10 функций Pandas, которые необходимо знать, чтобы получить начальное представление о любом DataFrame

Pandas - одна из наиболее широко используемых библиотек в сообществе Data Science, и это идеальный инструмент для манипулирования данными, очистки и анализа.
Любой, кто работает с данными, знает библиотеку Pandas.
Каждый раз, когда мы начинаем работать с DataFrame, мы используем несколько основных команд, чтобы получить первое представление о нем. Они могли бы вас заинтересовать.
Вот почему мы опишем 10 функций библиотеки Pandas, чтобы начать играть с нашей совершенно новой таблицей и извлечь из нее некоторые первые идеи.
Присоединяйтесь к нам и давайте откроем их все вместе!
Сначала о главном. Нам всегда нужно загружать наши данные и где-то их хранить. Особенно при работе с нашей местной средой.
#1. read_csv() и to_csv()
Именно здесь большую роль играют как read_csv(), так и to_csv().
read_csv()— это функция в библиотеке panda на Python, которая используется для чтения файла CSV и преобразования его в DataFrame pandas.to_csv()— это функция в библиотеке panda на Python, которая используется для преобразования кадра данных pandas в файл CSV.
Нам просто нужно определить путь к CSV-файлу, который мы хотим прочитать или сохранить.
Итак, давайте загрузим файл, который мы будем использовать на протяжении всей этой статьи. Наш файл называется “Expenses.csv”, и он хранится непосредственно в той же папке, с которой мы работаем. Вот почему мы можем напрямую прочитать его, используя следующий код.
import pandas as pd
ddbb = pd.read_csv("Expenses.csv", delimiter = ";")
ddbbВ этом примере функция read_csv() считывает файл “Expenses.csv” и преобразует его в фрейм данных.
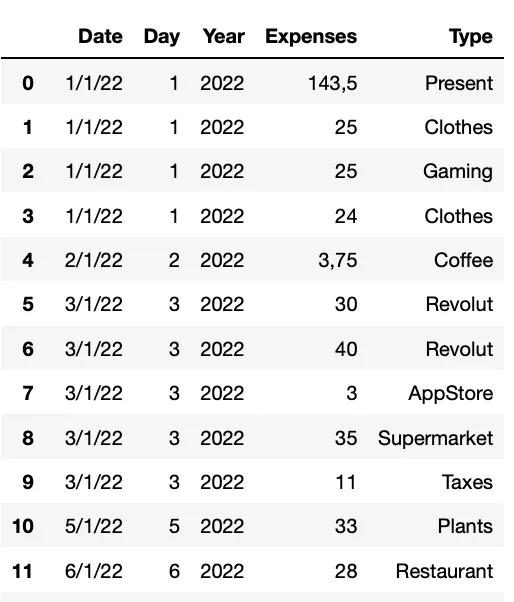
Он имеет несколько опций, таких как delimiter, header, delimiter, index_col, skiprows, na_values . Вы можете проверить это непосредственно в их документации.
ddbb = pd.read_csv("Expenses.csv", delimiter = ";")Если вы хотите сохранить его обратно, процесс будет таким же, применяя функцию to_csv() к нашему DataFrame. В нашем случае мы обычно устанавливаем для параметра index значение False, поэтому первые столбцы индексов, которые pandas автоматически генерируют, опускаются.
ddbb.to_csv("Expenses_new.csv", index = False)Итак, теперь, когда у нас уже есть данные, вам может быть интересно.
МЫ всегда внимательно смотрим на свой DataFrame, чтобы получить первое представление.
#2. Describe()
Метод describe() pandas создает новый DataFrame с полезной статистикой для числовых столбцов в исходном фрейме данных. Это простой способ суммировать множество функций, таких как count, mean, standard deviation и другие.
Очень полезно легко охарактеризовать каждый из его столбцов — например, зная максимальное и минимальное значения для каждого столбца.
Давайте попробуем!
#We apply the describe function on our ddbb dataframe.
ddbb.describe()Поскольку наш исходный фрейм данных содержал три числовых столбца, выходные данные содержат множество показателей для каждого из них.
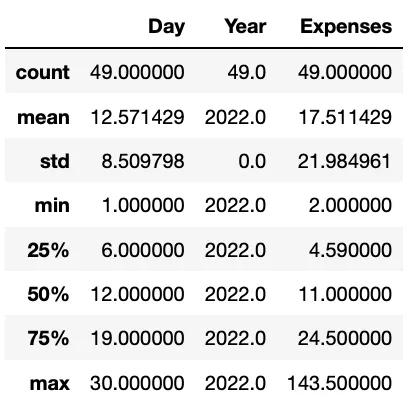
Здесь мы можем легко определить, что у нас есть возможная стоимость только на один год — поскольку наш std установлен в 0 — а расходы варьируются от 2 до 143 евро.
