Топ-3 альтернативных пакета Python для Pandas

Для многих современных специалистов по обработке данных Python - это язык программирования, который использовался в повседневной работе - как следствие, анализ данных будет выполняться с использованием одного из самых распространенных пакетов данных, которым являются Pandas. Многие онлайн-курсы и лекции представят Pandas как основу для любого анализа данных с помощью Python.
На мой взгляд, Pandas по-прежнему остается наиболее полезным и жизнеспособным пакетом для анализа данных на Python. Однако для сравнения я хочу познакомить вас с несколькими альтернативами пакетов Pandas. Я не собираюсь убеждать людей переходить с Pandas на другой пакет, но я просто хочу, чтобы люди знали, что есть альтернативы для пакета Pandas.
Итак, что это за альтернативные пакеты Pandas? Давайте займемся этим!
1. Polars
Polars - это библиотека DataFrame, предназначенная для обработки данных с быстрым временем освещения за счет реализации языка программирования Rust и использования Arrow в качестве основы. Предпосылка Polars - дать пользователям более быстрый опыт по сравнению с пакетом Pandas. Идеальная ситуация для использования пакета Polars - это когда у вас есть данные, которые слишком велики для Pandas, но слишком малы для использования Spark.
Для вас, кто знаком с рабочим процессом Pandas, Polars не будет чем-то отличаться - есть некоторые дополнительные функции, но в целом они очень похожи. Попробуем поэкспериментировать с пакетом Polars. Во-первых, нам нужно установить Polars в вашу среду Python.
pip install polarsПосле этого я бы создал образец DataFrame с помощью пакета Polars.
import polars as pl
df= pl.DataFrame({'Patient':['Anna','Be','Charlie','Duke','Earth','Faux','Goal','Him'],
'Weight':[41,56,78,55,80,84,36,91],
'Segment':[1,2,1,1,3,2,1,1] })
df
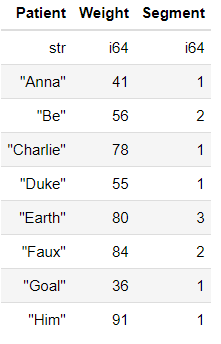
Подобно Pandas DataFrame, интерфейс и рабочий процесс анализа данных кажутся знакомыми. Немного отличается то, как тип данных находится в верхней части данных, а индекс не отображается. Попробуем использовать некоторые функции, доступные в Polars.
#Print DataFrame datatype
print(df.dtypes)
#Print DataFrame columns
print(df.columns)
#Print DataFrame top 5
print(df.head())
#Conditional Selection
print(df[df['Weight'] < 70])

В Polars есть много доступных функций, которые выполняют ту же функцию, что и функции Pandas, и есть возможность условного выбора. Я не сказал, что все функции, доступные в Pandas, доступны на Polars. Например, когда я хочу выполнить выбор индекса с помощью iloc.
df.iloc [1]
Ошибка возникает, когда я хочу сделать выбор индекса. Это связано с тем, что концепция индекса Pandas не применялась в Polars.
Одна из специальных концепций, применимых в Polars, - это Expression. В Polars вы можете создать последовательно выполняемую функцию (которая называется Expression) и объединить их в конвейер. Давайте воспользуемся примером, чтобы понять концепцию.
#Parallel Expression
df[[
#Expression for executing the stats (sum) and create the column names "sum"
pl.sum("Weight").alias("sum"),
pl.min("Weight").alias("min"),
pl.max("Weight").alias("max"),
pl.std("Weight").alias("std dev"),
pl.var("Weight").alias("variance"),
]]
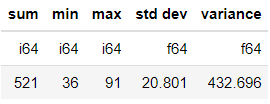
Если мы заимствуем концепцию Pandas, часто то, что мы сделали выше, похоже на условный выбор Pandas. Однако в нашем случае с Polars выполнение выражения привело к другому набору данных, когда мы передавали выражение.
Основным аргументом в пользу использования Polars по-прежнему является более быстрое время выполнения. Итак, насколько быстро выполняется Polars по сравнению с Pandas? В этом случае позвольте мне позаимствовать пример изображения из документации Polars, чтобы дать вам сравнение.
