SQL в Python Pandas: Краткое руководство пользователя SQL

В этом посте мы сравним реализацию Pandas и SQL для запросов к данным. Мы рассмотрим, как использовать Pandas аналогично SQL, переводя SQL-запросы в операции Pandas.
Важно отметить, что существуют различные способы достижения аналогичных результатов, и перевод SQL-запросов в Pandas будет осуществляться с помощью некоторых основных методов.
Рейсы в Нью-Йорк
Мы стремимся изучить разнообразные методы Python Pandas, сосредоточившись на их применении на основе набора данных nycflights13. Этот набор данных содержит исчерпывающую информацию об авиакомпаниях (airlines), аэропортах (airports), погодных условиях (weather conditions) и самолетах (aircraft) для всех рейсов (flights), проходивших через аэропорты Нью-Йорка в 2013 году.
С помощью этого упражнения мы не только изучим функциональность Pandas, но и научимся применять фундаментальные концепции SQL в среде манипулирования данными на Python.
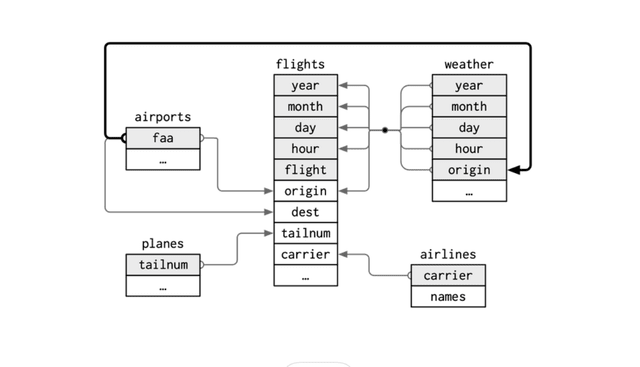
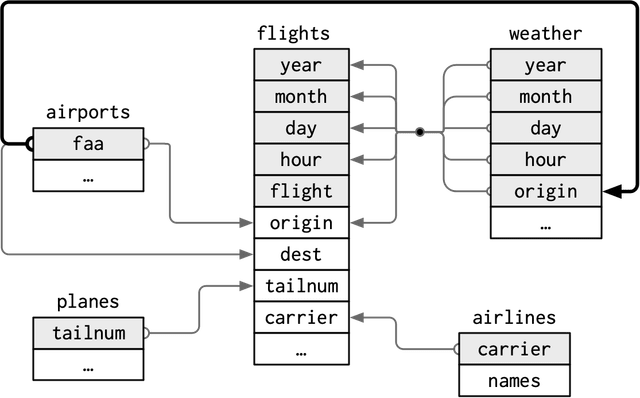
Диаграмма "сущность-связь" [DER]
Библиотека nycflights13 содержит таблицы с данными о рейсах из аэропортов Нью-Йорка в 2023 году. Ниже приведено высокоуровневое представление диаграммы "сущность-связь" с пятью таблицами.
Установка nycflights13
Чтобы установить библиотеку nycflights13, вы можете воспользоваться следующей командой:
!pip install nycflights13Эта библиотека предоставляет наборы данных, содержащие полную информацию о рейсах из аэропортов Нью-Йорка в 2023 году. После установки вы сможете легко получить доступ и проанализировать эти данные о рейсах, используя различные инструменты и функциональные возможности, предоставляемые пакетом nycflights13.
Pandas, NumPy и nycflights13 для анализа данных на Python
В следующем фрагменте кода мы импортируем необходимые библиотеки Python для анализа данных.
- Pandas - это библиотека для манипулирования и анализа данных
- Numpy обеспечивает поддержку числовых операций
- Nycflights13 - это специализированная библиотека, содержащая наборы данных, связанных с рейсами из аэропортов Нью-Йорка в 2023 году
import pandas as pd
import numpy as np
import nycflights13 as nycВ следующих строках кода мы присваиваем переменным два конкретных набора данных из библиотеки nycflights13.