Вы хотите работать и с нечисловыми столбцами? Нет проблем, вы всегда можете включить или исключить определенные столбцы, передав аргументы методу.
#We include all columns
df.describe(include='all')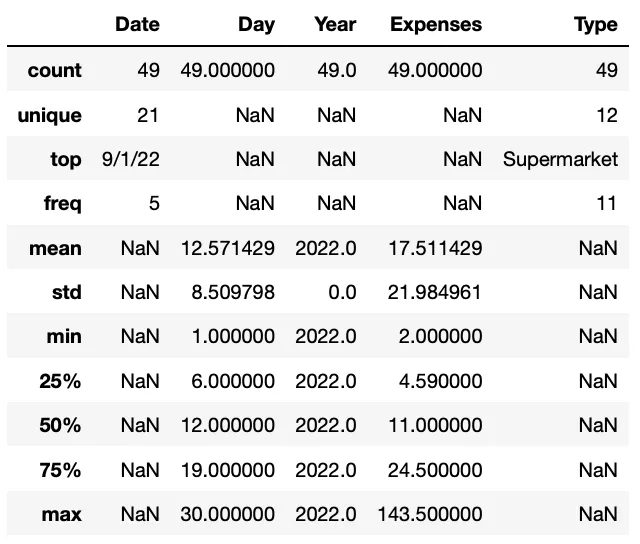
#3. Info()
info() pandas дает краткую сводку DataFrame. Полезно для обнаружения начальных проблем — например, если у нас слишком много ячеек с нулевым значением — понимать типы каждого столбца и использование памяти фреймом данных.
#We get a brief description of our DataFrame
ddbb.info()В нашей таблице все ячейки имеют ненулевые значения. Мы также можем заметить, что и Day, и Year являются целыми числами, в то время как Expenses имеют тип float.
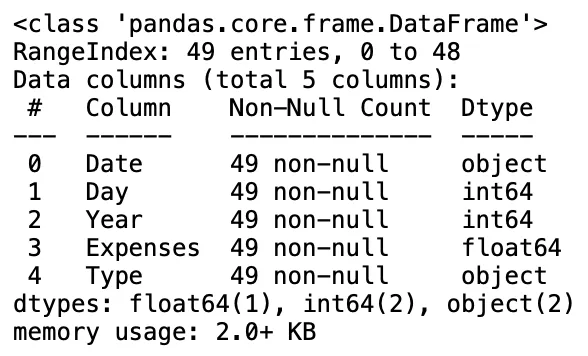
#4. Iloc()
.iloc() Pandas позволяет выбирать строки и столбцы DataFrame по целочисленному индексу. Проще говоря, мы можем использовать его для выбора строк и столбцов по их целочисленному местоположению.

Таким образом, просто указав целое число строки и столбца, которые мы хотим проверить, мы можем легко получить значение — или вложенные DataFrames.
Мы часто используем эту функцию, чтобы сосредоточиться на некоторых частичных частях нашего фрейма данных и разделить нашу таблицу на разные подтаблицы.
Важно всегда помнить, что индексы Python начинаются с 0.
Давайте тоже попробуем.
#We select the value corresponding to the 2nd row and 2nd column.
ddbb.iloc[1,1]
И получаем соответствующее значение.

Вам нужны все значения для данного столбца?
Нет проблем, мы можем легко использовать символ :, который позволяет нам указывать интервал — при наличии начального индекса и конечного индекса — или при наличии всех возможных значений, когда больше ничего не определено. Вы лучше поймете это в следующих примерах.
# Выбор конкретной строки

#We select the 4th row
ddbb.iloc[3,:]В качестве выходных данных мы получаем все возможные значения для 3-й строки.

# Выбор определенного столбца
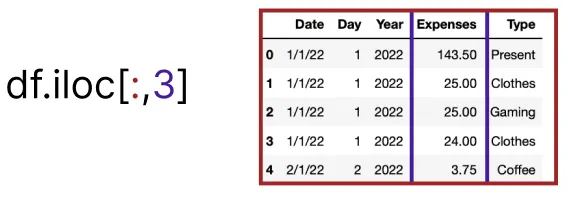
#We select the 3rd column
ddbb.iloc[:,3]В качестве выходных данных мы получаем все возможные значения для столбца “Expenses”.
