Руководство для начинающих по стилизации DataFrame Pandas

Python предоставляет множество функций для настройки визуализации анализируемых данных. В этой статье мы подробно рассмотрим одну такую функцию, которая помогает стилизовать данные в электронной таблице MS Excel. Объект styler — это высокопотенциальный инструмент, который можно использовать для форматирования DataFrame, создавая привлекательный фасад, который больше не похож на электронную таблицу. Итак, давайте начнем с того, как настроить MS Excel по своему желанию с помощью стилизатора из Python.
Введение в стили
Необходимо использовать аксессор, чтобы в полной мере использовать свойства стиля для DataFrame Pandas. Он также поддерживает изменение объекта styler, который в основном используется для управления различными способами отображения DataFrame.
Ниже приведены различные типы стилей, которые можно включить в электронную таблицу с помощью опции styler в программировании на Python:
- Выделение минимальных значений
- Выделение максимальных значений
- Выделение нулевых значений
- Границы и данные таблицы цветов
- Усечение отображаемых десятичных знаков
- Скрытие столбца индекса
- Стиль написания электронной таблицы
Выделение минимальных значений
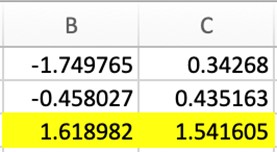
Чтобы выделить минимальные значения в данных электронной таблицы, используется приведенный ниже код.
df.style.highlight_min()Ниже приведен пример, в котором выделены минимальные значения каждого столбца.
Выделение максимальных значений
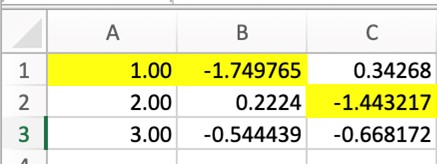
Теперь, когда мы выделили минимальные значения, давайте заменим min на max в коде, чтобы выделить максимальные значения данного набора данных.
df.style.highlight_max()Ниже приведен пример, в котором выделены максимальные значения каждого столбца.
Выделение нулевых значений
Учитывая максимальные и минимальные значения, можно задаться вопросом, есть ли способ визуализировать места, в которых присутствуют нулевые значения в данном наборе данных, если они есть. Сама эта мысль приводит нас к следующему коду, который выделяет нулевые значения, как показано ниже.
df.style.highlight_null()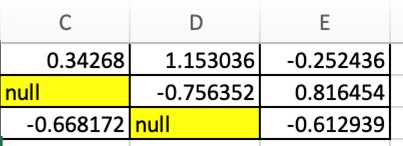
Границы и данные таблицы цветов
DataFrames, отображаемые в качестве выходных данных с помощью компиляторов Python, таких как, например, Jupyter Notebook, обычно визуализируются с использованием HTML и CSS. Поэтому кажется несложным настроить визуализацию данных с помощью функции set_properties вместе с объектом styler, как показано в коде, приведенном ниже.
df.style.set_properties(**{'border': '1.3px solid red', 'color': 'green'})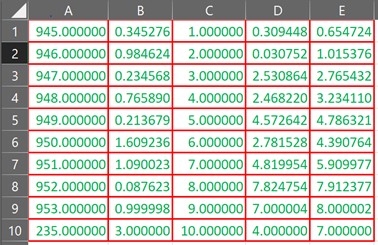
Усечение отображаемых десятичных знаков
Иногда в наборе данных можно иметь дело с десятичными знаками, где каждая запись имеет собственное количество десятичных цифр. Чтобы навести порядок, можно развернуть объект styler вместе с функцией set_precision для стандартизации десятичных знаков во всех записях, как показано ниже.
df.style.set_precision(3)
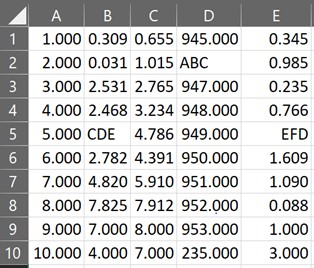
Скрытие столбца индекса
Самый первый столбец в DataFrame должен быть его индексом, который очень хорошо работает в качестве ссылки, но не во всех случаях. Таким образом, в случае необходимости используется приведенный ниже код, чтобы скрыть столбец индекса.
df.style.hide_index()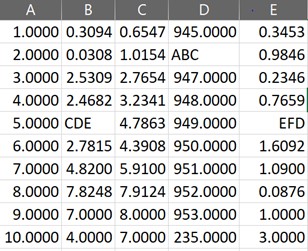
Стиль написания электронной таблицы
Достаточно настраивать выходные данные в таких компиляторах, как Jupyter Notebook, чтобы все получилось, выберите любую из вышеперечисленных модификаций или, что еще лучше, все и используйте функцию to.excel() для внедрения всех выбранных модификаций данных в электронной таблице MS Excel, как показано ниже.
df.style.highlight_min().set_properties(**{'border': '1.3px solid red','color': 'green'}). set_precision(3).to_excel('File.xlsx', engine = 'openpyxl')
Заключение
Теперь, когда мы подошли к концу этой статьи, надеемся, что она подробно описала методы использования функции styler в сочетании с функцией to_excel() для редактирования стиля содержимого в электронной таблице Excel.