flights = nyc.flights
airlines = nyc.airlinesОперации SELECT и FROM
SELECT: Все столбцы
Следующий SQL-запрос извлекает все столбцы и строки из таблицы "flights". В Pandas эквивалентом является простое написание имени DataFrame, в данном случае "flights". Например:
SQL:
SELECT * FROM flights;Python:
flightsSELECT: Определенные столбцы
Чтобы выбрать определенные столбцы из Pandas DataFrame, вы можете использовать следующий синтаксис:
SQL:
select
year,
month,
day,
dep_time,
flight,
tailnum,
origin,
dest
from flights;Python:
(
flights
.filter(['year', 'month', 'day', 'dep_time',
'flight', 'tailnum', 'origin', 'dest'])
)
Операторы фильтрации (WHERE)
Использование 'WHERE' для равенства ( = )
Чтобы отфильтровать в Pandas все рейсы с отправлением 'JFK', вы можете использовать следующий код:
SQL:
select year, month , day, dep_time, flight, tailnum, origin, dest
from flights
where origin = 'JFK'
limit 10;
Python:
( flights
.filter(['year', 'month', 'day', 'dep_time',
'flight', 'tailnum', 'origin', 'dest'])
.query("origin=='JFK'")
.head(10)
)Чтобы добиться такой же фильтрации в Pandas по определенным критериям:
- Рейсы, вылетающие из аэропортов JFK, LGA или EWR.
SQL:
select year, month , day, dep_time, flight, tailnum, origin, dest
from flights
where origin in ( 'JFK', 'LGA', 'EWR' )
limit 10;Python:
( flights
.filter(['year', 'month', 'day', 'dep_time',
'flight', 'tailnum', 'origin', 'dest'])
.query("origin in ['JFK', 'EWR', 'LGA']")
.head(10)
)Использование 'WHERE' с неравенством ( != )
Чтобы добиться такой же фильтрации в Pandas по определенным критериям:
- Рейсы, вылетающие из аэропортов JFK, LGA или EWR.
- Рейсы, не направляющиеся в Майами (MIA).
SQL:
select year, month , day, dep_time, flight, tailnum, origin, dest
from flights
where origin in ( 'JFK', 'LGA', 'EWR' ) and dest<>'MIA'
limit 10;Python:
( flights
.filter(['year', 'month', 'day', 'dep_time',
'flight', 'tailnum', 'origin', 'dest'])
.query(
"(origin in ['JFK', 'EWR', 'LGA'])"
"and (dest != 'MIA')"
)
.head(10)
)Использование 'WHERE' для сравнений
Чтобы добиться такой же фильтрации в Pandas по определенным критериям:
- Рейсы, вылетающие из аэропортов JFK, LGA или EWR.
- Рейсы, не направляющиеся в Майами (MIA).
- Рейсы с расстоянием менее или равным 1000 км.
SQL:
select year, month , day, dep_time, flight, tailnum, origin, dest
from flights
where origin in ( 'JFK', 'LGA', 'EWR' )
and dest<>'MIA'
and distance < = 1000
limit 10;Python:
( flights
.filter(['year', 'month', 'day', 'dep_time',
'flight', 'tailnum', 'origin', 'dest',
'time_hour', 'distance'])
.query(
"(origin in ['JFK', 'EWR', 'LGA'])"
" and (dest != 'MIA') "
" and (distance <= 1000)"
)
.head(10)
)Использование 'WHERE' с оператором between
Чтобы добиться такой же фильтрации в Pandas по определенным критериям:
- Рейсы, вылетающие из аэропортов JFK, LGA или EWR.
- Рейсы, не направляющиеся в Майами (MIA).
- Рейсы с расстоянием менее или равным 1000 км.
- Полеты в период с 1 сентября 2013 года по 30 сентября 2013 года.
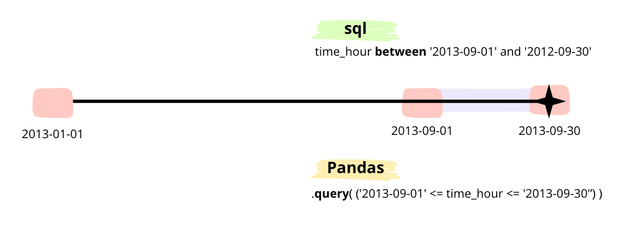
SQL:
select year, month , day, dep_time, flight, tailnum, origin, dest
from flights
where origin in ( 'JFK', 'LGA', 'EWR' )
and dest<>'MIA'
and distance < = 1000
and time_hour between '2013-09-01' and '2012-09-30'
limit 10;Python:
( flights
.filter(['year', 'month', 'day', 'dep_time',
'flight', 'tailnum', 'origin', 'dest',
'time_hour', 'distance'])
.query(
"(origin in ['JFK', 'EWR', 'LGA'])"
" and (dest != 'MIA')"
" and (distance <= 1000)"
" and ('2013-09-01' <= time_hour <= '2013-09-30')"
)
.head(10)
)Использование 'WHERE' с выражением "LIKE"
Чтобы добиться такой же фильтрации в Pandas по определенным критериям:
- Рейсы, вылетающие из аэропортов JFK, LGA или EWR.