Вы хотите выбрать более одного столбца или строки? Тогда вы можете просто определить символ : без какой-либо начальной или конечной точки.
# Выбор интервала строк
#We select the 5th to the 7th row
ddbb.iloc[4:7,:]
В качестве выходных данных мы получаем часть нашего исходного фрейма данных — с соответствующим интервалом строк.
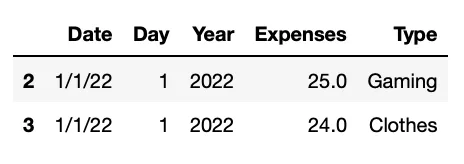
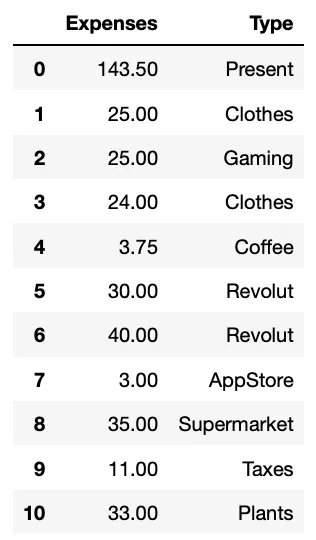
# Выбор интервала столбцов
#We select the 4th to the 6th column
ddbb.iloc[:,3:5]
На выходе получаем 4-й и 5-й столбцы, соответствующие «Expenses» и «Type».
#5. df.loc()
Вы предпочитаете работать с именами каждого столбца? Нет проблем, .loc() поможет вам!
Функция .loc() в Pandas очень похожа на функцию .iloc(). Но в этом случае вместо определения column_numbers мы указываем, какие столбцы нам нужны, по их имени на основе метки.

Вот почему, если мы хотим получить столбцы Expenses, мы можем легко сделать это, указав метку расходов.
# Select the column name 'Gender'
ddbb.loc[:,'Expenses']
Теперь вам, возможно, интересно… как мы можем получить более одного столбца? Нам просто нужно определить список со всеми нашими желаемыми метками столбцов. Как вы можете наблюдать в следующем коде.
# Select the column name 'Gender'
ddbb.loc[:,['Day','Year','Expenses']]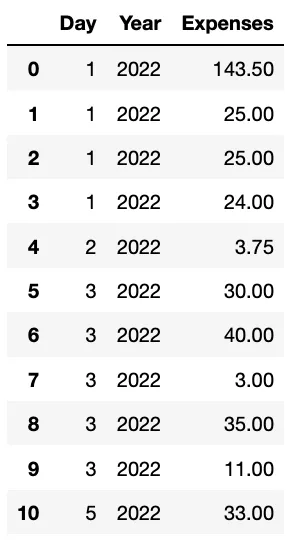
#6. df.assign()
Функция Pandas .assign() вычисляет новые столбцы фрейма данных из других существующих. Мы используем эту функцию довольно часто, когда хотим выполнить некоторые начальные быстрые вычисления.
Представьте, что мы хотим знать, каковы расходы без учета налогов, при условии, что налоги соответствуют 21%. Мы можем легко вычислить этот новый столбец следующим образом.
bbdd_new = bbdd.assign(Expense_without_taxes = bbdd['Expenses']*0.79)
bbdd_new.head()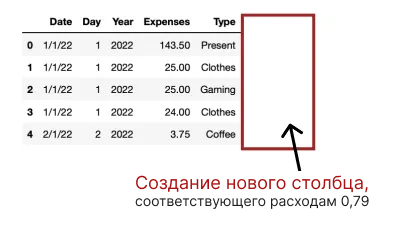
Соответствующий столбец добавляется в наш фрейм данных.
#7. df.query()
Pandas .query() фильтрует DataFrame на основе логического выражения. Он выбирает строки, используя строку запроса, подобную SQL, и возвращает новый DataFrame, содержащий удовлетворяющие строки.
