Замените несколько значений в DataFrame с помощью Pandas

Pandas — это библиотека анализа и обработки данных на Python, которая позволяет пользователю читать и работать с различными типами данных. Для хранения данных и управления ими Pandas использует DataFrames. DataFrames в Pandas — это двумерные изменяемые табличные структуры, содержащие строки и столбцы, очень похожие на электронную таблицу. В этой статье мы сосредоточимся на замене нескольких значений в DataFrame на Pandas, а также на некоторых примерах.
Методы замены нескольких значений в DataFrame
Существует множество способов заменить несколько значений в DataFrame. В этом разделе мы рассмотрим три различных метода достижения этой цели. Прежде чем мы начнем работать с DataFrames, мы должны убедиться, что Pandas установлен в нашей системе. Если нет, мы можем легко установить его в нашу систему с помощью команды ниже.
pip install pandasМы рассмотрим три различных метода:
- Использование
replace()со словарями - Использование
loc[]для условной замены значений - Использование регулярного выражения
Теперь давайте разберем эти методы на примерах.
Использование replace() со словарями
Самый простой способ заменить данные в DataFrame — использовать метод replace(). Давайте сначала разберемся в его синтаксисе.
Синтаксис:
DataFrame.replace(to_replace=None, value=_NoDefault.no_default, *, inplace=False, limit=None, regex=False)
to_replace: обязательный аргумент, указывающий значение, которое вы хотите заменить. Он уже должен присутствовать в DataFrame.value: альтернативное значение, которым вы хотите заменить исходное значение. Это тоже обязательный аргумент.inplace: необязательный аргумент, указывающий, изменяется ли DataFrame на месте.limit: устанавливает максимальное количество значений, которые можно заменить в DataFrame.regex: указывает, является ли значение регулярным выражением или нет.
Теперь давайте воспользуемся replace() в примере.
Пример:
Чтобы заменить значения, мы должны сначала создать DataFrame.
import pandas as pd
sample = pd.DataFrame([
['Rashmi', 'OS', 45],
['Subbu', 'IT', 32],
['Jaya', 'ML', 43],
['Manu', 'AI', 50]],
columns = ['Name', 'Deparment', 'age'],
)
print(sample)Наш DataFrame хранится в sample и содержит 3 столбца, которым присвоены имена столбцов с использованием списка columns.
Выход:
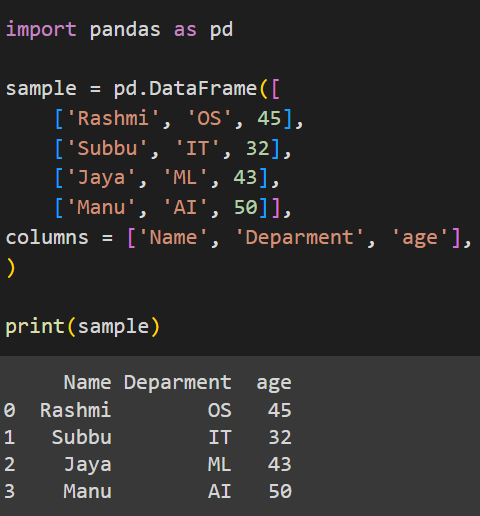
Это наш оригинальный, неизмененный DataFrame. Теперь, чтобы изменить его значения, мы будем использовать replace().
import pandas as pd
sample = pd.DataFrame([
['Rashmi', 'OS', 45],
['Subbu', 'IT', 32],
['Jaya', 'ML', 43],
['Manu', 'AI', 50]],
columns = ['Name', 'Deparment', 'age'],
)
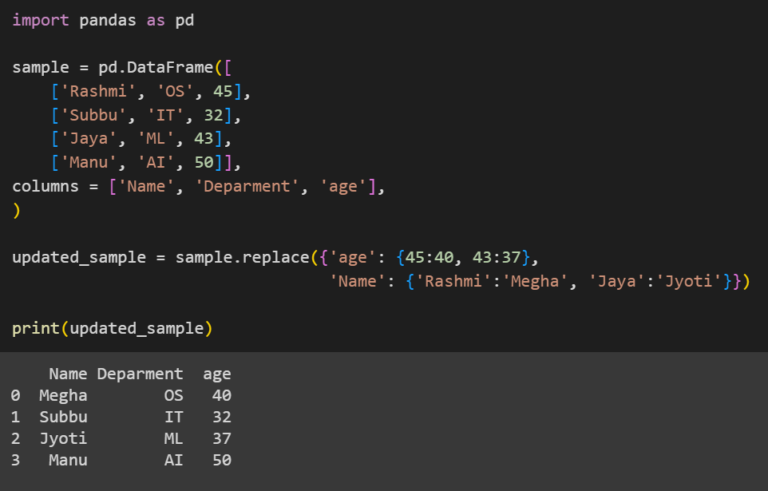
updated_sample = sample.replace({'age': {45:40, 43:37},
'Name': {'Rashmi':'Megha', 'Jaya':'Jyoti'}})
print(updated_sample)Здесь мы обновим значения, передав словари методу replace(). Мы сохраним измененный DataFrame в updated_sample. Мы получаем измененный DataFrame, печатая update_sample.