- Рейсы, не направляющиеся в Майами (MIA).
- Рейсы с расстоянием менее или равным 1000 км.
- Полеты в период с 1 сентября 2013 года по 30 сентября 2013 года.
- Рейсы, в тексте которых хвостовой номер содержит 'N5'.
Можно воспользоваться следующим кодом:
SQL:
select year, month , day, dep_time, flight, tailnum, origin, dest
from flights
where origin in ( 'JFK', 'LGA', 'EWR' )
and dest<>'MIA'
and distance < = 1000
and time_hour between '2013-09-01' and '2012-09-30'
and tailnum like '%N5%'
limit 10;Python:
(
flights
.filter(['year', 'month', 'day', 'dep_time', 'flight',
'tailnum', 'origin', 'dest', 'time_hour'])
.query(
" (origin in ['JFK', 'EWR', 'LGA'])"
" and (dest != 'MIA') "
" and ('2013-09-01' <= time_hour <= '2013-09-30')"
" and (tailnum.str.find('N5')>=0)"
)
.head(10)
)Использование 'WHERE' с нулевыми или не нулевыми значениями
Чтобы добиться такой же фильтрации в Pandas по определенным критериям:
- Рейсы, вылетающие из аэропортов JFK, LGA или EWR.
- Рейсы, не направляющиеся в Майами (MIA).
- Рейсы с расстоянием менее или равным 1000 км.
- Полеты в период с 1 сентября 2013 года по 30 сентября 2013 года.
- Рейсы, в тексте которых хвостовой номер содержит 'N5'.
- Рейсы, где dep_time равно null
Можно воспользоваться следующим кодом:
SQL:
select year, month , day, dep_time, flight, tailnum, origin, dest
from flights
where origin in ( 'JFK', 'LGA', 'EWR' )
and dest<>'MIA'
and distance < = 1000
and time_hour between '2013-09-01' and '2012-09-30'
and tailnum like '%N5%'
and dep_time is null
limit 10;Python:
(
flights
.filter(['year', 'month', 'day', 'dep_time', 'flight',
'tailnum', 'origin', 'dest', 'time_hour'])
.query(
" (origin in ['JFK', 'EWR', 'LGA'])"
" and (dest != 'MIA') "
" and ('2013-09-01' <= time_hour <= '2013-09-30')"
" and (tailnum.str.find('N5')>=0)"
" and dep_time.isnull()"
)
.head(10)
)Заявление ORDER BY
Методы .sort_values() в Pandas эквивалентны предложению ORDER BY в SQL.
**.sort_values(['origin','dest'], ascending=False)**: Этот метод сортирует DataFrame на основе столбцов 'origin' и 'dest' в порядке убывания (от наибольшего к наименьшему). В SQL это было бы похоже на предложениеORDER BY origin DESC, dest DESC.**.sort_values(['day'], ascending=True)**: Этот метод сортирует DataFrame на основе столбца 'day' в порядке возрастания (от наименьшего к наибольшему). В SQL это было бы похоже на предложениеORDER BY day ASC.
Оба метода позволяют отсортировать DataFrame по одному или нескольким столбцам, задавая направление сортировки параметром ascending. True означает сортировку по возрастанию, а False - по убыванию.
SQL:
select year, month , day, dep_time, flight, tailnum, origin, dest
from flights
where origin in ( 'JFK', 'LGA', 'EWR' )
and dest<>'MIA'
and distance < = 1000
and time_hour between '2013-09-01' and '2012-09-30'
and tailnum like '%N5%'
and dep_time is null
order by origin, dest desc
limit 10;Python:
(
flights
.filter(['year', 'month', 'day', 'dep_time', 'flight',
'tailnum', 'origin', 'dest', 'time_hour'])
.query(
" (origin in ['JFK', 'EWR', 'LGA'])"
" and (dest != 'MIA') "
" and ('2013-09-01' <= time_hour <= '2013-09-30')"
" and (tailnum.str.find('N5')>=0)"
" and year.notnull()"
)
.sort_values(['origin','dest'],ascending=False)
.head(10)
)Различные значения: Удаление дубликатов из результатов
Чтобы выполнить функцию выбора отличий в pandas, необходимо сначала выполнить весь запрос, а затем применить метод drop_duplicates() для удаления всех дублирующихся строк.
