Ввод данных в OpenSearch с помощью Apache Kafka и Go

В некоторых случаях может потребоваться написать собственный интеграционный слой для выполнения определенных требований в конвейере обработки данных. Узнайте, как сделать это с помощью Kafka и OpenSearch, используя Go.
Масштабируемый ввод данных является ключевым аспектом для такой крупномасштабной и распространённой поисково-аналитической системы, такой как OpenSearch. Одним из способов построения конвейера ввода данных в реальном времени является использование Apache Kafka. Это платформа потоковой передачи событий с открытым исходным кодом, которая используется для обработки больших объемов (и скоростей) данных и интегрируется с различными источниками, включая реляционные и NoSQL-базы данных. Например, один из канонических сценариев использования - синхронизация данных в реальном времени между разнородными системами (исходными компонентами) для обеспечения свежести индексов OpenSearch, которые могут быть использованы для аналитики или потребления последующими приложениями через информационные панели и визуализации.
В этой статье мы расскажем о том, как создать конвейер данных, с которым записанные данные в Apache Kafka, будут поступать в OpenSearch. Мы будем использовать Amazon OpenSearch Serverless, Amazon Managed Streaming for Apache Kafka (Amazon MSK) Serverless. Kafka Connect отлично подходит для таких требований. Оно предоставляет коннекторы для OpenSearch, а также ElasticSearch (который можно использовать, если вы выбрали OSS-движок ElasticSearch вместе с Amazon OpenSearch). Однако иногда возникают специфические требования или причины, которые могут потребовать использования специализированного решения.
Например, вы можете использовать источник данных, который не поддерживается Kafka Connect (это редкость, но может случаться), и не хотите писать его с нуля. Или это может быть разовая интеграция, и вы размышляете, стоит ли тратить усилия на установку и настройку Kafka Connect. Возможно, есть и другие проблемы, такие как лицензирование и т.д.
К счастью, Kafka и OpenSearch предоставляют клиентские библиотеки для различных языков программирования, что позволяет написать собственный интеграционный слой. Именно об этом и пойдет речь в данном блоге! Мы будем использовать пользовательское Go-приложение для получения данных с помощью Go-клиентов для Kafka и OpenSearch.
Вы изучите:
- Обзор настройки необходимых сервисов AWS - OpenSearch Serverless, MSK Serverless, AWS Cloud9, а также политик IAM и конфигураций безопасности.
- Высокоточное описание приложения.
- Запуск конвейера ввода данных.
- Запрос данных в OpenSearch.
Прежде чем перейти к деталям, приведем краткий обзор OpenSearch Serverless и Amazon MSK Serverless.
Введение в Amazon OpenSearch Serverless и Amazon MSK Serverless
OpenSearch - поисково-аналитический движок с открытым исходным кодом, используемый для анализа журналов, мониторинга в реальном времени и анализа потоков кликов. Amazon OpenSearch Service - управляемый сервис, упрощающий развертывание и масштабирование кластеров OpenSearch в AWS.
Amazon OpenSearch Service поддерживает OpenSearch и устаревшую OSS Elasticsearch (до версии 7.10, последней версии ПО с открытым исходным кодом). При создании кластера есть возможность выбрать, какую поисковую систему использовать.
Для представления кластера можно создать домен службы OpenSearch (синоним кластера OpenSearch), в котором каждый экземпляр Amazon EC2 выступает в качестве узла. Однако OpenSearch Serverless устраняет операционные сложности, обеспечивая бессерверную конфигурацию сервиса OpenSearch по требованию. Он использует коллекции индексов для поддержки конкретных рабочих нагрузок и, в отличие от традиционных кластеров, разделяет компоненты индексирования и поиска, а в качестве основного хранилища для индексов используется Amazon S3. Такая архитектура позволяет независимо масштабировать функции поиска и индексирования.
