Введение в предварительную обработку данных с использованием количественного распознавания эмоций

Пожалуй, единственное, что в машинном обучении важнее, чем само машинное обучение, — это предварительная обработка данных
Это потому, что до машинного обучения было определено:
~science~ математика получения информации из реального мира, преобразования ее в числа, а затем ~finding~ изучения закономерности на ее основе
Информация в реальном мире приносит с собой тонну шума
Пример данных из реального мира
Как сторонник того, чтобы учиться, пачкая руки, приведу пример.
Есть нечто, называемое циркумплексом Рассела, что помогает количественно оценить эмоции
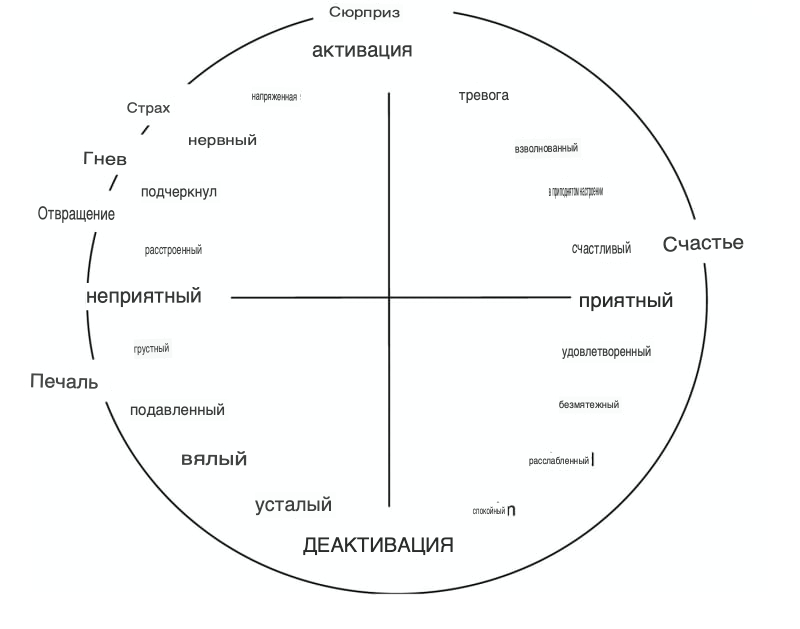
Потому что алгоритмы машинного обучения лучше всего обучаются, когда данные, с которыми они работают, представляют собой непрерывные числа, а не традиционные закодированные данные классификации, такие как
| Счастливый | Грустный | Гневный | Взволнованный | Испуганный |
| 0 | 1 | 2 | 3 | 4 |
В то время как классифицированные данные действительно представляют числа, числовое значение класса не всегда представляет интенсивность эмоции, в то время как модель Рассела дает вам значение активации и приятности, которые уже являются интенсивностью эмоции.
Нечистые данные
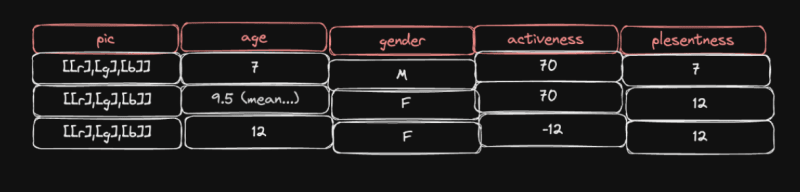
Скажем, мы находим набор данных с параметрами, которые мы ищем
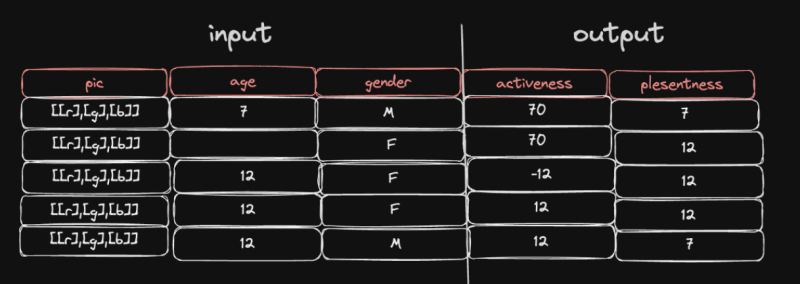
Здесь столбец pic представляет собой трехмерный массив значений красного, зеленого и синего пикселей изображения, содержащего эмоцию, а остальные довольно прямолинейны.
Шаг - 1: Разделение данных
Вся цель обучения модели ML состоит в том, чтобы мы могли использовать ее для активного прогнозирования результатов на невидимых данных/ситуациях. Простой способ сделать это:
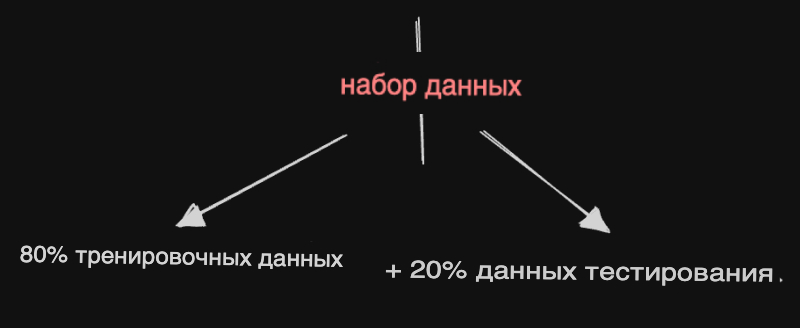
Оставшиеся 20% могут быть использованы для оценки эффективности разработанной модели.
Шаг - 2: Работа с отсутствующими данными
Обратите внимание, что в столбце age отсутствуют некоторые данные, так что есть 2 распространенных способа работы с этими отсутствующими данными.
- Удаление целых строк при отсутствии нужного столбца

