестве примера.
2.1 Линейный протокол для InfluxDB 2.x
Невозможно говорить о временных рамках, не упомянув линейный протокол InfluxDB для записи в точки данных. Это популярный на сегодняшний день протокол приема баз данных временных рядов в области tsdb. Протокол Line позволяет нам визуализировать способ, которым influxdb 2.x моделирует временную шкалу. Ниже приведен синтаксис и пример, как определено в руководстве по линейному протоколу.
// Syntax
<measurement>[,<tag_key>=<tag_value>[,<tag_key>=<tag_value>]] <field_key>=<field_value>[,<field_key>=<field_value>] [<timestamp>]
// Example
myMeasurement,tag1=value1,tag2=value2 fieldKey="fieldValue" 1556813561098000000Приведенную ниже диаграмму примера из презентации Paul Dix в PowerPoint и диаграмму из брошюры Line Protocol можно увидеть немного более наглядно.

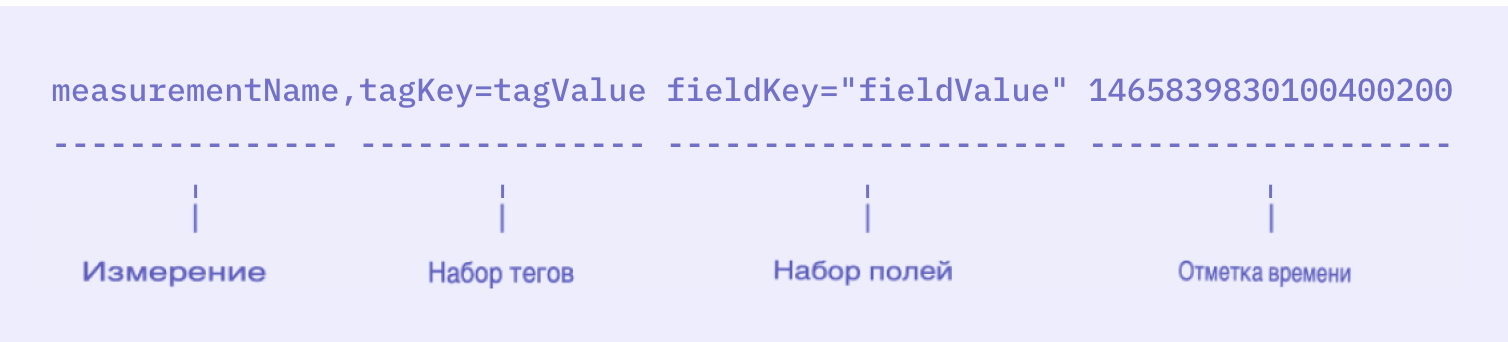
Мы видим, что: в InfluxDB данные временного ряда, вставленные по линейному протоколу, содержат четыре части.
- measurement (измерение)
Классы данных временных рядов, таких как измерение температуры, влажности и т. д., аналогичны имени таблицы в реляционной базе данных, где каждая точка данных временного ряда сгруппирована в измерение. Эта часть является обязательной.
- tag (тег)
Набор меток для точек данных временных рядов. Теги используются для описания атрибутов или характеристик данных, таких как местоположение, где они были сгенерированы, модель устройства и т.д. Для каждой точки данных временного ряда InfluxDB поддерживает несколько тегов (tags), каждый тег представляет собой пару ключ-значение, и несколько тегов разделены запятыми. Однако часть тега является необязательным полем, а все пары ключ-значение тега имеют тип string.
- field (поле)
Раздел поля представляет собой набор индикаторов для точек данных временных рядов, то есть часть данных полезной нагрузки. Этот раздел помещает поле для получения поля, пары ключей, включая имя индикатора и соответствующее значение. Если то, что нужно проглотить, является информацией о погоде места, здесь вы можете использовать температуру = 35,3, влажность = 0,7; Если коллекция является ценой акций акции, то здесь вы можете использовать цену = 201.
Раздел field является обязательным полем и должен содержать по крайней мере одну пару "ключ-значение". В отличие от тега, часть значения пары ключ-значение поля поддерживает числовые значения, логические значения и строки.
- timestamp (отметка времени)
Как следует из названия, этот раздел представляет собой отметку времени, когда точка данных была собрана; этот раздел в Line Protocol может быть пустым, и как только он будет пустым, временная метка точки данных будет по умолчанию установлена на текущее время.
Так что же такое временная шкала, которую InfluxDB определяет на основе линейного протокола? Давайте посмотрим на это.
2.2 Сроки и временные точки
Зная различные части линейного протокола, гораздо проще понять временную шкалу (Timeline), определенную InfluxDB.
Временная шкала, определенная InfluxDB, состоит из двух частей: одна часть представляет собой ключ временной шкалы, а другая часть представляет собой набор значений временной шкалы.
Примечание. Мы видим, что и имя тега, и значение тега являются частью ключа временной шкалы, но поле — это только имя, что является одним из важных различий между тегом и полем.