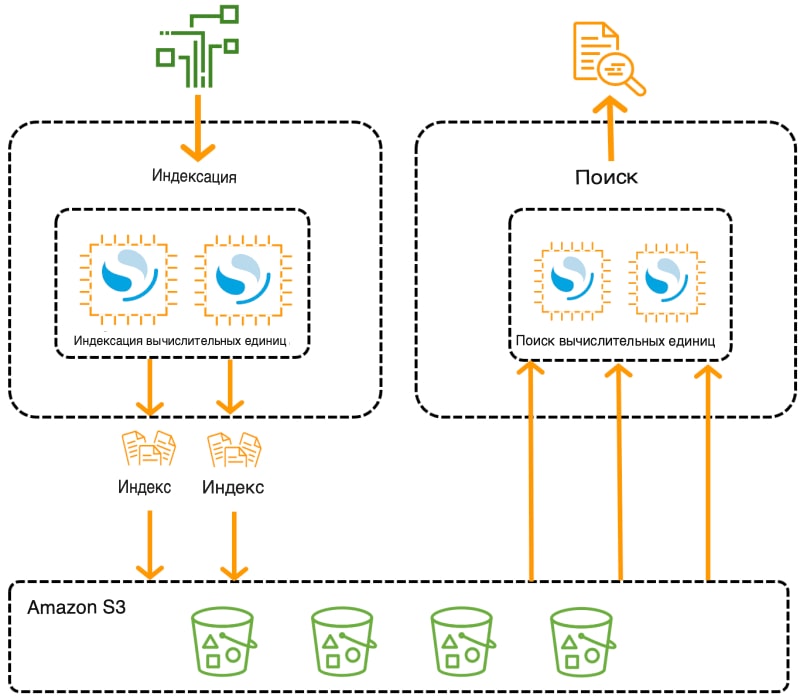
Amazon MSK (Managed Streaming for Apache Kafka) - это полностью управляемый сервис для обработки потоковых данных с помощью Apache Kafka. Он выполняет такие операции по управлению кластером, как создание, обновление и удаление. Вы можете использовать стандартные операции с данными Apache Kafka для получения и потребления данных без модификации своих приложений. Поддерживаются версии Kafka с открытым исходным кодом, что обеспечивает совместимость с существующими инструментами, плагинами и приложениями.
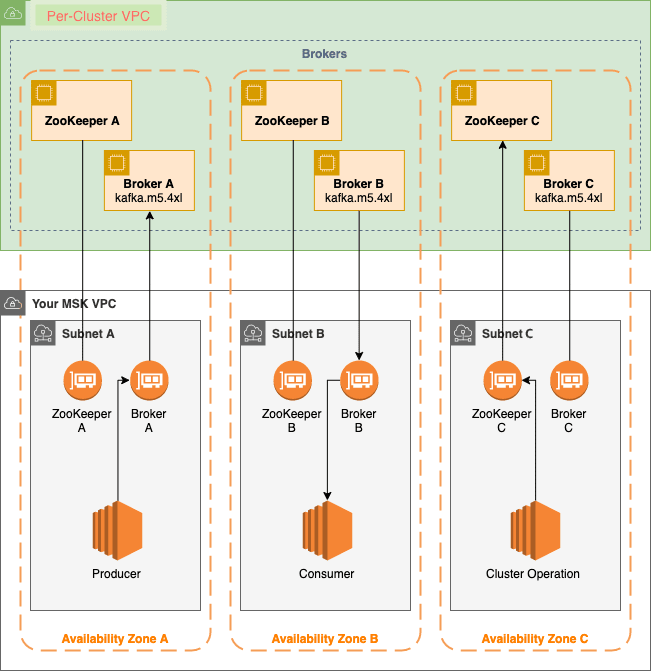
MSK Serverless - это тип кластера в Amazon MSK, который устраняет необходимость в ручном управлении и масштабировании мощности кластера. Он автоматически выделяет и масштабирует ресурсы в зависимости от спроса и берет на себя управление разделами темы. Модель ценообразования с оплатой по факту использования позволяет платить только за фактическое использование. MSK Serverless идеально подходит для приложений, требующих гибкого и автоматического масштабирования потоковой мощности.
