Создавайте масштабируемые конвейеры прогнозирования моделей ML с малой задержкой, используя Spark Structured Streaming и MLflow.

Серия MLOps на практике — совместное использование шаблонов проектирования и внедрения критического компонента MLOps. Основное внимание в сегодняшней статье уделяется построению конвейеров прогнозирования моделей.
Чтобы заставить модели ML работать в реальной производственной среде, одним из наиболее важных шагов является развертывание обученных моделей для прогнозирования. Развертывание модели (выпуск) - это процесс, который позволяет интегрировать обученные модели ML в производство для принятия решений на основе реальных данных. Когда дело доходит до развертывания модели, обычно существует два типа:
- Одним из них является пакетное прогнозирование, при котором обученные модели вызываются и передаются пакетом данных с определенным интервалом (например, один раз в день или один раз в неделю, в зависимости от того, как модели используются в определенных бизнес-контекстах), для периодической генерации прогнозов для использования.
- Другой — онлайн-прогнозирование, когда обученная модель упакована в виде REST API или контейнерной микрослужбы, и модель возвращает результаты прогнозирования (обычно в формате JSON), отвечая на запрос API. При онлайн-прогнозировании модель делает прогнозы в режиме реального времени, то есть, как только вызывается API, будет возвращен результат прогнозирования модели. Кроме того, REST API модели обычно интегрируется как часть веб-приложения, с которым могут взаимодействовать конечные пользователи или последующие приложения.
Однако, в отличие от пакетного прогнозирования и онлайн-прогнозирования, мы наблюдаем увеличение числа сценариев, в которых модель не требуется упаковывать как REST API, но требуемая задержка для прогнозирования модели довольно низкая. Поэтому, чтобы удовлетворить потребности этих сценариев, я хотел бы поделиться решением — построение конвейера прогнозирования модели ML с низкой задержкой и масштабируемостью с использованием Spark Structured Streaming и MLflow.
В данной статье мы рассмотрим:
- Краткое введение в Spark Structured Streaming и mlflow;
- Ключевые компоненты архитектуры конвейеров прогнозирования машинного обучения с малой задержкой и масштабируемостью;
- Сведения о реализации использования Spark Structured Streaming и mlflow для создания масштабируемых конвейеров прогнозирования машинного обучения с малой задержкой;
Введение в Spark Structured Streaming и mlflow
Spark Structured Streaming — Structured Streaming — это масштабируемый и отказоустойчивый механизм обработки потоков, построенный на основе механизма Spark SQL. По умолчанию запросы структурированной потоковой передачи внутренне обрабатываются с помощью механизма микропакетной обработки, который обрабатывает потоки данных как серию небольших пакетных заданий, благодаря чему сквозные задержки составляют всего 100 миллисекунд, а отказоустойчивость гарантируется ровно один раз. .
MLflow — это платформа с открытым исходным кодом для управления сквозным жизненным циклом машинного обучения.
- Отслеживание (Tracking) — Компонент отслеживания MLflow - это API и пользовательский интерфейс для регистрации параметров, версий кода, метрик и выходных файлов при запуске кода машинного обучения и для последующей визуализации результатов.
- Модели (Models) — Модель MLflow представляет собой стандартный формат для упаковки моделей машинного обучения, который можно использовать в различных последующих инструментах. Формат определяет соглашение, позволяющее сохранять модель в различных «flavors», которые могут быть поняты различными последующими инструментами. Встроенные ароматы модели можно найти здесь. Стоит отметить, что разновидность модели python_function служит интерфейсом модели по умолчанию для моделей MLflow Python. Ожидается, что любая модель MLflow Python будет загружаться как модель python_function. В сегодняшнем продемонстрированном решении мы загрузили обученную модель как функцию Python. Кроме того, мы также использовали вызовы API модели log_model() и load_model().
- Реестр моделей (Model Registry) — компонент реестра моделей MLflow представляет собой централизованное хранилище моделей, набор API-интерфейсов и пользовательский интерфейс для совместного управления полным жизненным циклом модели MLflow. Он обеспечивает происхождение модели (обеспечивает видимость и отслеживаемость обученной модели ML, полученной в результате комбинации конкретного эксперимента MLflow и запуска), управление версиями модели, переходы между стадиями (например, от промежуточной стадии к рабочей) и аннотации.