Примечание: отлично работает для сверхбольших наборов данных, но так как больше данных = лучше...
- Подстановка среднего значения столбца (зависит от типа данных)
Шаг - 3: Работа с данными класса
Во многих случаях данные в наборах данных являются данными класса, и хотя закодированные данные класса могут не всегда точно отражать интенсивность параметра, что-то лучше, чем ничего.
Есть 2 распространенных способа работы с данными класса, давайте возьмем столбец gender
- Одно горячее кодирование

Когда один столбец разбивается на несколько столбцов класса, например, у gender есть 2 класса: мужской и женский, поэтому столбцы пола разбиваются на 2 столбца: мужской столбец и женский столбец
- Кодировка label

Для столбцов с двоичными классами, такими как true или false, male или female, yes или no и т.д., Чтобы одна метка класса была заменена на 0, а другая на 1
Шаг 4: Масштабирование функций
Разные столбцы обычно представляют разные параметры, и не все параметры имеют одинаковую пропорцию. предполагая набор данных о возрасте и росте, столбец "Возраст" имеет диапазон от 1 до 100, в то время как столбец height, возможно, имеет диапазон от 100 см до 200 см.
Почему это так важно?
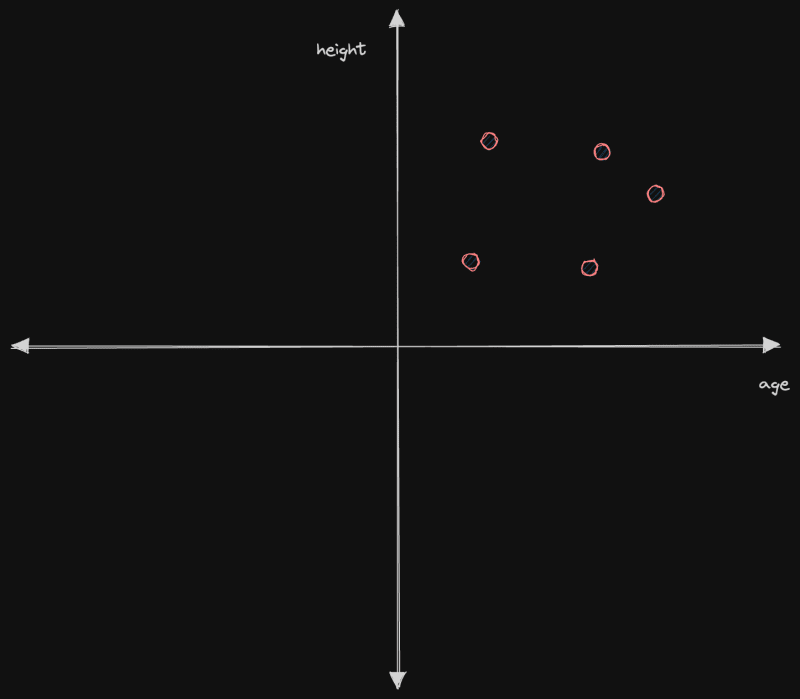
Когда мы построим график этих значений, не масштабируя их до одного и того же диапазона, это будет выглядеть следующим образом
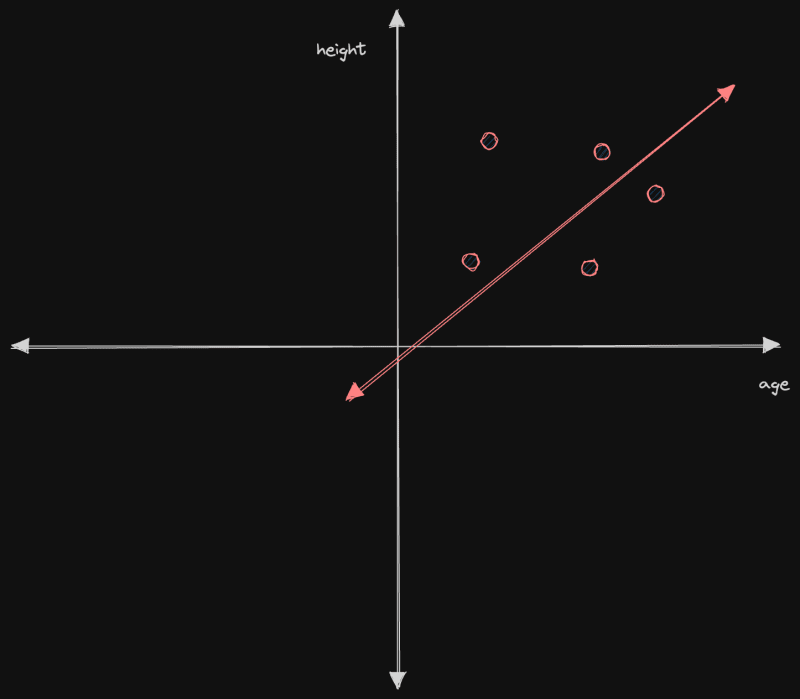
И давайте предположим, что мы попытались найти линию, которая наилучшим образом проходила бы через точки, как это выглядело бы
Однако, если бы мы масштабировали входные данные до того же диапазона, это выглядело бы примерно так
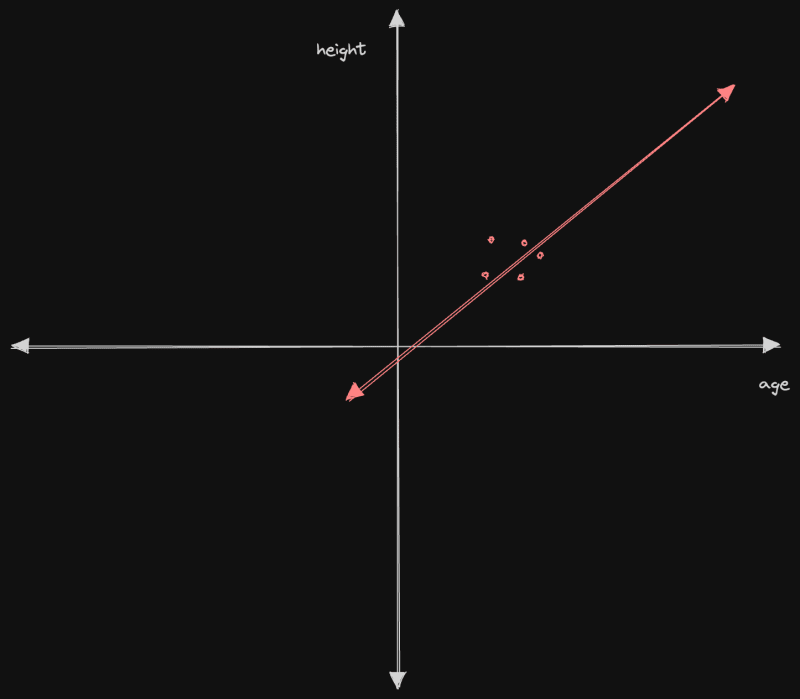
Что даже с первого взгляда мы можем сказать, что линия лучше соответствует модели, т.е. меньше ошибок для предсказания невидимых данных.
Tеперь масштабирование функций обычно выполняется с использованием 2 методов:
- нормализация
- стандартизация