Прежде чем перейти к рассмотрению архитектурных особенностей, давайте обсудим архитектуру приложения.
Обзор приложения и основные архитектурные особенности
Ниже приведен упрощенный вариант архитектуры приложения, в котором описаны компоненты и их взаимодействие друг с другом.
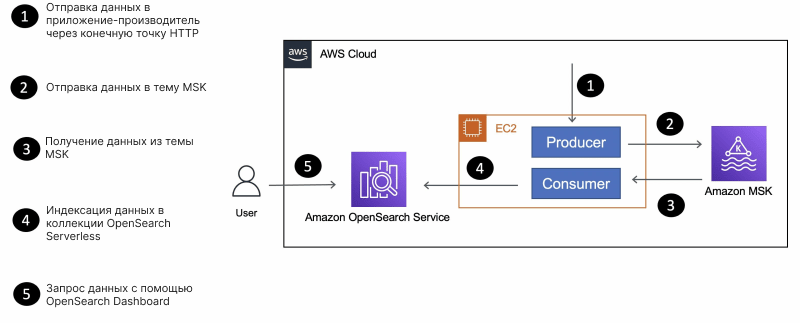
Приложение состоит из компонентов производителя (producer) и потребителя (consumer), которые представляют собой Go-приложения, развернутые на экземпляре EC2:
- Как следует из названия, производитель отправляет данные в бессерверный кластер MSK.
- Приложение-потребитель получает данные (информацию
movie) из темы MSK Serverless и использует Go-клиент OpenSearch для индексации данных в коллекцииmovie.
Ориентация на простоту
Стоит отметить, что эта статья в блоге оптимизирована для простоты и легкости понимания, поэтому решение не приспособлено для работы с производственными нагрузками. Ниже приведены некоторые упрощения, которые были сделаны:
- Приложения-производители и приложения-потребители работают на одной вычислительной платформе (экземпляр
EC2). - Экземпляр потребительского приложения single обрабатывает данные из темы MSK. Однако можно попробовать запустить несколько экземпляров потребительского приложения и посмотреть, как распределяются данные между экземплярами.
- Вместо использования Kafka CLI для получения данных было написано пользовательское приложение-продюсер на языке Go с конечной точкой REST для отправки данных. Это демонстрирует, как написать приложение-продюсер Kafka на языке Go, имитирующее Kafka CLI.
- Объем используемых данных невелик.
- Коллекция OpenSearch Serverless имеет тип доступа Public.
Если речь идет о производственной нагрузке, то вот некоторые моменты, которые следует учитывать:
- Выберите подходящую вычислительную платформу для вашего потребительского приложения, исходя из объема данных и требований к масштабируемости - подробнее об этом ниже.
- Выберите тип доступа VPC для вашей коллекции OpenSearch Serverless.
- Рассмотрите возможность использования Amazon OpenSearch Ingestion для создания конвейеров данных.
Если вам всё же необходимо развернуть пользовательское приложение для построения конвейера передачи данных из MSK в OpenSearch, то вот ряд вариантов вычислений, которые вы можете выбрать:
- Контейнеры - Вы можете упаковать свое потребительское приложение в контейнер Docker (
Dockerfileдоступен в репозитории GitHub) и развернуть его на Amazon EKS или Amazon ECS. - При развертывании приложения на Amazon EKS можно также рассмотреть возможность использования KEDA для автоматического масштабирования потребительского приложения в зависимости от количества сообщений в теме MSK.
- Бессерверный подход - MSK также можно использовать в качестве источника событий для функций AWS Lambda. Вы можете написать свое потребительское приложение в виде Lambda-функции и настроить его на запуск по событиям MSK или запустить его на AWS Fargate.
- Поскольку приложение-производитель представляет собой REST API, его можно развернуть в AWS App Runner.
- Наконец, можно использовать группы Amazon EC2 Auto Scaling для автоматического масштабирования парка EC2 для потребительского приложения.