Это действительно полезно при попытке понять наше поведение данных. Например, если мы отфильтруем расходы от 30 до 5 евро, мы обнаружим, что 90% моих расходов находятся в этом диапазоне.
ddbb.query('Expenses < 30 and Expenses > 5')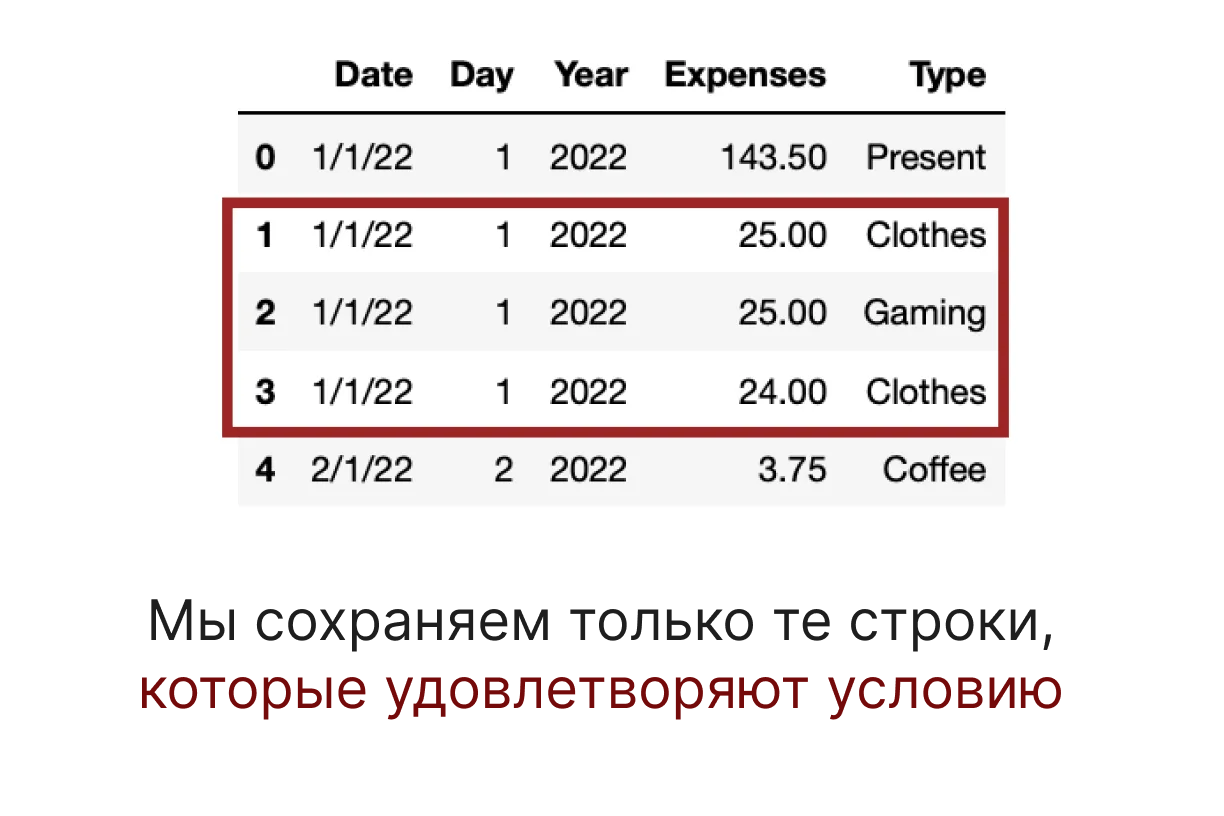
На выходе мы получаем новый DataFrame, выполняющий предыдущее условие.
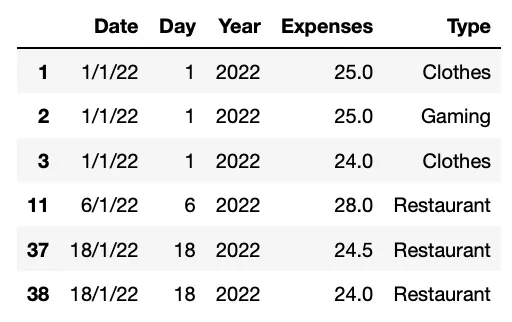
#8. df.sort_values()
Функция Pandas .sort_values() позволяет сортировать DataFrame по одному или нескольким столбцам. Функция возвращает новый DataFrame, отсортированный по указанному столбцу или столбцам.