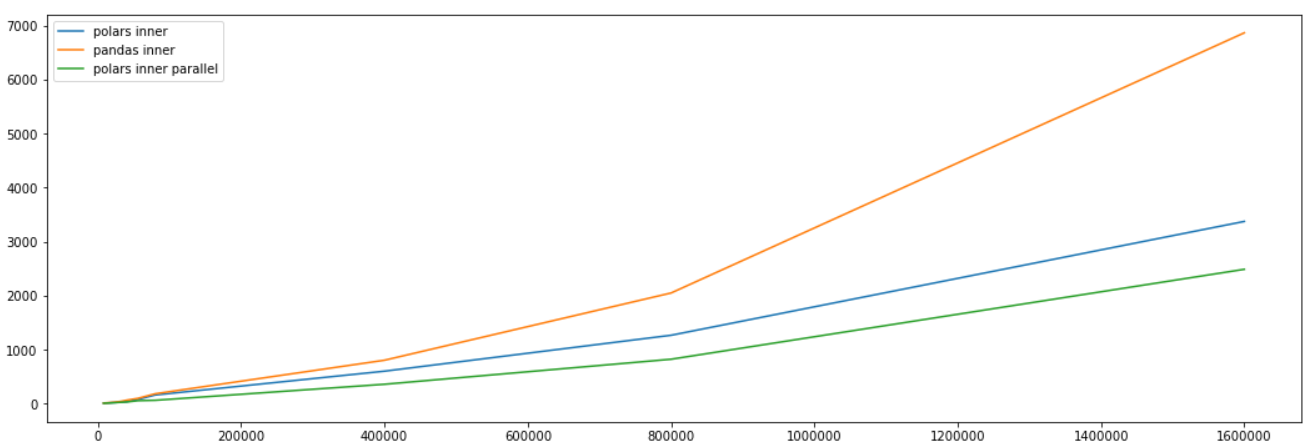
На изображении выше показано сравнение времени, когда Inner присоединился с использованием трех разных методов: Polars Inner Join, Pandas Inner Join и Polars Inner Join Parallel. Как видите, время выполнения Pandas медленнее, когда размер данных становится больше по сравнению с Polars. Может не быть такой большой разницы во времени выполнения при меньшем размере данных, но это становится более ясным, когда размер данных больше.
2. Dask
Dask - это пакет Python для параллельных вычислений на Python. Dask состоит из двух основных частей:
- Планирование задач. Подобно Airflow, он используется для оптимизации процесса вычислений путем автоматического выполнения задач.
- Сбор больших данных. Параллельный фрейм данных, такой как массивы Numpy или объект фрейма данных Pandas, специфичный для параллельной обработки.
Проще говоря, Dask предлагает фрейм данных или объект массива, как вы могли бы найти в Pandas, но он обрабатывается параллельно для сокращения времени выполнения и предлагает планировщик задач.
Поскольку в этой статье рассматривается только альтернатива для Pandas, мы не будем тестировать функцию планирования задач. Вместо этого мы сосредоточимся на объекте фрейма данных Dask. Давайте попробуем несколько простых примеров функций Dask - но сначала нам нужно установить пакет Dask (он есть в Anaconda по умолчанию).
#If you want to install dask completely
python -m pip install "dask[complete]"
#If you want to install dask core only
python -m pip install dask
После того, как вы установили dask, давайте попробуем функции Dask. Изначально мы могли запустить дашборд для отслеживания обработки данных.
import dask
from dask.distributed import Client, progress
client = Client(processes=False, threads_per_worker=4,
n_workers=1, memory_limit='2GB')
client
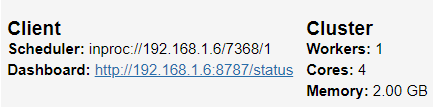
Dask предоставляет вам панель управления клиента в другом порту, к которому вы можете получить доступ после его запуска. Когда вы нажимаете на ссылку Dashboard, она будет выглядеть, как на следующем изображении.