SQL:
select distinct origin, dest
from flights
where origin in ( 'JFK', 'LGA', 'EWR' )
and dest<>'MIA'
and time_hour between '2013-09-01' and '2012-09-30'
order by origin, dest desc;Python:
(
flights
.filter(['origin','dest','time_hour'])
.query(
" (origin in ['JFK', 'EWR', 'LGA'])"
" and (dest != 'MIA') "
" and ('2013-09-01' <= time_hour <= '2013-09-30')"
)
.filter(['origin','dest'])
.drop_duplicates()
)Добавление вычисляемых столбцов
Теперь введем новый вычисляемый столбец "delay_total", в котором мы просуммируем значения из столбцов "dep_delay" и "arr_delay".
SQL:
select
origin,
dest,
time_hour,
dep_delay,
arr_delay,
flights.dep_delay + flights.arr_delay as delay_total
from flights
where origin in ( 'JFK', 'LGA', 'EWR' )
and dest<>'MIA'
and time_hour between '2013-09-01' and '2012-09-30';Python:
(
flights
.filter(['origin', 'dest', 'time_hour', 'dep_delay', '
arr_delay'])
.assign(delay_total = flights.dep_delay + flights.arr_delay )
.query(
" (origin in ['JFK', 'EWR', 'LGA'])"
" and (dest != 'MIA') "
" and ('2013-09-01' <= time_hour <= '2013-09-30')"
)
)Заявление GROUP BY
Для выполнения операции GROUP BY в pandas мы будем использовать метод groupby, который работает аналогично своему коллеге из SQL. Аналогичным образом мы можем использовать общие агрегатные функции, такие как sum, max, min, mean (эквивалент avg в SQL) и count. Ниже приведен простой пример, иллюстрирующий этот процесс:
SQL:
select
year,
month,
max(dep_delay) as dep_delay,
from flights
group by
year,
monthPython:
(
flights
.groupby(['year','month'],as_index=False)
['dep_delay'].max()
)Заявления GROUP BY и HAVING
В следующем примере мы рассмотрим, как реализовать заявление HAVING в pandas, используя метод query, как мы уже делали ранее для фильтрации.
SQL:
select
year,
month,
max(dep_delay) as dep_delay,
from flights
group by
year,
month
having max(dep_delay)>1000
Python:
(
flights
.groupby(['year','month'],as_index=False)['dep_delay']
.max()
.query('(dep_delay>1000)') # having
)Заявление GROUP BY с несколькими вычислениями
При работе с pandas и необходимости выполнить несколько вычислений для одного столбца или разных столбцов ценным инструментом становится функция agg. Она позволяет указать список вычислений, которые необходимо применить, обеспечивая гибкость и эффективность анализа данных.
Рассмотрим следующий SQL-запрос:
SQL:
select
year,
month,
max(dep_delay) as dep_delay_max,
min(dep_delay) as dep_delay_min,
mean(dep_delay) as dep_delay_mean,
count(*) as dep_delay_count,
max(arr_delay) as arr_delay_max,
min(arr_delay) as arr_delay_min,
sum(arr_delay) as arr_delay_sum
from flights
group by
year,
month
Этот запрос извлекает агрегированную информацию из набора данных "flights", вычисляя различные статистические данные, такие как максимум, минимум, среднее, количество и сумма для столбцов "dep_delay" и "arr_delay". Чтобы добиться аналогичного результата в pandas, мы используем функцию agg, которая позволяет задать эти вычисления лаконично и эффективно. Полученный фрейм данных дает наглядное представление о заданных метриках для каждой комбинации "год" и "месяц".
Python:
result = (
flights
.groupby(['year','month'],as_index=False)
.agg({'dep_delay':['max','min','mean','count'], 'arr_delay':['max','min','sum']})
)
# Concatenate function names with column names
result.columns = result.columns.map('_'.join)
# Print the results
resultЗаявление UNION
Чтобы выполнить операцию UNION ALL в Pandas, необходимо создать два DataFrame и объединить их с помощью метода concat. В отличие от SQL, DataFrame в Pandas можно объединять для создания дополнительных столбцов или дополнительных строк. Поэтому необходимо определить, как будет выполняться конкатенация:
- axis=1 => Соединение, которое добавляет другой набор данных справа, создавая больше столбцов.