См. пример из презентации PowerPoint Пола Дикса со следующими данными, полученными с помощью Line Protocol:
weather,city=Denver,state=CO,zip=80222 temp=62.3,humidity=32
weather,city=Bellevue,state=WA,zip=98007 temp=50.7,humidity=76
weather,city=Brooklyn,state=NY,zip=11249 temp=58.2,humidity=55Давайте проанализируем, сколько временных шкал на самом деле содержится в этих трех данных линейного протокола! Основываясь на ключе временной шкалы, однозначно идентифицирующем временную шкалу, и определении ключа временной шкалы, мы можем получить шесть комбинаций measurement+tags+field_name, то есть шесть временных шкал.
weather,city=Denver,state=CO,zip=80222#temp
weather,city=Denver,state=CO,zip=80222#humidity
weather,city=Bellevue,state=WA,zip=98007#temp
weather,city=Bellevue,state=WA,zip=98007#humidity
weather,city=Brooklyn,state=NY,zip=11249#temp
weather,city=Brooklyn,state=NY,zip=11249#humidityПри таком рассмотрении ранее полученные данные были записаны только в одной точке данных (т.е. в момент времени) на каждой временной шкале. Если взять в качестве примера первую временную шкалу, то точки данных для ее получения следующие.
Timeline key:weather,city=Denver,state=CO,zip=80222#temp
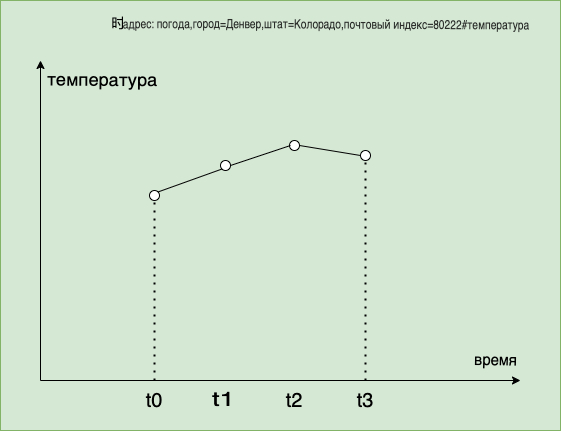
Timeline VALUE:(62.3, t0) // t0 indicates the timestamp at the time of ingestionЧтобы лучше представить взаимосвязь между временной шкалой и временными точками, мы затем используем линейный протокол, чтобы добавить еще несколько точек данных на вышеуказанную временную шкалу.
weather,city=Denver,state=CO,zip=80222 temp=64.3,humidity=42 // t1
weather,city=Denver,state=CO,zip=80222 temp=65.3,humidity=43 // t2
weather,city=Denver,state=CO,zip=80222 temp=64.9,humidity=45 // t3Сформированная таким образом временная шкала выглядит следующим образом:
Timeline key: weather,city=Denver,state=CO,zip=80222#tem
Timeline VALUE set: [(62.3, t0), (64.3, t1), (65.3, t2), (64.9, t3)]Мы можем визуально отобразить температурный тренд Денвора на этой временной шкале (ось X — это время, а ось Y — изменение температуры Денвора).
Примечание. Выше приведено моделирование данных временных рядов influxdb 2.x. influxdb 3.0, т. е. influxdb iox провел перемоделирование временных рядов, вернувшись к табличному подходу: measurement <=> table, а остальные метки, поля и временные метки стали столбцами.
Абстракция временной шкалы InfluxDB очень важна, она оказывает важное влияние на дизайн механизма хранения, механизма запросов и т.д. influxdb. Существует еще один важный вопрос, связанный с базами данных временных рядов, который необходимо четко понимать, и это мощность, ниже мы поговорим о мощности tsdb.
3. Мощность в базах данных временных рядов
Концепция мощности не является исключительной для баз данных временных рядов, она встречается в традиционных реляционных базах данных. Первый раздел первой главы "Основные идеи оптимизации SQL" посвящен мощности. Определение, данное в книге, состоит в том, что количество уникальных ключей в столбце называется мощностью. В книге также приводится пример, который лучше понятен. Например, столбец "пол" имеет значение "мужчина" или "женщина", поэтому основание столбца равно 2.
Итак, как InfluxDB определяет количество баз, связанных с базой данных временных рядов? Проще говоря, это количество уникальных временных рамок. Если база данных содержит только одно измерение, то мощность, определяющая это измерение, равна количеству уникальных временных шкал в рамках этого измерения, как показано в примере ниже.
measurement1:
- 2 tags
- tag1:has 3 unique values
- tag2:has 4 unique values
- 5 fieldsБазовое число для этого measurement1 равно 3x4x5 = 60.
В InfluxDB версии 2.x высокая кардинальность означает завышенную временную шкалу, что может повлиять на производительность чтения и записи. Это связано с тем, что высокое количество элементов увеличивает размер индекса, что приводит к увеличению использования памяти, снижению производительности запросов и увеличению времени обслуживания индекса. В то же время высокое значение Cardinality также может привести к снижению скорости записи, увеличению времени выполнения запросов, увеличению использования дискового пространства и более сложным и трудоемким операциям сжатия и обслуживания данных. Чтобы смягчить влияние высокой кардинальности на производительность чтения и записи InfluxDB, могут быть приняты такие меры, как тщательная разработка модели данных (уменьшение размеров высокой кардинальности), использование непрерывных запросов или задач для предварительной агрегации или использование InfluxDB 3.0, которая имеет только что был выпущен и, как утверждается, поддерживает неограниченные временные рамки.
4. Краткое содержание
Данные временных рядов имеют широкий спектр реальных приложений. Базы данных временных рядов, такие как InfluxDB 2.x, используют временные шкалы в качестве базовой структуры данных для эффективного моделирования, запросов и управления данными временных рядов. Однако данные с высокой кардинальностью остаются серьезной проблемой для баз данных временных рядов. Понимание временных шкал в базах данных временных рядов, их преимуществ и недостатков может помочь нам лучше использовать базы данных временных рядов для решения практических задач.
5. Ссылка
https://tonybai.com/2023/05/28/understand-time-series-of-tsdb/