Где, x — текущий ввод, который мы хотим масштабировать, вот пример нормализации набора данных, над которым мы работали.

Это оставляет нам готовый набор данных для обучения.

Шаг - 5: Работа с данными тестирования
Мы выполнили большую предварительную обработку обучающего набора данных, и данные тестирования будут выглядеть как нечистые обучающие данные.
Поэтому мы должны помнить, что:
- замените отсутствующие данные средним значением обучающих данных
- закодируйте данные класса в соответствии с данными обучения
- масштабирование объектов с использованием параметров обучающих данных
Вы понимаете, что мы использовали точно такие же инструменты работы, которые использовались в обучающем наборе данных, для операции, которую мы выполняли бы в тестовом наборе данных
Люди, занимающиеся обработкой данных, не должны становиться врачами 😝
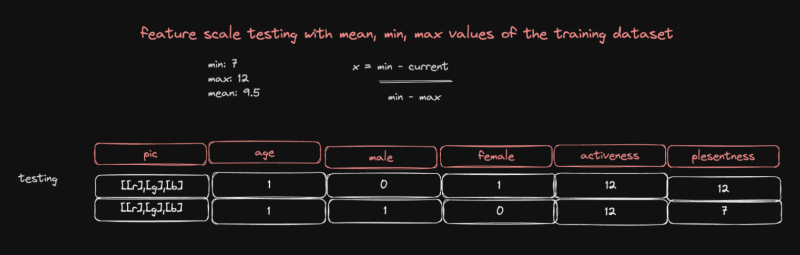
И теперь у нас есть данные тестирования, которые готовы к использованию в нашей модели ML