Существует достаточно материалов, рассказывающих о том, как использовать Java-приложения Kafka для подключения к MSK Serverless с помощью IAM.
Давайте сделаем небольшой экскурс в понимание того, как это работает в Go.
Как клиентские приложения Go аутентифицируются в MSK Serverless с помощью IAM?
MSK Serverless требует контроля доступа IAM для аутентификации и авторизации в кластере MSK. Это означает, что клиентские приложения MSK (в данном случае производитель и потребитель) должны использовать IAM для аутентификации в MSK, на основании которой им будут разрешены или запрещены определенные действия с Apache Kafka.
Хорошо, что клиентская библиотека franz-go Kafka поддерживает IAM-аутентификацию. Ниже приведены фрагменты из потребительского приложения, показывающие, как это работает на практике:
func init() {
//......
cfg, err = config.LoadDefaultConfig(context.Background(), config.WithRegion("us-east-1"), config.WithCredentialsProvider(ec2rolecreds.New()))
creds, err = cfg.Credentials.Retrieve(context.Background())
//....
func initializeKafkaClient() {
opts := []kgo.Opt{
kgo.SeedBrokers(strings.Split(mskBroker, ",")...),
kgo.SASL(sasl_aws.ManagedStreamingIAM(func(ctx context.Context) (sasl_aws.Auth, error) {
return sasl_aws.Auth{
AccessKey: creds.AccessKeyID,
SecretKey: creds.SecretAccessKey,
SessionToken: creds.SessionToken,
UserAgent: "msk-ec2-consumer-app",
}, nil
})),
//.....- Сначала приложение использует провайдер учетных данных
ec2rolecreds.New()для получения временных учетных данных IAM из службы метаданных экземпляра EC2. Роль экземпляра EC2 должна иметь соответствующую роль IAM (с правами) для выполнения необходимых операций над компонентами кластера MSK (подробнее об этом в последующих разделах). - Эти учетные данные затем используются для инициализации клиента Kafka с реализацией аутентификации
AWS_MSK_IAMSASL в пакете sasl_aws.
Примечание: поскольку существует множество Go-клиентов для Kafka (включая Sarama), обязательно обратитесь к документации по их клиентам, чтобы уточнить, поддерживают ли они IAM-аутентификацию.
Итак, давайте настроим сервисы, необходимые для работы нашего конвейера обработки данных.
Настройка инфраструктуры
Этот раздел поможет вам настроить следующие компоненты:
- Необходимые роли IAM
- Кластер MSK Serverless
- Коллекция OpenSearch Serverless
- Среда AWS Cloud9 EC2 для запуска приложения
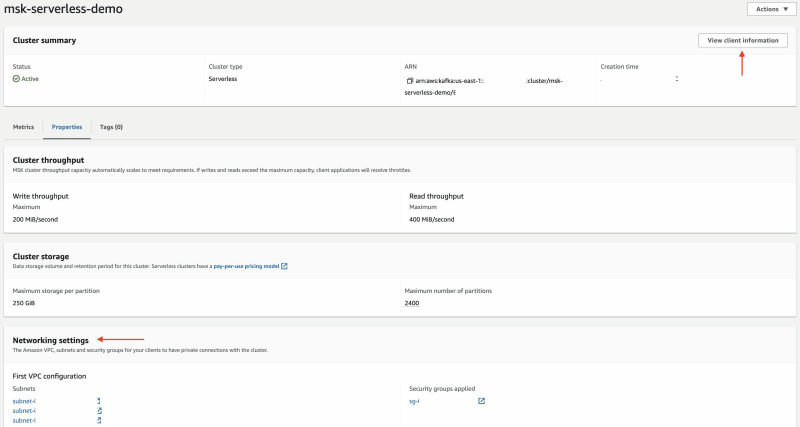
Кластер MSK Serverless
Для настройки бессерверного кластера MSK с помощью консоли AWS можно воспользоваться этой документацией. После этого запишите следующую информацию о кластере - VPC, подсеть, группу безопасности (вкладка Properties) и конечную точку кластера (щёлкните View client information).
