Создание интерфейсных рабочих книг Excel для инструментов Python

Во время конференции Build 2016 Microsoft объявила, что 1,2 миллиарда человек по всему миру используют Excel.В том же году, по оценкам, население Земли составляло 7,4 миллиарда человек.
Это 16,2% всех людей на Земле.
По данным отчета 2019 года, Python сравнительно может похвастаться всего лишь 8,2 миллионами активных разработчиков, что составляет 0,001% населения Земли.
Учитывая эти цифры, нам может быть полезно поощрять больше интерактивности между Excel и Python - открывая шлюзы для множества новых пользователей для инструментов, построенных на Python.
Возможность внешнего интерфейса Excel для Python огромна. В этой статье мы рассмотрим, как это сделать, и реализуем «типичный» финансовый лист настройки Excel.
Сначала инструмент, Excel потом
Почти в каждом сценарии, который я могу придумать, более удобно сначала построить часть инструмента Python. Однако мы должны сохранять гибкость в форматировании «входных данных» инструмента.

Под этим я подразумеваю, что если мы, например, читаем один или два листа CSV / Excel, используя Pandas - для первого прототипа, мы можем положиться на заданный набор имен столбцов.
Но если в коде тысячи строк, мы полагаемся на одни и те же жестко запрограммированные значения, у нас возникнут проблемы, когда мы попытаемся сделать эти имена входных столбцов динамическими в Excel.
Таким образом, на начальных этапах создания прототипа, если еще нет листа Excel, используйте начальный раздел кода, чтобы переименовать метки столбцов в их внутренние (и, надеюсь, более описательные) имена меток:
mappings = {'loan identifier': 'loan_id',
'amt': 'amount',
...
'init fees': 'initial_fees'}
data.rename(mappings, axis=1, inplace=True)
# теперь для остальной части кода мы используем данные Python, заданные имена столбцов, 'loan_id', 'loan_amount' и т. дПозже это будет заменено нашими сопоставлениями листов Excel.
Excel Front-End
Как только инструмент Python будет встроен в более существенный прототип, нам пора приступить к созданию интерфейса Excel. Во-первых, мы должны решить, какие переменные можно настроить на листе Excel.
Всегда создавайте эти типы инструментов в предположении, что формат входных данных изменится.
В зависимости от того, где вы работаете, и инструмента, который вы разрабатываете, это либо очень важно, либо нет. Некоторые процессы просто четко определены, и форматирование данных вряд ли изменится.
Но я бы всегда ошибался из-за осторожности и включал бы большую, а не меньшую гибкость через интерфейс Excel. Только не слишком усложняйте.
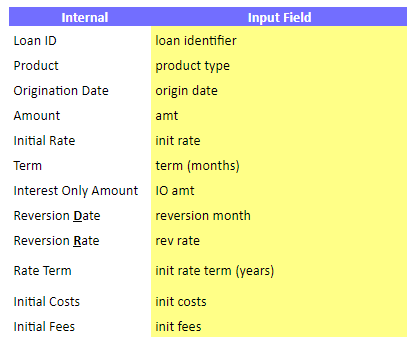
Использование внутренней системы именования и предоставление пользователю Excel возможности указывать сопоставления столбцов - отличный пример поддержания гибкости. Теперь вместо того, чтобы полагаться на жестко закодированные имена столбцов, пользователь Excel может корректировать эти отображения, даже не касаясь Python.
Отображения
Центральным элементом интеграции является словарь mappings. Это займет вкладку Excel, содержащую «настройки» инструмента (я обычно называю это Mapping).
Чтобы заполнить словарь сопоставлений, нам нужны функции для чтения вкладки сопоставления Excel. Для этого мы используем openpyxl.
Мы можем прочитать значение из данной ячейки в Excel следующим образом:
import openpyxl
# займите объект рабочей книги с помощью 'sheet.xlsx'
wb = openpyxl.load_workbook("sheet.xlsx", data_only=True)
# создайте объект рабочего листа с активным листом
ws = wb.active
# получить значение в ячейке 'E4'
value = ws['E4'].valueИспользуя этот метод, мы можем начать заполнять наш словарь mappings. Мы изменим приведенный выше код, чтобы добавить локальный путь к книге Excel «tool_setup».
