9 концепций Python, которые вы не должны пропустить для эффективной обработки данных
9 концепций, которые вы должны изучить для своих интервью по науке о данных
С появлением Интернета бесконечные ресурсы доступны всего одним щелчком мыши, и в результате мы можем получить доступ к любой логике и синтаксисам, которые мы ищем, но это может быть как благословением, так и проклятием. Если не использовать разумно, чрезмерная зависимость от Интернета может замедлить нас. Мы склонны чрезмерно полагаться на Интернет для простой логики и синтаксиса Python, и поэтому мы не тренируем свой мозг запоминать эти концепции. Итак, каждый раз, когда мы используем даже часто используемые синтаксисы, мы привыкаем их гуглить — это нас тормозит, и другие видят в нас дилетантов.
Итак, каково решение?
Вы ищете синтаксис/концепцию в Google первые 2-3 раза, когда вы ее используете, а затем пытаетесь реализовать ее самостоятельно на 4-й раз.
В этом блоге я познакомлю вас с некоторыми из наиболее эффективных концепций науки о данных, которые вам следует изучить, чтобы сэкономить время и стать более продуктивным специалистом по науке о данных. Если вы уже знакомы с этими концепциями, вы можете использовать этот блог, чтобы освежить свое понимание.
1. Однострочные понимания
Однострочный словарь
Итерация по списку/словарю с использованием циклов с многострочными операторами — сложная задача, к счастью, python предоставляет однострочную альтернативу этому — однострочные включения.
Например, мы можем преобразовать следующую итерацию цикла 'for' списка в однострочные включения списка.
numbers = [1, 2, 3, 5, 7, 8, 9, 10]
even_square = []
for num in numbers:
if num%2 == 0:
even_square.append(num*num)Приведенный выше цикл 'for' можно преобразовать в понимание однострочного списка, как показано ниже:
even_square = [n*n for n in numbers if n%2 == 0]Однострочный словарь
Точно так же мы можем преобразовать циклы по словарю в однострочные включения, как показано ниже:
original = {'Key1':'Value1','Key2':'Value2','Key3':'Value3'}
flipped = {}
for key, value in original.items():
flipped[value] = keyПриведенный выше код можно преобразовать в однострочный словарь, как показано ниже:
flipped = {value: key for key, value in original.items()}Lambda-функция
Функция Lambda является альтернативой обычным функциям. Он может быть определен в одной строке кода и, таким образом, занимает меньше времени и места в нашем коде. Например, в приведенном ниже коде мы видим Lambda-функцию в действии.
Обычная функция
def multiply_by_2(x):
x*2Lambda-функция
### lambda arguments: expression
double = lambda x: x*2
print(double(4))
## Output: 43. Карта и фильтр
Функция карты используется для замены (или сопоставления) каждого значения в серии с другим значением. Функция карты применяется только к серии.
import pandas as pd
s = pd.Series(['Math', 'Science', 'Computer'])
s = s.map({'Math': 'Algebra', 'Science':'Physics', 'Computer': 'Python'})
# output
#0 Algebra
#1 Physics
#2 PythonФункцию фильтра можно комбинировать с лямбда-функцией для фильтрации значений последовательности, такой как ряды, списки, кортежи и т. д.
В следующем примере мы фильтруем ряд значений больше 3, используя функцию лямбда и фильтр.
s = pd.Series([1, 2, 3, 4, 5])
result = pd.Series(filter(lambda x: x > 3, s))4. Векторизация по циклам
Циклы в Python дороги (медленны) и не должны использоваться, особенно если вы работаете с большим набором данных, так как это многократно увеличивает время выполнения. Лучше всего преобразовать код в векторизованную форму.
Векторизация — это метод применения операций с массивами к набору данных. В серверной части он применяет операции ко всем элементам массива или ряда за один раз (в отличие от цикла for, который манипулирует одной строкой за раз).
Плохая практика
for index, row in df.iterrows():
df.at[idx,'c'] = (row.a + row.b)/2Good Practice
df['c'] = (df['a'] + df['b'])/25. Concat, Merge and Join
Много раз нам нужно объединить информацию, представленную в разных наборах данных, чтобы выполнить их некоторый анализ. Это очень важная концепция, и ее неправильная реализация может привести к неправильным результатам.