Роль приложения IAM
Существуют различные IAM-роли, которые понадобятся для выполнения данного руководства.
Начните с создания IAM-роли для выполнения последующих шагов и использования OpenSearch Serverless в целом с правами согласно шагу: Настройка прав в документации Amazon OpenSearch.
Создайте еще одну IAM-роль для клиентских приложений, которые будут взаимодействовать с кластером MSK Serverless и использовать клиент OpenSearch Go для индексирования данных в коллекции OpenSearch Serverless. Создайте встроенную IAM-политику, как показано ниже, - не забудьте подставить необходимые значения.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"kafka-cluster:*"
],
"Resource": [
"<ARN of the MSK Serverless cluster>",
"arn:aws:kafka:us-east-1:<AWS_ACCOUNT_ID>:topic/<MSK_CLUSTER_NAME>/*",
"arn:aws:kafka:us-east-1:AWS_ACCOUNT_ID:group/<MSK_CLUSTER_NAME>/*"
]
},
{
"Effect": "Allow",
"Action": [
"aoss:APIAccessAll"
],
"Resource": "*"
}
]
}Используйте следующую политику Trust:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "ec2.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}Наконец, еще одна IAM-роль, к которой будут прикреплены политики доступа к OpenSearch Serverless Data - подробнее об этом в следующем шаге.
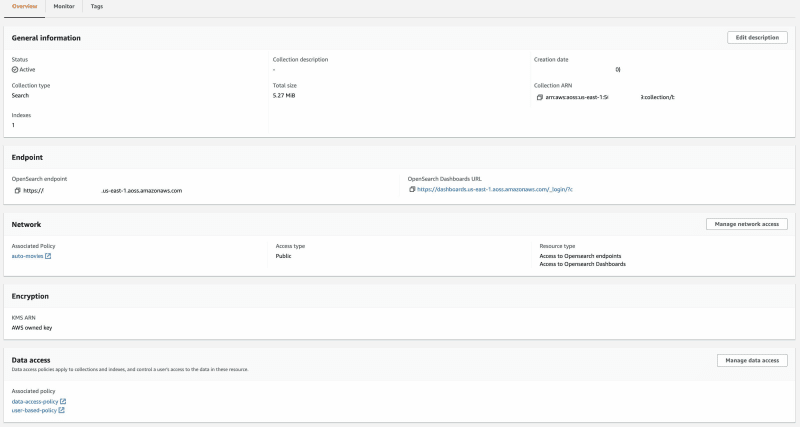
Коллекция OpenSearch Serverless
Давайте создадим бессерверную коллекцию OpenSearch. Следуя шагу: Создание коллекции, обязательно настройте две политики Data, т.е. по одной для IAM-ролей.
Обратите внимание, что для целей данного руководства мы выбрали тип доступа Public. Для производственных рабочих нагрузок рекомендуется выбирать VPC.
Среда AWS Cloud9 EC2
При создании среды разработки AWS Cloud9 EC2 - обязательно используйте тот же VPC, что и кластер MSK Serverless.
После завершения работы необходимо выполнить следующие действия: Откройте среду Cloud9, в разделе EC2 Instance нажмите Manage EC2 instance. В экземпляре EC2 перейдите в раздел Security и обратите внимание на прикрепленную группу безопасности.