Давайте также предположим, что изначально активный лист может не быть листом отображения, и в случае добавления, удаления или перемещения вкладок мы используем понимание списка, чтобы найти индекс вкладки «Отображение»:
# сначала мы задаем путь к файлу Excel
path = r".\documents\tool_setup.xlsx"
# откройте файл как объект рабочей книги
wb = openpyxl.load_workbook(path, data_only=True)
# найдите индекс листа "mapping"
idx = [i for i, name in wb.sheetnames if name == 'Mapping'][0]
# установите лист сопоставления как активный
wb.active = idx
ws = wb.activeТеперь мы можем добавить несколько отображений:
mappings = {}
mappings ['Amount'] = ws ["E4"]. value
mappings ['Term'] = ws ["E5"]. value
Гибкость при сохранении
В случае добавления или удаления строк на нашей вкладке сопоставления Excel этот подход приведет к созданию неправильного словаря mapping. Чтобы избежать этого, мы используем функцию search_col. Это будет итеративно искать каждую ячейку в столбце, пока не будет найдена ячейка, содержащая требуемое значение (или превышающее строку limit).
# определите функцию для поиска заданного столбца в объекте листа openpyxl
def search_col(sheet, column, value, limit=100):
# петля через каждую строку до предела, начиная с 1 для строки в диапазоне(1, limit+1):
if sheet[f"column{row}"].value == value:
# если мы найдем ту ценность, которую ищем, return col + row
return (col, row)На этом этапе search_col возвращает столбец и строку, содержащие данные, которые мы хотели найти.
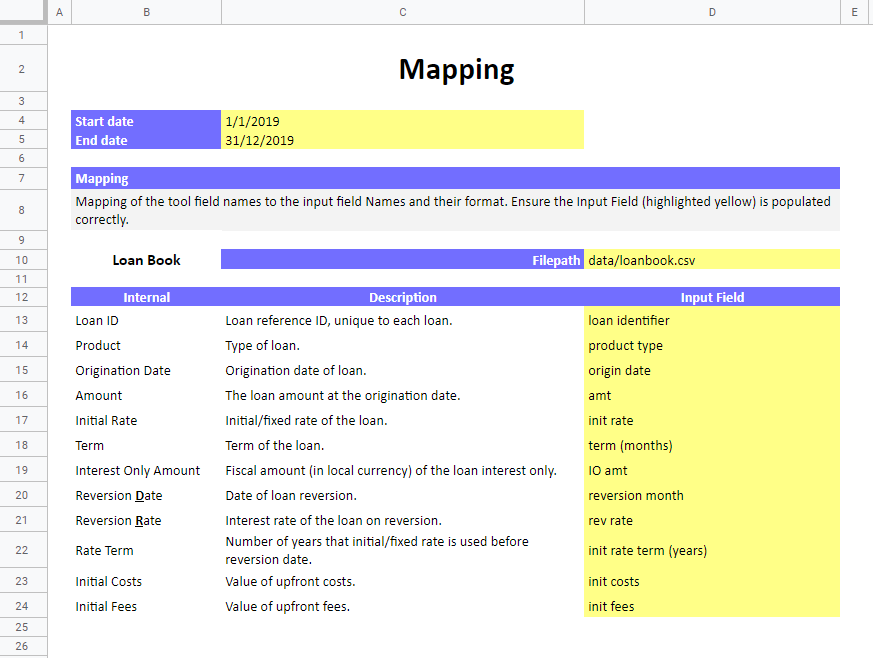
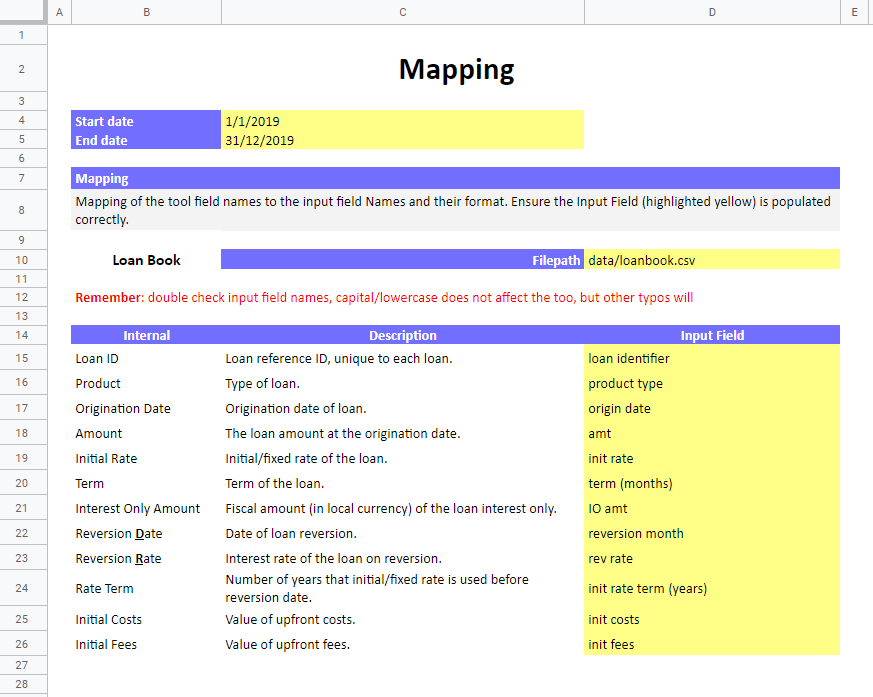
Это позволяет нам искать таблицу сопоставлений столбцов путем поиска в столбце B «Внутренний», например:
search_col (ws, 'B', 'Internal')[Out]: ('B', 12)Отсюда мы можем затем создать цикл для добавления отображений из столбца C в столбец E в наш словарь mappings. Увидев две или более пустых ячейки, мы можем быть уверены, что таблица сопоставления закончилась, и, таким образом, мы можем выйти из цикла:
empty = 0 # инициализируйте наше количество пустых ячеек
while empty < 2:
# увеличьте число строк (которое начинается с строки, которую мы нашли 'Internal'
row += 1
# назначьте значение, которое мы находим в столбце "Internal", внутреннему
internal = ws[f'B{row}'].value
if internal is None:
empty += 1 #если мы получим пустую строку, увеличим пустой счетчик
else:
# в противном случае у нас есть отображение для добавления к отображениям dict
mappings[internal] = ws[f'D{row}'].value
empty = 0 # also re-initialize the empty counterПосле запуска этого фрагмента кода у нас будет словарь Python, mappings который выглядит следующим образом:
{
'Loan ID': 'loan identifier',
'Product': 'product type',
...
'Initial Fees': 'init fees'