- axis=0 => Соединение, добавляющее больше строк.
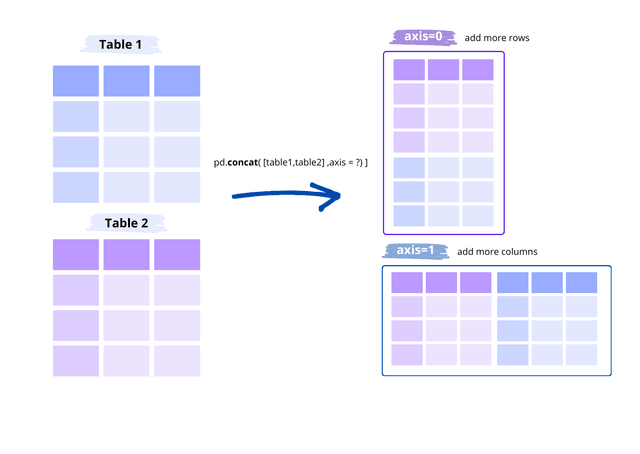
В нашем примере мы будем выполнять эквивалент UNION ALL в SQL, поэтому мы будем использовать axis=0.
SQL:
select
origin,
dest,
time_hour,
dep_delay,
arr_delay,
flights.dep_delay + flights.arr_delay as delay_total ,
'NYC' group
FROM flights
WHERE origin in ( 'JFK', 'LGA', 'EWR' )
and dest<>'MIA'
and time_hour between '2013-09-01' and '2012-09-30'
ORDER BY flights.dep_delay + flights.arr_delay DESC
LIMIT 3
UNION ALL
select
origin,
dest,
time_hour,
dep_delay,
arr_delay,
flights.dep_delay + flights.arr_delay as delay_total ,
'MIA' group
FROM flights
WHERE origin in ( 'JFK', 'LGA', 'EWR' )
and time_hour between '2013-07-01' and '2012-09-30'
ORDER BY flights.dep_delay + flights.arr_delay DESC
LIMIT 2
;Python:
Flights_NYC = (
flights
.filter(['year', 'month', 'day', 'dep_time', 'flight',
'tailnum', 'origin', 'dest', 'time_hour',
'dep_delay', 'arr_delay'])
.assign(delay_total = flights.dep_delay + flights.arr_delay )
.query(
" (origin in ['JFK', 'EWR', 'LGA'])"
" and ('2013-09-01' <= time_hour <= '2013-09-30')"
)
.assign(group ='NYC')
.sort_values('delay_total',ascending=False)
.head(3)
)
Flights_MIAMI = (
flights
.filter(['year', 'month', 'day', 'dep_time', 'flight',
'tailnum', 'origin', 'dest', 'time_hour',
'dep_delay', 'arr_delay'])
.assign(delay_total = flights.dep_delay + flights.arr_delay )
.query(
" (dest in ['MIA', 'OPF', 'FLL'])"
" and ('2013-07-01' <= time_hour <= '2013-09-30')"
)
.assign(group ='MIA')
.sort_values('delay_total',ascending=False)
.head(2)
)
# union all
pd.concat([ Flights_NYC,Flights_MIAMI],axis=0)
Заявление CASE WHEN
Чтобы воспроизвести оператор CASE WHEN, мы можем использовать два различных метода из NumPy:
- Если есть только два условия, например, проверка, не превышает ли общая задержка 0, то мы помечаем это как "Задержка"; в противном случае мы помечаем это как "Вовремя". Для этого используется метод
np.whereиз NumPy.
SQL:
select
origin,
dest,
time_hour,
dep_delay,
arr_delay,
(case
when flights.dep_delay + flights.arr_delay >0 then 'Delayed'
else 'On Time' end) as status ,
FROM flights
LIMIT 5;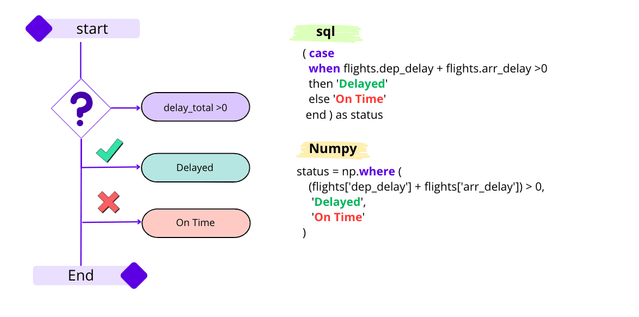
Python:
(
flights
.filter(['year', 'month', 'day', 'dep_time', 'flight',
'tailnum', 'origin', 'dest', 'time_hour',
'dep_delay', 'arr_delay'])
.assign(status=np.where((flights['dep_delay'] + flights['arr_delay']) > 0, 'Delayed', 'On Time'))
.head(5)
)
- Если условий больше, например, можно определить аэропорты Майами и обозначить их как "MIA", обозначить аэропорты "ATL", как находящиеся в Атланте, а для любых других случаев использовать метку "OTHER". Для этого используется метод
np.selectиз NumPy.