Данные могут быть объединены с использованием следующих концепций:
- Объединение (Concat)
Два или более набора данных могут быть объединены по горизонтали или вертикали с помощью функции concat. Следующий код объединяет наборы данных по вертикали:
import pandas as pd
df3 = pd.concat([df1, df2])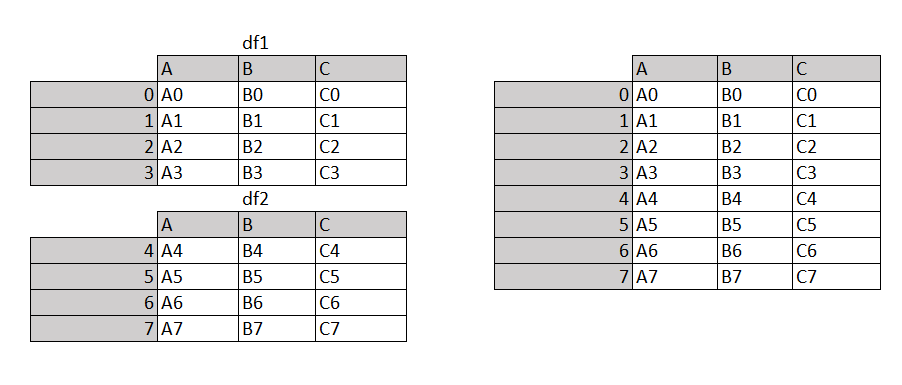
- Слияние (Merge)
Слияние используется для объединения наборов данных по первичным ключам (столбцам с уникальными значениями), которые являются общими при слиянии наборов данных.
На следующем изображении показано слияние левого и правого наборов данных в столбце «A», которое является общим для обоих наборов данных.
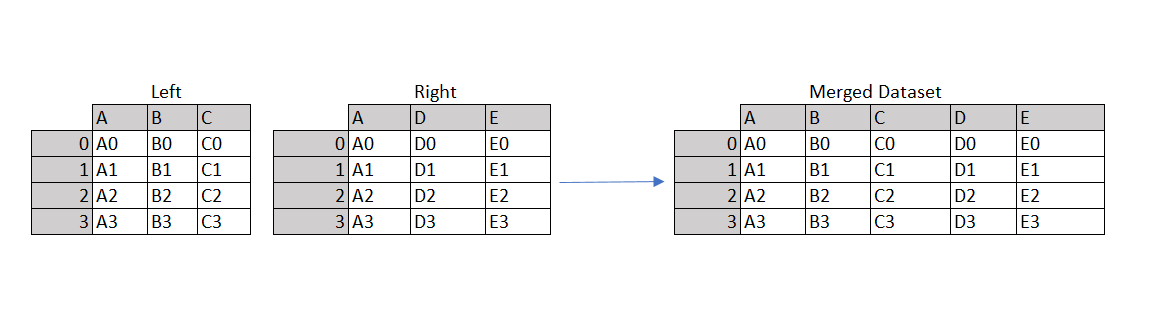
merged = left.merge(right, on = 'A', how = 'inner') - Присоединение (Join)
Соединение используется для объединения 2 или более наборов данных в индексе соединяемых наборов данных.
Например, на следующем изображении показано объединение левого и правого наборов данных в общих индексах объединенных наборов данных.
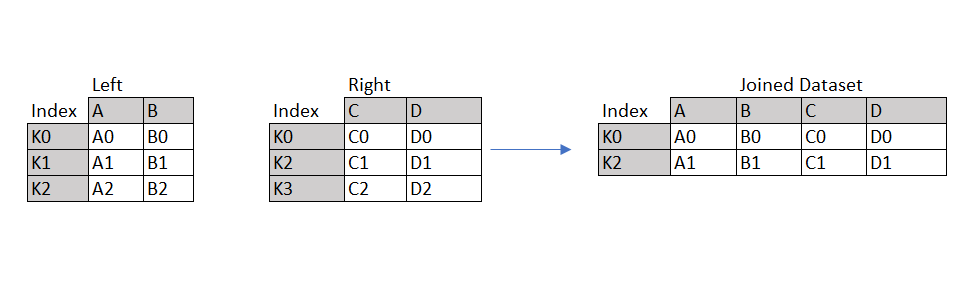
joined = Left.join(Right)6. Подать заявку
Функцию Apply можно использовать для применения операций ко всем элементам фрейма данных или ко всем строкам или столбцам фрейма данных. Он достаточно гибок, чтобы его можно было применять к фрейму данных или ряду.