Данные всегда нужно сортировать, верно? Думаю, магию этой функции объяснять не надо
#Sort the data base by expenses
ddbb.sort_values(by='Expenses', ascending=False)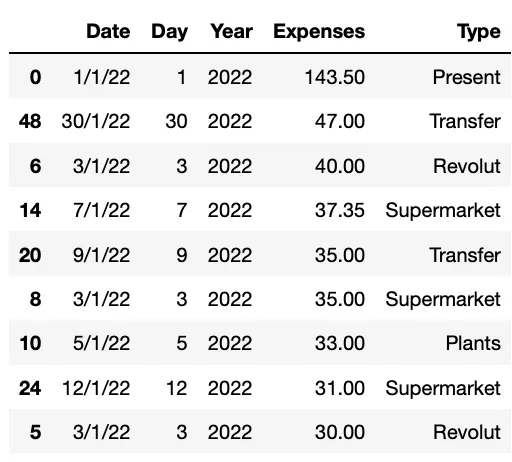
Мы можем сортировать, используя более одного столбца, определяя список меток столбцов, которые мы хотим использовать после by.
#Sort the data base by expenses
ddbb.sort_values(by=['Expenses','Year'], ascending=False)#9. df.isnull()
Метод isnull() в Pandas возвращает фрейм данных той же формы, что и исходный фрейм данных, но со значениями True или False, указывающими, отсутствует ли каждое значение в исходном фрейме данных или нет.
- Отсутствующие значения, такие как
NaNилиNone, будут иметь значениеTrueв результирующем кадре данных. - Не пропущенные значения будут иметь значение
False.
#Sort the data base by expenses
ddbb.isnull()Очень полезно, особенно при использовании вместе с командой info(). Это позволяет нам легко найти наши нулевые значения.
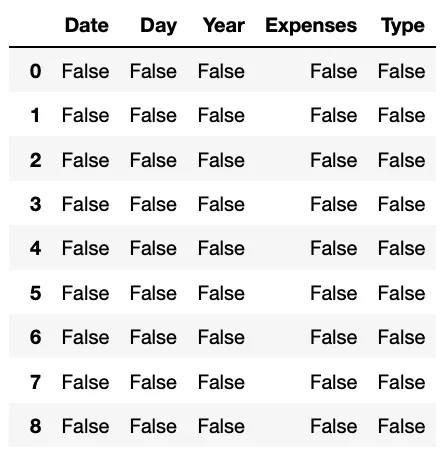
#10. df.groupby()
df.groupby() - это метод в библиотеке Pandas, который используется для группировки строк фрейма данных на основе одного или нескольких столбцов.
Команда .groupby() возвращает объект GroupBy, который затем можно использовать для выполнения агрегатных операций, таких как вычисление mean, sum или count значений в каждой группе.
Давайте посмотрим пример!
#Sort the database by expenses type
ddbb.groupby('Type')И нам возвращается объект GroupBy.

Многим из вас может быть интересно, что вы можете сделать с этим? Ну, мы можем объединить это с некоторой функцией агрегирования.
#We commpute the mean of all numerical columns of our DataFrame grouping by Type.
ddbb.groupby('Type').mean()Как вы можете видеть в следующей таблице, все числовые столбцы, включая день и год, подвергаются среднему вычислению.
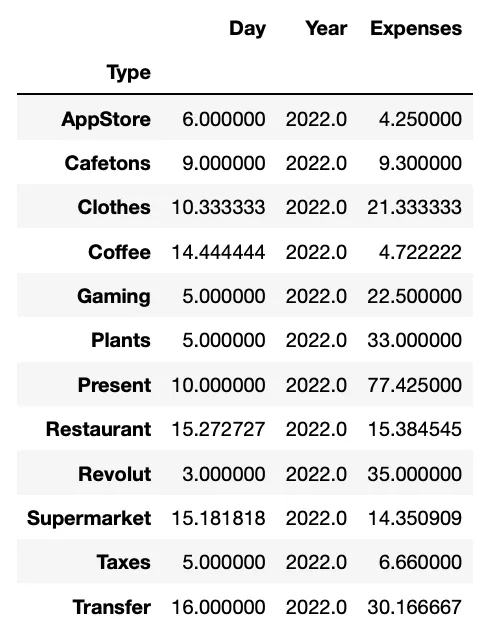
МЫ можем группировать более чем по одному столбцу. Мы повторяем группировку, используя три столбца — «Type», «Day» и «Year».
#Sort the data base by expenses
ddbb.groupby(by=['Type','Day','Year']).mean()В этом втором случае мы получаем среднее значение расхода по Type, Day и Year.
Мы склонны использовать SQL для группировки, by — думаем, что у panda не самый лучший. Однако иногда может быть полезно понять, каковы наши основные поля и как ведут себя числовые данные в соответствии с ними.
И это все на сегодня! Надеюсь, вы нашли эти команды полезными!