| Город | Название аэропорта | Аббревиатура |
| Miami | Miami International | (MIA) |
| Miami | Opa-locka Executive | (OPF) |
| Miami | Fort Lauderdale-Hollywood | (FLL) |
| Atlanta | Hartsfield-Jackson Atlanta | (ATL) |
| Atlanta | DeKalb-Peachtree | (PDK) |
| Atlanta | Fulton County | (FTY) |
SQL:
select
origin,
dest,
time_hour,
dep_delay,
arr_delay,
(case
when dest in ('ATL','PDK','FTY') then 'ATL'
when dest in ('MIA','OPF','FLL') then 'MIA'
else 'Other'
end) as city ,
FROM flights
LIMIT 10;Python:
(
flights
.filter(['year', 'month', 'day', 'dep_time', 'flight', 'tailnum', 'origin', 'dest', 'time_hour', 'dep_delay', 'arr_delay'])
.assign(city=np.select([ flights['dest'].isin(['ATL','PDK','FTY']),
flights['dest'].isin(['MIA', 'OPF', 'FLL']),
],
['ATL','MIA'],
default='Other')
)
.head(10)
)Заявление JOIN
Диаграмма отношений между сущностями [DER]:
При выполнении объединения в Pandas следует использовать метод слияния.
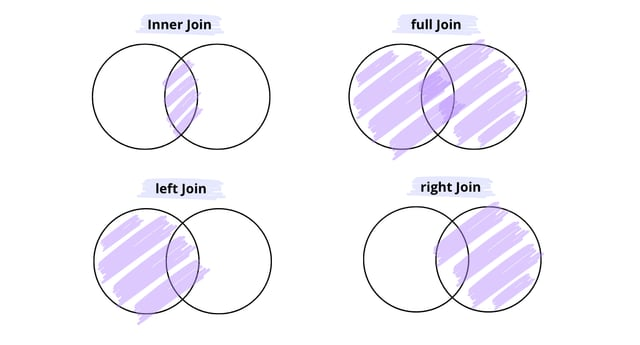
Типы присоединения
Способ: Указывает тип соединения, которое будет выполнено. Доступные варианты: {'left', 'right', 'outer', 'inner', 'cross'}.
Ключ присоединения
On: Ключ, по которому будут объединены таблицы. Если задействовано более одного столбца, следует указать список. Примеры:
- Одиночная переменная:
on='year'.
fligths.merge(planes, how='inner', on='tailnum')- Две переменные:
on=['year','month','day'].
fligths.merge(weather, how='inner', on=['year','month','day'])left_on/right_on: Если столбцы имеют разные имена, следует использовать эти параметры. Например:
fligths.merge(airports, how='inner', left_on = 'origin', rigth_on='faa')Вот пример, использующий таблицы авиакомпаний и рейсов:
SQL:
select
f.year,
f.month,
f.day,
f.dep_time,
f.flight,
f.tailnum,
f.origin as airport_origen,
f.dest,
f.time_hour,
f.dep_delay,
f.arr_delay,
f.carrier,
a.name as airline_name
FROM flights f
left join airlines a on f.carrier = a.carrier
LIMIT 5;Переименование
Метод rename используется для переименования столбцов, аналогично предложению "as" в SQL.
Python:
(
flights
.filter(['year', 'month', 'day', 'dep_time',
'flight', 'tailnum', 'origin', 'dest',
'time_hour', 'dep_delay', 'arr_delay',
'carrier'])
.merge(airlines, how = 'left', on ='carrier')
.rename(columns= {'name':'airline_name',
'origin':'airport_origen'})
.head(5)
)
Вы можете найти весь код в блокноте 🐍python🐍 по следующей ссылке!