Синтаксис
DataFrame.apply(func, axis=0)Давайте разберемся с аргументами функции применения на примерах. Мы будем использовать DataFrame с измерениями продуктов.
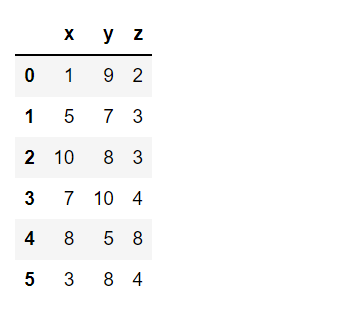
# Using apply on the whole dataframe.
# We can use apply on a column also.
# square of values of the dataframe
measurement_sq = measurement.apply(np.square)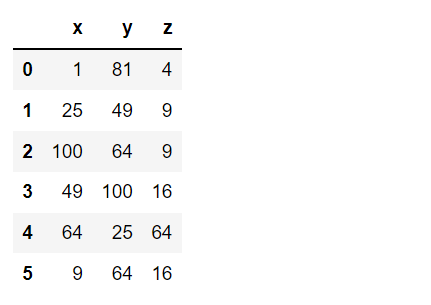
7. Поворот
Сведение — это расширенный метод манипулирования данными, используемый для преобразования уникальных значений в столбце в несколько новых столбцов.
Например, мы можем свести следующие наборы данных, содержащие оценки, выставленные учащимися по разным предметам. Сводной набор данных содержит значения со столбцом темы в виде отдельных новых столбцов.
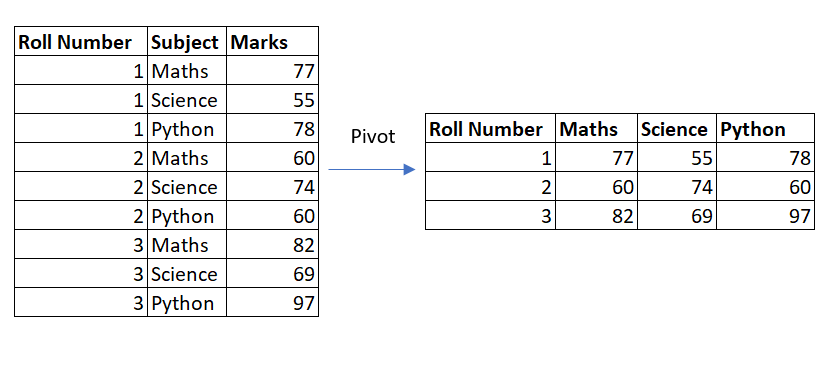
df.pivot(index='Roll Number', columns='Subject', values='Marks')8. Опции осей
Панды дают возможность применять операции к строкам или столбцам DataFrame.
Используя ось = 1, мы можем применять операции к строкам DataFrame, а используя ось = 0, мы можем применять операции к столбцам.