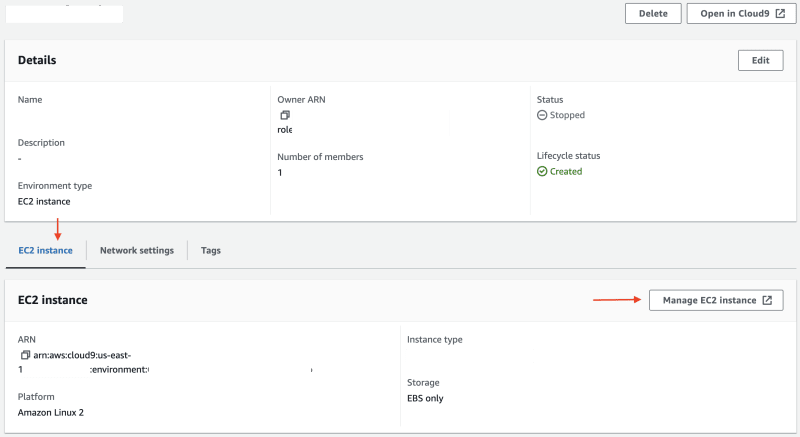
Откройте группу безопасности, связанную с кластером MSK Serverless, и добавьте входящее правило, разрешающее подключение к нему экземпляра Cloud9 EC2. Выберите группу безопасности экземпляра Cloud9 EC2 в качестве источника, 9098 в качестве Port и протокол TCP.
Запуск приложения
Выберите среду Cloud9 и выберите Open in Cloud9 для запуска IDE. Откройте окно терминала, клонируйте репозиторий GitHub и смените каталог на папку.
git clone https://github.com/build-on-aws/opensearch-using-kafka-golang
cd opensearch-using-kafka-golangЗапустите приложение producer:
cd msk-producer
export MSK_BROKER=<enter MSK Serverless cluster endpoint>
export MSK_TOPIC=movies
go run main.goВ терминале должны появиться следующие журналы:
MSK_BROKER <MSK Serverless cluster endpoint>
MSK_TOPIC movies
starting producer app
http server readyДля отправки данных на бессерверный кластер MSK используйте bash-скрипт, который вызовет конечную точку HTTP, открытую запущенным приложением, и отправит данные movie (из файла movies.txt) в формате JSON с помощью curl:
./send-data.shВ журнале терминала приложения producer должен появиться вывод, подобный этому:
producing data to topic
payload {"directors": ["Joseph Gordon-Levitt"], "release_date": "2013-01-18T00:00:00Z", "rating": 7.4, "genres": ["Comedy", "Drama"], "image_url": "http://ia.media-imdb.com/images/M/MV5BMTQxNTc3NDM2MF5BMl5BanBnXkFtZTcwNzQ5NTQ3OQ@@._V1_SX400_.jpg", "plot": "A New Jersey guy dedicated to his family, friends, and church, develops unrealistic expectations from watching porn and works to find happiness and intimacy with his potential true love.", "title": "Don Jon", "rank": 1, "running_time_secs": 5400, "actors": ["Joseph Gordon-Levitt", "Scarlett Johansson", "Julianne Moore"], "year": 2013}
record produced successfully to offset 2 in partition 0 of topic movies
producing data to topic
payload {"directors": ["Ron Howard"], "release_date": "2013-09-02T00:00:00Z", "rating": 8.3, "genres": ["Action", "Biography", "Drama", "Sport"], "image_url": "http://ia.media-imdb.com/images/M/MV5BMTQyMDE0MTY0OV5BMl5BanBnXkFtZTcwMjI2OTI0OQ@@._V1_SX400_.jpg", "plot": "A re-creation of the merciless 1970s rivalry between Formula One rivals James Hunt and Niki Lauda.", "title": "Rush", "rank": 2, "running_time_secs": 7380, "actors": ["Daniel Br\u00c3\u00bchl", "Chris Hemsworth", "Olivia Wilde"], "year": 2013}
record produced successfully to offset 4 in partition 1 of topic movies
.....Для целей данного руководства, а также для простоты и легкости изложения материала, объем данных был намеренно ограничен 1500 записями, а скрипт намеренно «спит» в течение 1 секунды после отправки каждой записи производителю. Вы должны быть в состоянии комфортно следить за ходом работы.