}Если мы также хотим ввести другие переменные, например, путь к файлу, который показан на скриншотах листа отображения data/loanbook.csv, мы просто находим строку, содержащую « Filepath» и извлекаем соответствующее значение в столбце D:
row, _ = search_col(ws, 'C', 'Filepath')
mappings['filepath'] = ws[f'D{row}].value
Интеграция
Последний шаг также является самым простым, интегрируя эти новые имена столбцов в наши скрипты Python.
Давайте использовать приведенный выше лист сопоставления для считывания наших данных и преобразования меток входных столбцов в их внутренние метки.
data = pd.read_csv(mappings['Filepath'])Перед преобразованием меток входных столбцов в их внутренние метки мы должны поменять местами пары ключ-значение на пары значение-ключ.
# инвертировать словарь
inv_mappings = {mappings[key]: key for key in mappings}Хотя для этого простого примера это может показаться более удобным при создании словаря mappings. Для более сложных инструментов я всегда считал, что лучше поддерживать формат внутреннего и внешнего отображения, который мы используем здесь. Тем не менее, эту деталь решать вам.
Наконец, преобразуйте входные метки во внутренние метки:
data.rename(inv_mappings, axis=1, inplace=True)Мы можем добавить больше гибкости здесь. Чтобы избежать возможности опережать / заканчивать пробелами или опечатками в нижнем и верхнем регистре, мы переписываем эту часть кода:
data = pd.read_csv(mappings['Filepath'])
# строчные буквы и полосы пробелов из всех заголовков столбцов
data.rename({col: col.strip().lower() for col in data.columns},
axis=1, inplace=True)
# мы также должны сделать то же самое для inv_mappings
# также добавьте форматирование snake_case во внутренние столбцы (необязательно)
inv_mappings = {
mappings[key].strip().lower():
key.strip().lower().replace(' ', '_')
for key in mappings
}
# а теперь мы можем смело переименовывать столбцы входных данных
data.rename(inv_mappings, axis=1, inplace=True)Еще одна дополнительная часть, которую я хотел бы включить. Когда мы показываем метки внутренних столбцов на листе Excel, они пишутся с большой буквы и содержат нормальный интервал. Однако, как личное предпочтение, я поддерживаю внутреннее форматирование snake_case, преобразовывая:
"Loan ID" -> "loan_id"
"Initial Rate" -> "initial_rate"
Я видел бесчисленные офисы с большим количеством Excel, которые могли бы сэкономить сотни часов, потратив флажки, введя значения или ожидая, пока модели Excel обработают даже самые маленькие наборы данных.
Хотя эпоха автоматизации и машинного обучения быстро автоматизирует многие тяжелые домены Excel, он никуда не денется.
В настоящее время многие отрасли могут получить огромные преимущества благодаря более тесной интеграции между самым быстрорастущим языком программирования в мире и наиболее используемым в мире программным обеспечением.
Спасибо за чтение!