Вычисление среднего значения DataFrame Pandas в Python

Мы знаем, что определение среднего значения — это сумма всех значений, деленная на количество значений. Аналогичным образом, метод mean() в Pandas также используется для расчета среднего значения значений в DataFrame. Его можно применить ко всему DataFrame или вдоль определенной оси (строки или столбцы). Этот метод особенно полезен для численного анализа данных.
Pandas метод DataFrame mean()
Мы должны помнить, что метод mean() возвращает серию, содержащую средние значения для каждого столбца или строки, в зависимости от указанной оси.
Синтаксис:
DataFrame.mean(axis=None, skipna=None, level=None, numeric_only=None)Параметры:
axis: {0 или «index», 1 или «columns»}, по умолчанию нет. Ось, по которой вычисляются средние значения. Если нет, выполнять вычисления по всем элементам.skipna: булевое значение, по умолчанию None. Исключите значения NA/null при вычислении результата. Если вся строка или столбец — NA, результат будет NA.level: целое число или имя уровня или список целых чисел или имен уровней, по умолчанию None. Если ось является MultiIndex, вычислите среднее значение по определенному уровню или уровню.numeric_only: булевое значение, по умолчаниюNone. Включите в расчет только данные с плавающей запятой, целые и логические значения. Если нет, будет предпринята попытка использовать все, а затем использовать только числовые данные. Не реализовано для Series.
Вычисление среднего значения DataFrame
Давайте создадим DataFrame, используя метод DataFrame() библиотеки pandas, чтобы продемонстрировать вычисление среднего значения DataFrame.
Пример фрейма данных:
import pandas as pd
import numpy as np
df= pd.DataFrame([[51,92,14],[71,60,20],[82,86,74],[74,87,90]],
index=('Bob', 'Sally', 'Frank', 'Claire'),
columns=('Monday','Tuesday','Wednesday')
)
dfВыход:
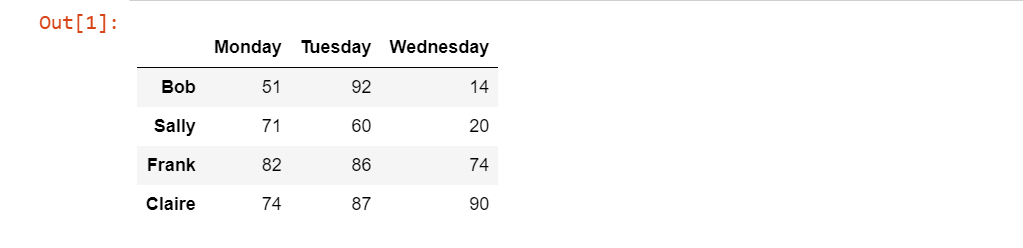
Среднее значение по столбцам
Мы можем вычислить среднее значение по столбцам, просто передав параметр axis в качестве index в функцию mean().
df.mean(axis='index')С помощью приведенного выше кода мы рассчитали среднее значение по столбцам DataFrame, df означает среднее значение за понедельник, вторник и среду.
Выход:

Среднее значение по строкам
Теперь, если мы хотим взять среднее значение по строкам, то есть среднее значение Боба, среднее значение Салли и так далее. Для этого мы можем сделать то же самое, что и выше, но вместо передачи axis='index' нам нужно передать axis='columns'.
df.mean(axis='columns')Выход:

Среднее значение по одному столбцу
Мы также можем вычислить среднее значение одного столбца в DataFrame, просто применив функцию среднего значения Pandas только к этому конкретному столбцу.
print(df['Monday'].mean())Мы применили функцию среднего значения Pandas только к столбцу понедельника DataFrame, чтобы мы могли получить среднее значение только для столбца понедельника.
Выход:

Обработка пропущенных значений при вычислении среднего значения
Когда у нас есть NaN или недоступные значения в DataFrame, как нам рассчитать среднее значение? Итак, чтобы продемонстрировать это, мы создадим еще один DataFrame и поместим в него одно значение np.nan, которое представляет собой просто недоступный номер.
import numpy as np
df = pd.DataFrame([('Foreign Cinema', 'Restaurant', 289.0),
('Liho Liho', 'Restaurant', 224.0),
('500 Club', 'bar', 80.5),
('The Square', 'bar', np.nan)],
columns=('name', 'type', 'AvgBill')
)
dfВыход:

Теперь, если мы запустим df.mean(), что означает среднее значение приведенного выше df DataFrame, то по умолчанию Pandas пропустит NaN.
df.mean()Выход:

Pandas пропустил значение NaN в 4-м столбце и вычислил среднее значение только для начальных трех столбцов, которое составляет 197,83.
Однако есть параметр Skipna, который по умолчанию имеет значение True, но теперь мы установим для него значение False, чтобы Pandas не могли пропускать значение NaN.
df.mean(skipna=False)Поскольку в четвертой строке было значение NaN, Pandas не может взять его среднее значение и возвращает нам NaN на выходе.
Заключение
Теперь, когда мы подошли к концу этой статьи, мы надеемся, что в ней подробно описаны различные способы найти среднее значение кадра данных Pandas с использованием функции mean() исключительно из библиотеки Pandas. Среднее значение, также известное как среднее арифметическое, представляет собой сумму всех значений, разделенную на количество значений, и может быть очень полезно, когда дело доходит до поиска среднего значения набора данных.