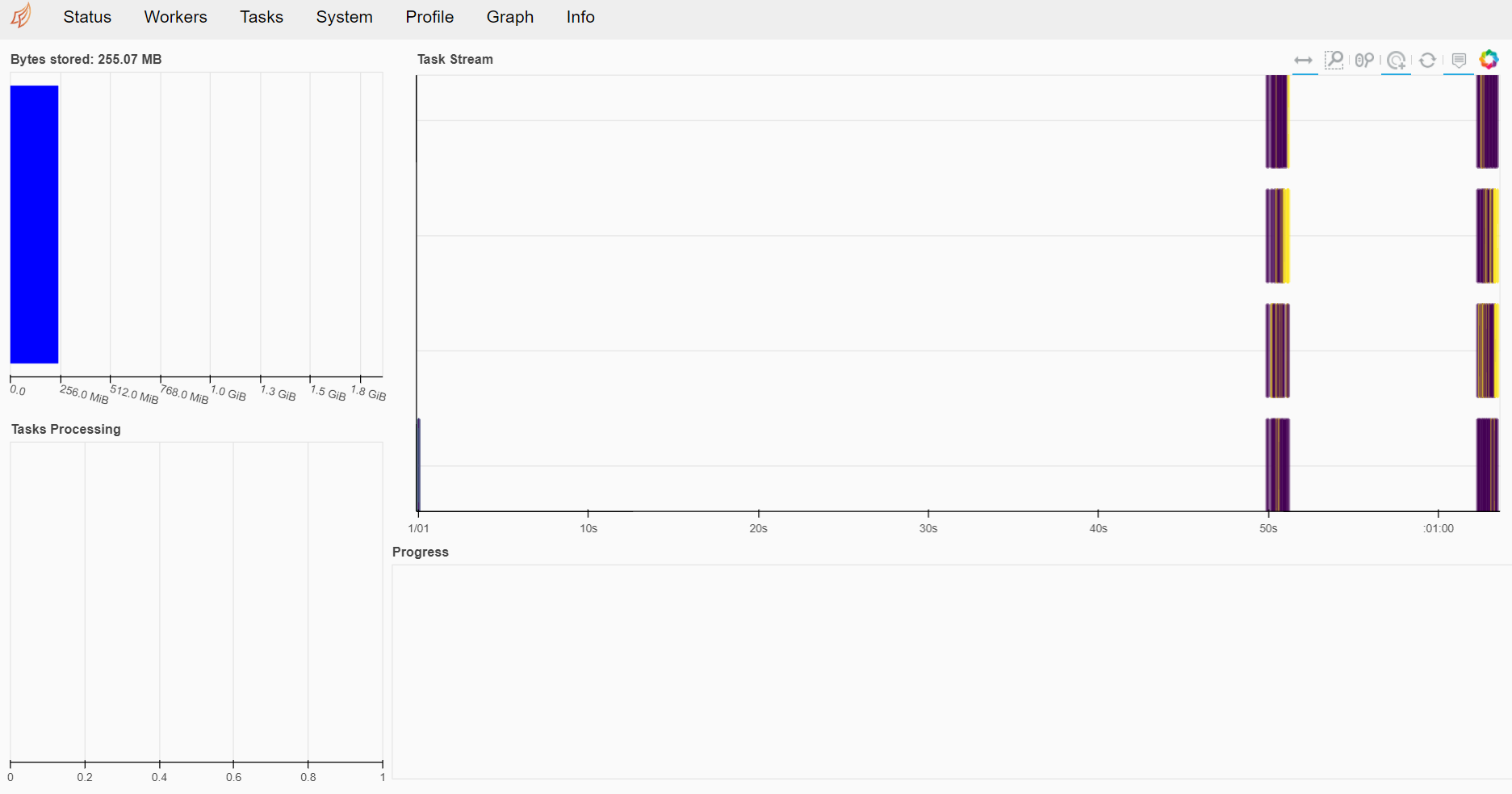
Я бы сказал, что эту панель управления легко понять, и она включает в себя все ваши текущие действия с dask. Вы можете попробовать проверить все красивые вкладки, которые есть на панели инструментов dask, но пока продолжим. Попробуем пока создать массив dask. (что-то вроде того, что есть у Numpy)
import dask.array as da
x = da.random.random((10000, 10000), chunks=(1000, 1000))
x
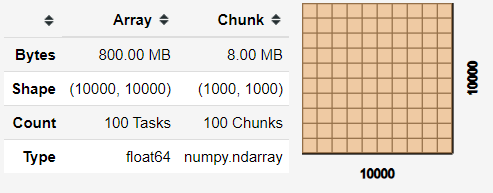
Когда массив dask был создан, вы получаете матричную информацию, как указано выше. Этот массив станет вашей базой для фрейма данных dask. Попробуем создать набор данных из dask, чтобы иметь более подробный пример.