Выход:
Использование loc[] для условной замены значений
Если мы хотим заменить значения DataFrame на основе определенных условий, мы можем использовать атрибут loc[]. Он принимает имена строк и столбцов соответственно в качестве индексов и возвращает значения из DataFrame. Мы можем установить определенные ограничения или условия при передаче строк и столбцов в loc.
Пример:
import pandas as pd
sample = pd.DataFrame([
['Rashmi', 'OS', 45],
['Subbu', 'IT', 32],
['Jaya', 'ML', 43],
['Manu', 'AI', 50]],
columns = ['Name', 'Deparment', 'age'],
)
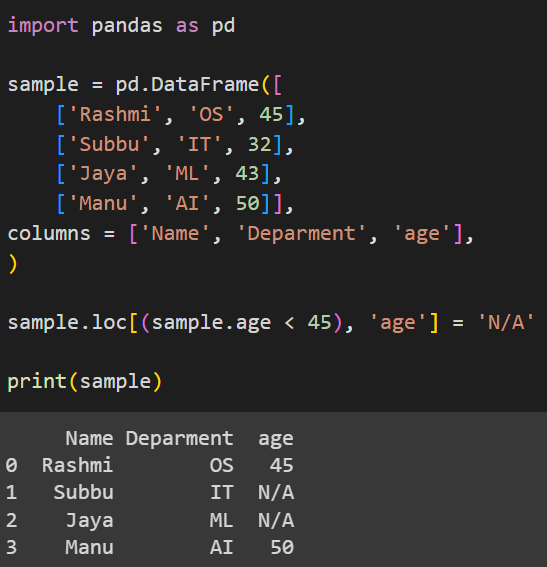
sample.loc[(sample.age < 45), 'age'] = 'N/A'
print(sample)Здесь мы используем атрибут loc в нашем sample DataFrame. Мы устанавливаем для строк условие, что возраст должен быть меньше 45 в выбранном столбце, в этом случае выбран столбец age. После того, как мы выбрали значения с помощью loc, мы присваиваем новое значение N/A для всех возрастов до 45 age в столбце возраста.
Выход:
Использование Regex
Regex (регулярные выражения) обычно используется для определения шаблона поиска с использованием определенной последовательности символов. Мы можем использовать шаблон регулярного выражения для поиска определенных данных и изменения их в DataFrame.
Пример:
import pandas as pd
sample = pd.DataFrame([
['Rashmi', 'OS', 45],
['Subbu', 'IT', 32],
['Jaya', 'ML', 43],
['Manu', 'AI', 50]],
columns=['Name', 'Department', 'Age']
)
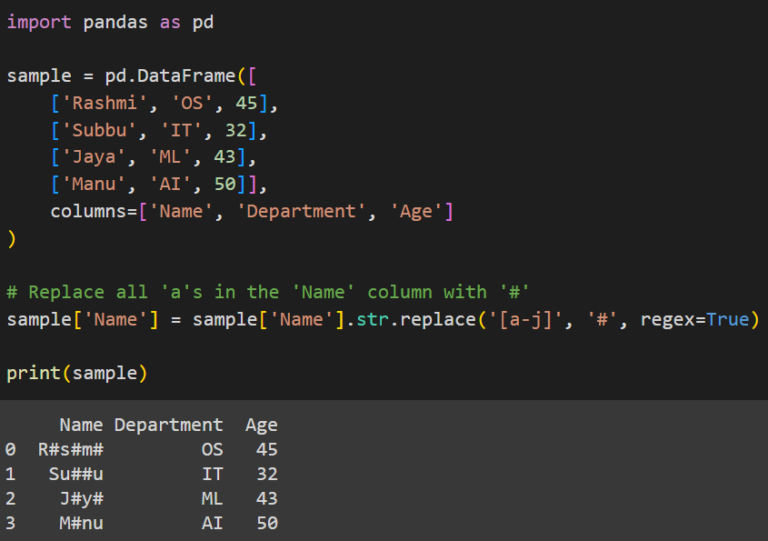
# Replace all 'a's in the 'Name' column with '#'
sample['Name'] = sample['Name'].str.replace('[a-j]', '#', regex=True)
print(sample)Здесь мы используем регулярное выражение [a-j], чтобы указать, что все символы от a до j, включая a, но не j (только символы до i), должны быть заменены. Символ, которым они заменяются, — #. Для параметра regex установлено значение True, поскольку мы используем регулярные выражения.
Выход:
Заключение
Изменение DataFrame — это важный навык, который необходимо знать, когда дело доходит до работы с DataFrame в Pandas. В этой статье мы рассмотрели три уникальных способа замены определенных значений строк и столбцов в DataFrame, используя функцию replace() со словарями, атрибут loc и шаблоны regex pattern для поиска подстрок. Понимание этих методов сделает манипулирование данными более простым и эффективным.