- Проекты (Projects) — Проект MLflow - это формат для упаковки кода data science многоразовым и воспроизводимым способом, основанный в первую очередь на соглашениях. Каждый проект - это просто каталог файлов или репозиторий Git, содержащий ваш код.
Теперь давайте глубоко погрузимся в ключевые компоненты архитектуры построения такого конвейера прогнозирования ML с низкой задержкой и масштабируемостью.
Ключевые компоненты архитектуры малозатратного и масштабируемого конвейера прогнозирования ML
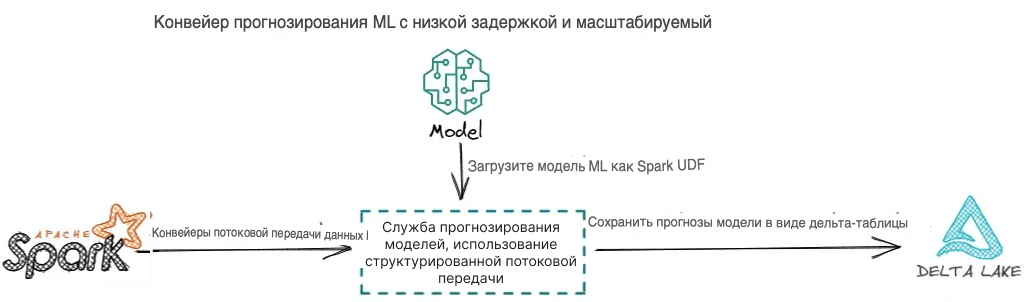
Как показано на приведенной выше диаграмме, существует 3 ключевых компонента архитектуры для построения конвейера прогнозирования ML с низкой задержкой и масштабируемостью:
- Первым шагом является построение конвейера потоковых данных для приема необработанных данных, преобразования необработанных данных в функции ML и передачи функций ML в модели ML с низкой задержкой;
- Второй шаг заключается в загрузке обученной и зарегистрированной модели ML в качестве пользовательской функции Spark (UDF), чтобы модель могла делать прогнозы параллельно, чтобы использовать распределенные вычислительные мощности Spark. Это особенно полезно, когда данные, необходимые для составления прогнозов, имеют большой объем.
- Третий шаг заключается в сохранении результатов прогнозирования модели в дельта-таблице, хранящейся в корзине AWS S3. Затем результаты прогнозирования модели могут быть использованы для последующих потребителей данных и приложений. Например, вы можете создать панель бизнес-аналитики (BI) поверх результатов прогнозирования модели для поддержки принятия бизнес-решений. Вы также можете создать механизм мониторинга в режиме реального времени для генерации уведомлений и оповещений на основе прогнозов модели для повышения эффективности работы.
Прежде чем мы продемонстрируем реализацию того, как построить конвейер прогнозирования ML с низкой задержкой и масштабируемостью, нам нужно сначала установить некоторые предварительные условия.
- Прежде всего, это схема обученной модели, как показано в файле ниже:
{"model_purpose" : "predicts the quality of wine using wine attributes",
"model_flavor" : ["python_function","sklearn"],
# The python_function model flavor serves as a default model interface for MLflow Python models.
# Any MLflow Python model is expected to be loadable as a python_function model.
# This enables other MLflow tools to work with any python model regardless of
# which persistence module or framework was used to produce the model.
"model_algorithm" : "sklearn.linear_model.ElasticNet",
{"model_signature" :
"model_input_schema":[
{"name": "fixed acidity", "type": "string"},
{"name": "volatile acidity", "type": "string"},
{"name": "citric acid", "type": "string"},
{"name": "residual sugar", "type": "string"},
{"name": "chlorides", "type": "string"},
{"name": "free sulfur dioxide", "type": "string"},
{"name": "total sulfur dioxide", "type": "string"},
{"name": "density", "type": "string"},
{"name": "pH", "type": "string"},
{"name": "sulphates", "type": "string"},
{"name": "alcohol", "type": "string"}],
"model_output_schema" [
{"type": "tensor", "tensor-spec": {"dtype": "float64", "shape": [-1]}}
]