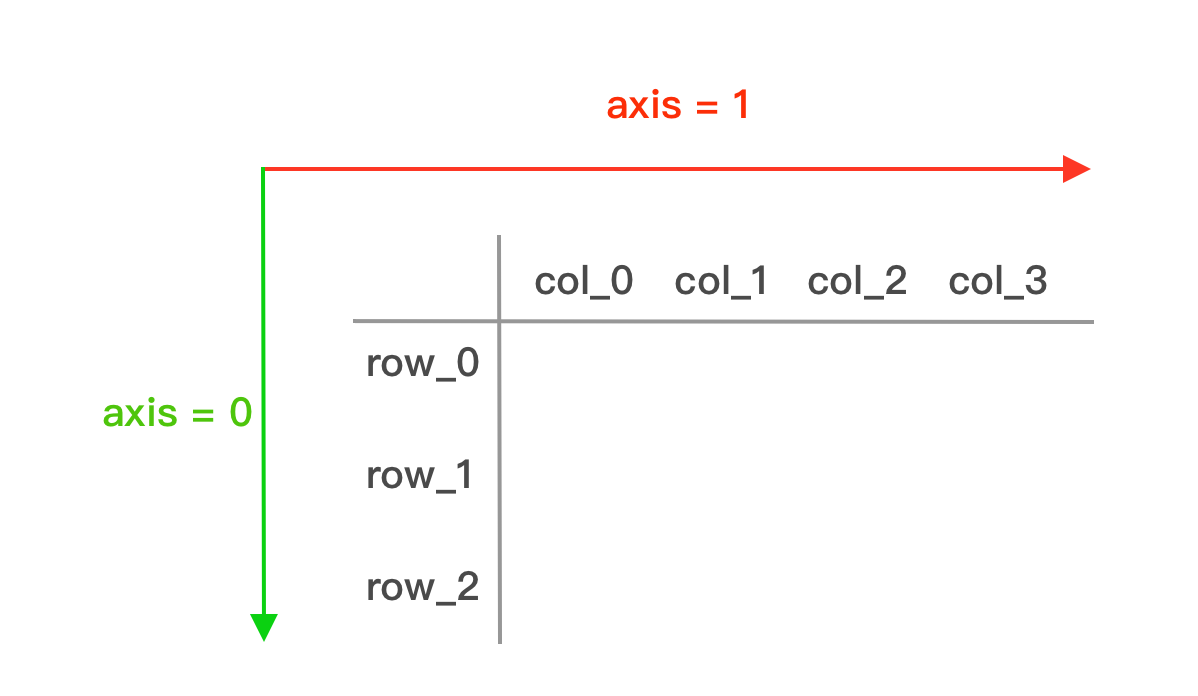
## apply sum across the rows -
df.sum(axis = 1)
## apply sum across the columns
df.sum(axis = 0)9. Агрегация
Поиск числовых сводок, таких как количество, сумма, среднее значение и т. д., в различных группах переменных представляет собой агрегацию данных. Это одна из наиболее часто выполняемых задач Data Scientist.
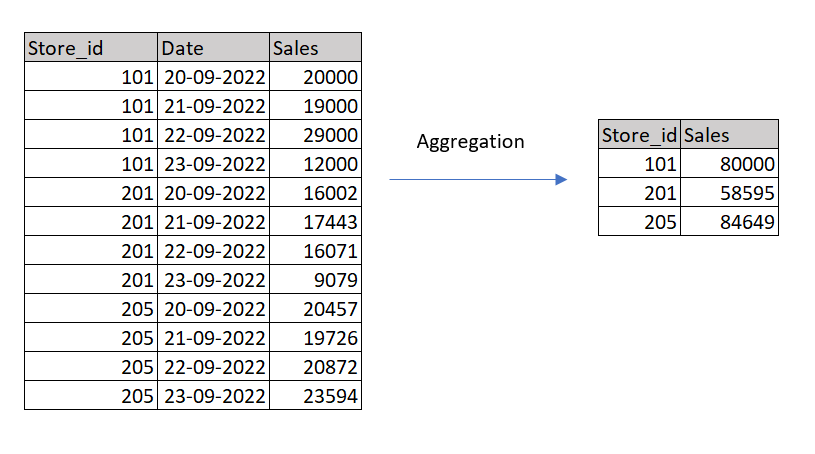
retail_sales.groupby(['Store_id']).agg({'Sales':'sum'}).reset_index()Вывод
В этом блоге мы рассмотрели некоторые из наиболее полезных концепций, которые вам следует изучить, если вы работаете с данными. Важно изучить эти концепции, чтобы вам не приходилось каждый раз обращаться к Google и не приходилось тратить лишнее время на реализацию этих концепций и их уверенное применение.