Пока приложение-производитель занято отправкой данных в тему movie, можно запустить приложение-потребитель, которое начнет обрабатывать данные из кластера MSK Serverless и индексировать их в коллекции OpenSearch Serverless.
cd msk-consumer
export MSK_BROKER=<enter MSK Serverless cluster endpoint>
export MSK_TOPIC=movies
export OPENSEARCH_INDEX_NAME=movies-index
export OPENSEARCH_ENDPOINT_URL=<enter OpenSearch Serverless endpoint>
go run main.goВ терминале должен появиться следующий вывод, свидетельствующий о том, что он действительно начал получать данные с кластера MSK Serverless и индексировать их в коллекции OpenSearch Serverless.
using default value for AWS_REGION - us-east-1
MSK_BROKER <MSK Serverless cluster endpoint>
MSK_TOPIC movies
OPENSEARCH_INDEX_NAME movies-index
OPENSEARCH_ENDPOINT_URL <OpenSearch Serverless endpoint>
using credentials from: EC2RoleProvider
kafka consumer goroutine started. waiting for records
paritions ASSIGNED for topic movies [0 1 2]
got record from partition 1 key= val={"directors": ["Joseph Gordon-Levitt"], "release_date": "2013-01-18T00:00:00Z", "rating": 7.4, "genres": ["Comedy", "Drama"], "image_url": "http://ia.media-imdb.com/images/M/MV5BMTQxNTc3NDM2MF5BMl5BanBnXkFtZTcwNzQ5NTQ3OQ@@._V1_SX400_.jpg", "plot": "A New Jersey guy dedicated to his family, friends, and church, develops unrealistic expectations from watching porn and works to find happiness and intimacy with his potential true love.", "title": "Don Jon", "rank": 1, "running_time_secs": 5400, "actors": ["Joseph Gordon-Levitt", "Scarlett Johansson", "Julianne Moore"], "year": 2013}
movie data indexed
committing offsets
got record from partition 2 key= val={"directors": ["Ron Howard"], "release_date": "2013-09-02T00:00:00Z", "rating": 8.3, "genres": ["Action", "Biography", "Drama", "Sport"], "image_url": "http://ia.media-imdb.com/images/M/MV5BMTQyMDE0MTY0OV5BMl5BanBnXkFtZTcwMjI2OTI0OQ@@._V1_SX400_.jpg", "plot": "A re-creation of the merciless 1970s rivalry between Formula One rivals James Hunt and Niki Lauda.", "title": "Rush", "rank": 2, "running_time_secs": 7380, "actors": ["Daniel Br\u00c3\u00bchl", "Chris Hemsworth", "Olivia Wilde"], "year": 2013}
movie data indexed
committing offsets
.....После завершения процесса в коллекции OpenSearch Serverless должно быть проиндексировано 1500 фильмов. Однако не обязательно дожидаться окончания процесса. Когда в коллекции будет несколько сотен записей, можно перейти в Dev Tools на панели OpenSearch и выполнить приведенные ниже запросы.
Запрос данных о фильмах в OpenSearch
Выполнение простого запроса
Начнем с простого запроса, который должен перечислить все документы в индексе (без каких-либо параметров или фильтров).
