Запуск скриптов Python с помощью лямбд AWS

Как инженеру-программисту вам иногда приходится писать скрипт для добавления или обновления некоторых записей, которые вы не хотите обрабатывать в своей кодовой базе. Для нескольких записей вы можете запустить свой скрипт локально, даже для сотен записей вы можете использовать многопоточность, но когда вам приходится иметь дело с тысячами записей, этих методов недостаточно. Поэтому на помощь приходят лямбды AWS или функции GCP для оптимизации всего сценария, где вам не нужно беспокоиться о повторном запуске сценария в случае перебоев в работе сети или компьютера.
В этой статье вы узнаете, как эффективно обрабатывать большие обновления записей с помощью лямбд AWS, используя функцию драйвера и целевую функцию.
Настройка ваших лямбд
Создайте две лямбда-функции AWS, одну функцию-драйвер и другую целевую функцию. Драйверная функция обрабатывает аутентификацию источника (местоположение записи) и обработку данных перед асинхронным вызовом целевой функции.
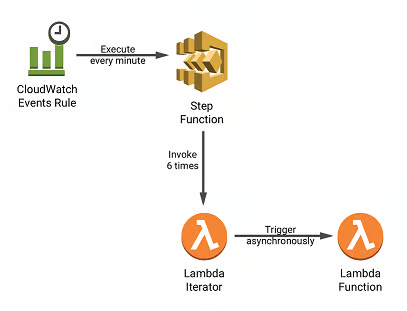
Например, если вам нужно изменить данные, хранящиеся в S3 bucket, вот простая функция драйвера/итератора:
import boto3
client = boto3.client('lambda')
def lambda_handler(event, context):
index = event['iterator']['index'] + 1
# update payload according to your requirements
response = client.invoke(
FunctionName='LAMBDA_TO_INVOKE',
InvocationType='Event',
Payload=json.dumps({
'bucket_name': 'YOUR_BUCKET_NAME',
'file_key': 'YOUR_FILE_KEY'
})
)
return {
'index': index,
'continue': index < event['iterator']['count'],
'count': event['iterator']['count']
}
Целевая функция выполняет назначение и производит операции чтения-записи или другие модификации в источнике.
Вот простой пример целевой/вызванной функции:
import boto3
s3_client = boto3.client('s3')
def lambda_handler(event, context):
# Extracting necessary information from the event
bucket_name = event['bucket_name']
file_key = event['file_key']
# Get file from S3
s3_response = s3_client.get_object(Bucket=bucket_name, Key=file_key)
file_content = s3_response['Body'].read()
# Perform modification on the file content (example: convert to uppercase)
modified_content = file_content.upper()
# Upload the modified file back to S3
s3_client.put_object(Bucket=bucket_name, Key=file_key, Body=modified_content)
return {
'statusCode': 200,
'body': 'File modified successfully'
}Ниже приведены несколько ценных советов по автоматизации, прежде чем запускать скрипт, убедитесь в том, что эти советы помогут вам добиться лучших результатов:
- Добавьте надлежащее протоколирование для отслеживания измененных и оставшихся записей и общего прогресса.
- Храните свои учетные данные OAuth в менеджере учетных данных или в любом другом безопасном месте.
- Постройте свою программу таким образом, чтобы в случае необходимости повторного запуска она не изменяла ваши данные.
Когда мы используем какой-либо пакет вне среды python, например pandas, мы, вероятно, столкнемся с проблемой, связанной с «package not resolved» или чем-то подобным, поэтому вам придется создать среду python, установить все необходимые зависимости, а затем упаковать их все, чтобы загрузить лямбды.
Благодарю за прочтение! Счастливого кодинга!