},
"model_registry_location" : "runs:/<RUN_ID>/<MODEL_NAME>",
# If you are using mlflow to manage the lifecycle of your models,
# the model is loggged as an artifact in the current run using MLflow Tracking
"model_stage" : "Production",
# With mlflow, you can transition a registered model to one of the stages:
# Staging, Production or Archived.
# In the demo of this article, the model is alreay transitioned to the "production" stage.
"model_owner" : "<MODEL_OWNER_EMAIL/MODEL_OWNER_GROUP_EMAIL>"
}- Во-вторых, это схема обучающих и тестовых данных. Проверка соответствия схемы данных, подаваемых в модель, схеме ввода модели имеет решающее значение для предотвращения любых ошибок, вызванных несоответствием схемы во время прогнозирования модели. Схема данных показана как показано ниже:
StructType([
StructField('fixed acidity', StringType(), True),
StructField('volatile acidity', StringType(), True),
StructField('citric acid', StringType(), True),
StructField('residual sugar', StringType(), True),
StructField('chlorides', StringType(), True),
StructField('free sulfur dioxide', StringType(), True),
StructField('total sulfur dioxide', StringType(), True),
StructField('density', StringType(), True),
StructField('pH', StringType(), True),
StructField('sulphates', StringType(), True),
StructField('alcohol', StringType(), True),
StructField('quality', StringType(), True)
])Данные, использованные в этой статье, взяты отсюда. Не стесняйтесь узнать более подробную информацию об этих данных.
Теперь, когда у нас есть хорошее представление о том, как выглядит схема модели и схема данных, мы можем приступить к реализации конвейера прогнозирования ML с использованием Spark Structured Streaming и MLflow. Полное решение подробно описано в следующем разделе.
Комплексное решение — построение конвейера прогнозирования ML с низкой задержкой и масштабируемостью с использованием Spark Structured Streaming и MLflow
Шаг 1 — Создайте конвейер приема потоковых данных для загрузки данных для прогнозирования с низкой задержкой. Структурированная потоковая передача позволяет вам определить, насколько быстро необходимо обрабатывать данные, установив интервал микропакетов. В сегодняшней демонстрации мы установим интервал микропакетов равным 5 минутам, что означает, что каждые 5 минут потоковый конвейер будет извлекать необработанные данные и вызывать развернутую модель ML для прогнозирования. Ниже приведен пример конвейера приема потоковых данных для загрузки необработанных данных (в формате CSV) в фрейм потоковых данных Spark.
streamingDF = (spark
.readStream
.option("sep",",")
.option("header", "True")
.option("enforceSchema", "True")
.schema(csvSchema)
.csv(<YOUR-CSV-DATA-LOCATION>))Шаг 2 — Загрузите зарегистрированную модель как функцию Spark User Defined Function (UDF).
import mlflow
logged_model = 'runs:/<RUN_ID>/<MODEL_NAME>'
# Load model as a Spark UDF.
# Override result_type if the model does not return double values.
loaded_model = mlflow.pyfunc.spark_udf(spark, model_uri=logged_model, result_type='double')Шаг 3 — Сделайте прогнозы на потоковом фрейме данных и сохраните результаты прогнозов ML-модели в дельта-таблице для нижестоящих потребителей.
# Predict on a Spark DataFrame.
from pyspark.sql.functions import struct, col
streamingDF.withColumn('predictions', loaded_model(struct(*map(col, streamingDF.columns))))Комплексное решение
import mlflow
from pyspark.sql.functions import struct, col
from pyspark.sql.types import StructTypelogged_model = 'runs:/<RUN_ID>/<MODEL_NAME>'
loaded_model = mlflow.pyfunc.spark_udf(spark, model_uri=logged_model, result_type='double')
checkpointLocation = <STREAMING_CHECKPOINT_LOCATION>
deltaLocation = <PREDICTION_STORAGE_LOCATION>streamingDF = (spark
.readStream
.option("sep",",")
.option("header", "True")
.option("enforceSchema", "True")
.schema(csvSchema)
.csv(<YOUR-CSV-DATA-LOCATION>)
.withColumn('predictions', loaded_model(struct(*map(col, streamingDF.columns)))))(streamingDF.writeStream
.format("delta")
.outputMode("append") # .outputMode("complete"), .outputMode("update")
.option("checkpointLocation",checkpointLocation)
.option("path", deltaLocation)
.trigger(processingTime='5 minutes') # trigger(availableNow=True), .trigger(once=True), .trigger(continuous='1 second')
.queryName("streaming csv files")
.start())Сегодня вам была посвящена статья с объяснением одного из популярных шаблонов для компонента построения конвейеров обслуживания ML.