df = dask.datasets.timeseries()
df
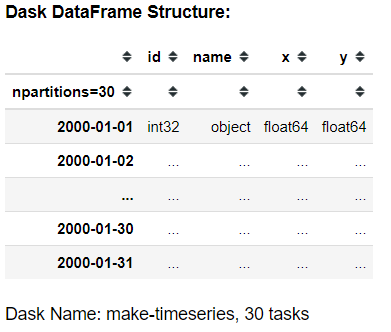
Фрейм данных Dask имеет аналогичную структуру с объектом фрейма данных Pandas, но поскольку фрейм данных Dask является ленивым, он не будет печатать данные в вашем Jupyter Notebook. Однако вы можете выполнять многие функции, которые существовали в Pandas на Dask. Возьмем для этого несколько примеров.
df.head ()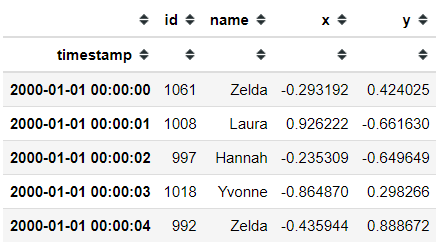
Если вы используете функцию .head, вы можете распечатать пять первых данных. Если вы хотите сделать условный выбор, он по-прежнему похож на Pandas. Хотя для его выполнения нужна специальная функция. Позвольте мне показать вам пример кода.
df [df ['x']> 0,9]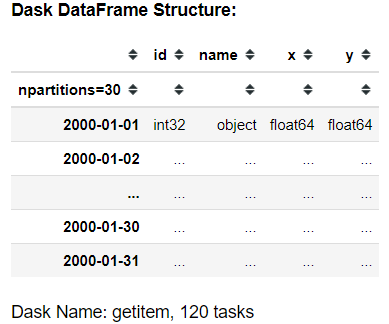
Если вы сделаете это нормально, вы получите структуру фрейма данных dask. Если вы хотите получить фрейм данных Pandas, вам необходимо использовать функцию .compute.
df [df ['x']> 0.9] .compute ()
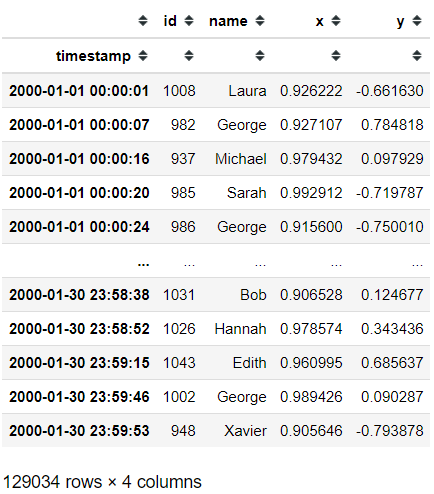
Это фактические данные, которые вы получаете при вычислении условного выбора фрейма данных dask. В dask все связано с параллельными и быстрыми вычислениями, поэтому, если вы решите использовать dask, лучше познакомиться с Pandas. Идеальная ситуация для dask - это когда у вас большой набор вычислительных данных, но если ваши данные удобно обрабатываются с помощью оперативной памяти вашего компьютера, придерживайтесь Pandas. Есть еще очень много вещей, которые вы можете сделать с помощью dask; я предлагаю вам посетить их веб-сайт, чтобы узнать больше.
3. Vaex
Vaex - это пакет Python, используемый для обработки и изучения больших наборов табличных данных с интерфейсами, подобными Pandas. Документация Vaex показывает, что он может вычислять статистику, такую как среднее значение, сумма, количество, стандартное отклонение и т. д., на N-мерной сетке до миллиарда (109) объектов / строк в секунду. Это означает, что Vaex - это альтернатива Pandas, которая также используется для улучшения времени выполнения.