GET movies-index/_search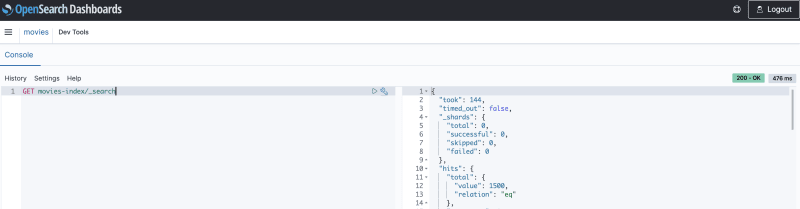
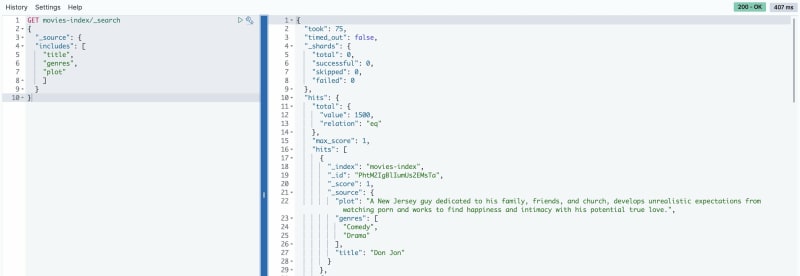
Получение данных только для определенных полей
По умолчанию поисковый запрос получает весь JSON-объект, который был предоставлен при индексировании документа. Для получения источника по выбранным полям можно использовать параметр _source. Например, чтобы получить только поля title, plot и genres, выполните следующий запрос:
GET movies-index/_search
{
"_source": {
"includes": [
"title",
"plot",
"genres"
]
}
}
Получение данных, соответствующих точному поисковому запросу Term Query
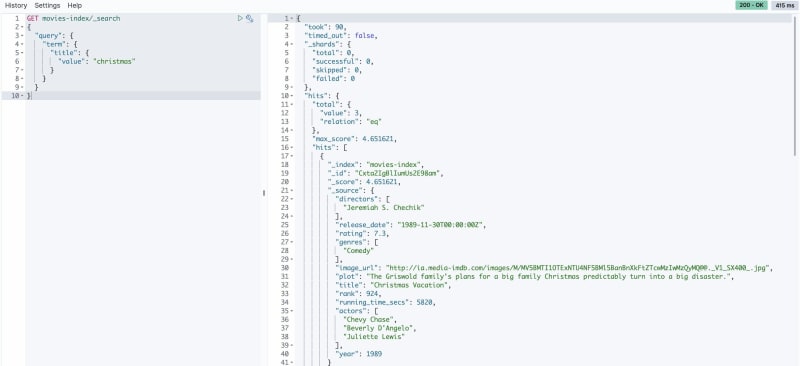
Для этого можно использовать запрос Term. Например, для поиска фильмов с термином christmas в поле title выполните следующий запрос:
GET movies-index/_search
{
"query": {
"term": {
"title": {
"value": "christmas"
}
}
}
}
**Скомбинируйте выборочный отбор полей с запросом термина
С помощью этого запроса можно получить только определенные поля, но с интересующими вас терминами:
GET movies-index/_search
{
"_source": {
"includes": [
"title",
"actors"
]
},
"query": {
"query_string": {
"default_field": "title",
"query": "harry"
}
}
}
Агрегация
Используйте агрегаты для вычисления суммарных значений на основе группировки значений в определенном поле. Например, можно суммировать такие поля, как ratings, genre и year, чтобы получить результаты поиска на основе значений этих полей. С помощью агрегирования можно ответить на вопросы типа "Сколько фильмов в каждом жанре?".
GET movies-index/_search
{
"size":0,
"aggs": {
"genres": {
"terms":{"field": "genres.keyword"}
}
}
}Очистка
После завершения демонстрации обязательно удалите все сервисы, чтобы избежать дополнительных расходов. Для удаления сервисов можно выполнить действия, описанные в соответствующей документации.
- Удалить бессерверную коллекцию OpenSearch
- Удалить кластер MSK Serverless
- Удалить среду Cloud9
- Также удалите роли и политики IAM
Заключение
Напомним, что вы развернули конвейер для ввода данных в OpenSearch Serverless с помощью Kafka, а затем запросили их различными способами. Попутно вы узнали об архитектурных особенностях и вариантах вычислений, которые следует учитывать при работе с производственными нагрузками, а также об использовании приложений Kafka на базе Go с аутентификацией MSK IAM. Я также рекомендую прочитать статью "Building a CRUD Application in Go for Amazon OpenSearch", особенно если вы ищете туториал, посвященный выполнению операций OpenSearch с помощью Go SDK.
Статья получилась довольно объемной (как мне кажется!). Спасибо, что дочитали до конца! Если вам понравился этот туториал, вы нашли какие-либо проблемы или у вас есть отзывы, пожалуйста, присылайте их нам!