Рабочий процесс Vaex похож на Pandas API, что означает, что если вы уже знакомы с Pandas, вам не составит труда использовать Vaex. Начнем пример с установки Vaex.
pip install vaexКогда вы закончите установку пакета Vaex, мы могли бы попробовать использовать пример набора данных для просмотра фрейма данных Vaex.
import vaex
df = vaex.example()
df
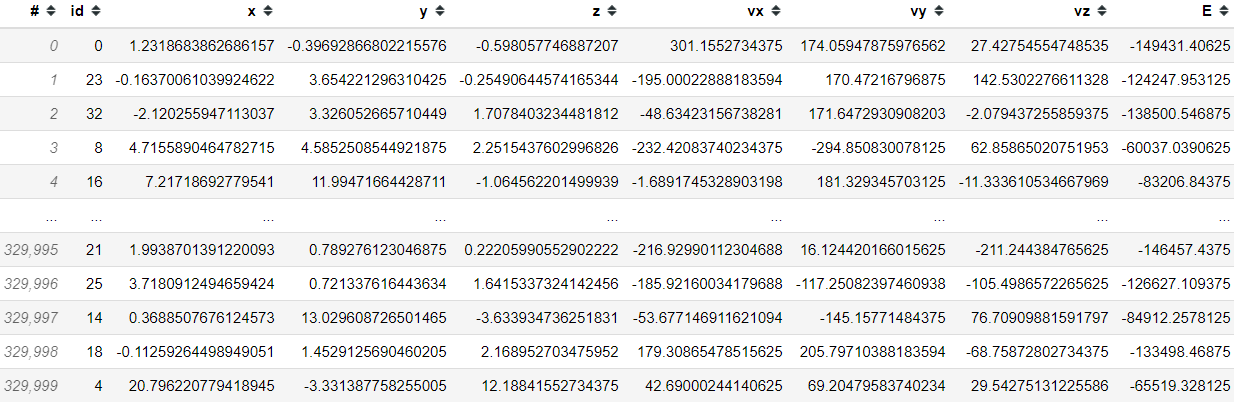
Подобно приложению Pandas, вы можете сделать условный выбор.
df [df ['x']> 88]
Однако только в документации Vaex сказано: «Ключевая особенность Vaex - чрезвычайно эффективный расчет статистики на N-мерных сетках. Это довольно полезно для визуализации больших наборов данных ». Попробуем использовать простые статистические методы.
df.count (), df.max ('x'), df.mean ('L')
Результат представлен в виде объекта массива с подробной информацией о типе данных значения. Еще одна функция, которую реализует Vaex, - это функция построения графика, где вы можете применить статистическую функцию к функции построения графика. Например, вместо использования обычной статистики подсчета я использую среднее значение столбца «E» с ограничением 99,7% только отображаемых данных.
df.plot1d (df ['x'], what = 'mean (E)', limits = '99,7% ')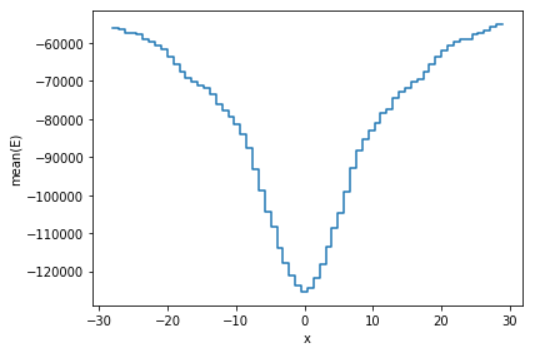
Для более продвинутых функций построения графиков вы можете посетить документацию Vaex. Что важно знать, так это то, что преимуществом Vaex является их быстрые статистические вычисления и возможность визуализации больших данных. Однако, если у вас меньший набор данных, вы можете придерживаться Pandas.
Выводы
Как специалист по данным, использующий Python в качестве инструмента анализа, вы наверняка воспользуетесь пакетом Pandas, чтобы помочь в исследовании данных. Однако есть несколько альтернатив Pandas, которые вы можете использовать - особенно когда вы имеете дело с большими данными, это:
- Polars
- Dask
- Veux
Я надеюсь, что это поможет!