7 лучших библиотек веб-скрейпинга Python

Есть пословица «Не нужно изобретать велосипед». Библиотеки - лучший пример этого. Это поможет вам легко писать сложные и отнимающие много времени функциональные возможности. В хорошем проекте разработчики используют одни из лучших доступных библиотек
Известный Python не нуждается в каком-либо представлении. Это один из наиболее часто используемых языков программирования практически для любых целей. Здесь собраны 7 полезных библиотек Python для Web Scraping, которые помогут вам в вашем путешествии по разработке.
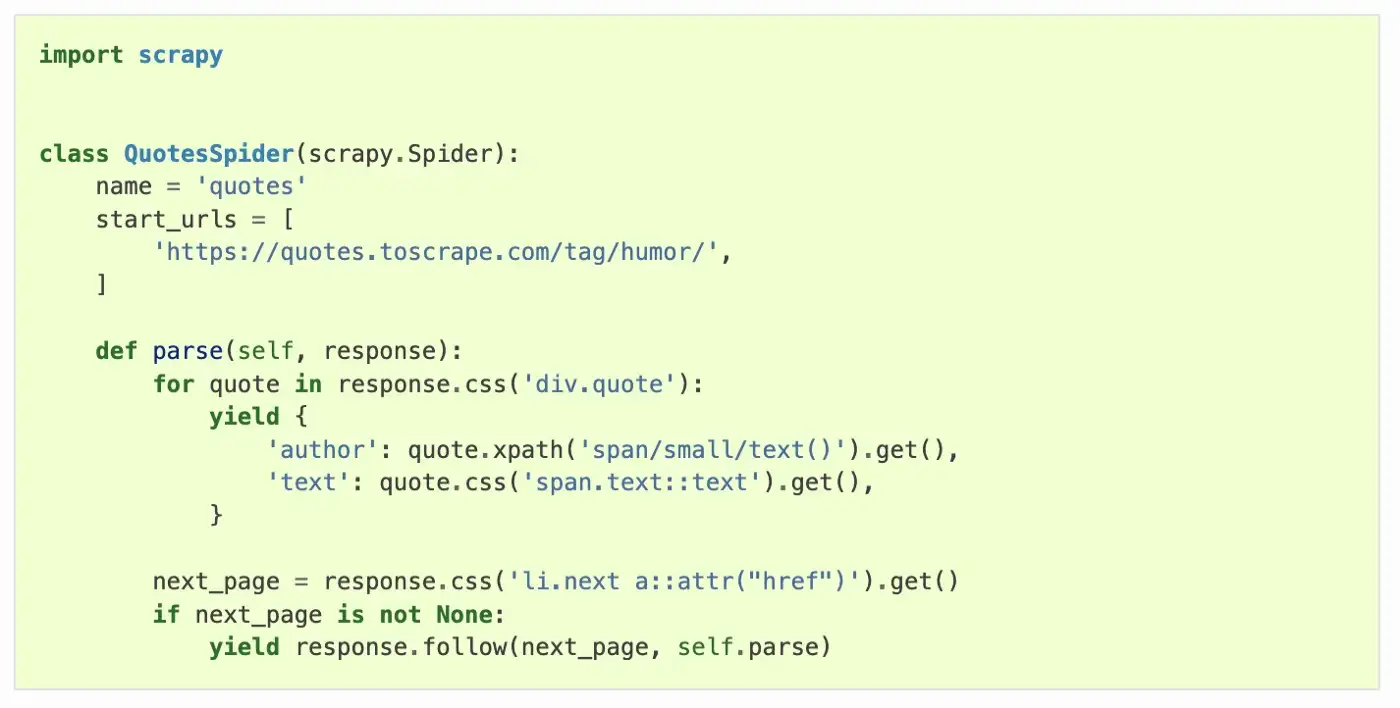
Scrapy

Это быстрая высокоуровневая библиотека веб-сканирования и очистки веб-страниц, используемая для обхода веб-сайтов и извлечения структурированных данных с их страниц. Его можно использовать для широкого спектра целей, от интеллектуального анализа данных до мониторинга и автоматизированного тестирования.
MechanicalSoup

Эта библиотека поможет вам автоматизировать взаимодействие с веб-сайтами. Он автоматически сохраняет и отправляет файлы cookie, выполняет перенаправления, а также может переходить по ссылкам и отправлять формы. Он не использует JavaScript.
Auto scraper

Эта библиотека предназначена для автоматической очистки веб-страниц, чтобы упростить очистку. Он получает URL-адрес или HTML-содержимое веб-страницы и список образцов данных, которые мы хотим извлечь с этой страницы. Эти данные могут быть текстом, URL-адресом или любым значением HTML-тега этой страницы. Он изучает правила очистки и возвращает похожие элементы. Затем вы можете использовать этот изученный объект с новыми URL-адресами, чтобы получить похожий контент или точно такой же элемент этих новых страниц.
Pyspider
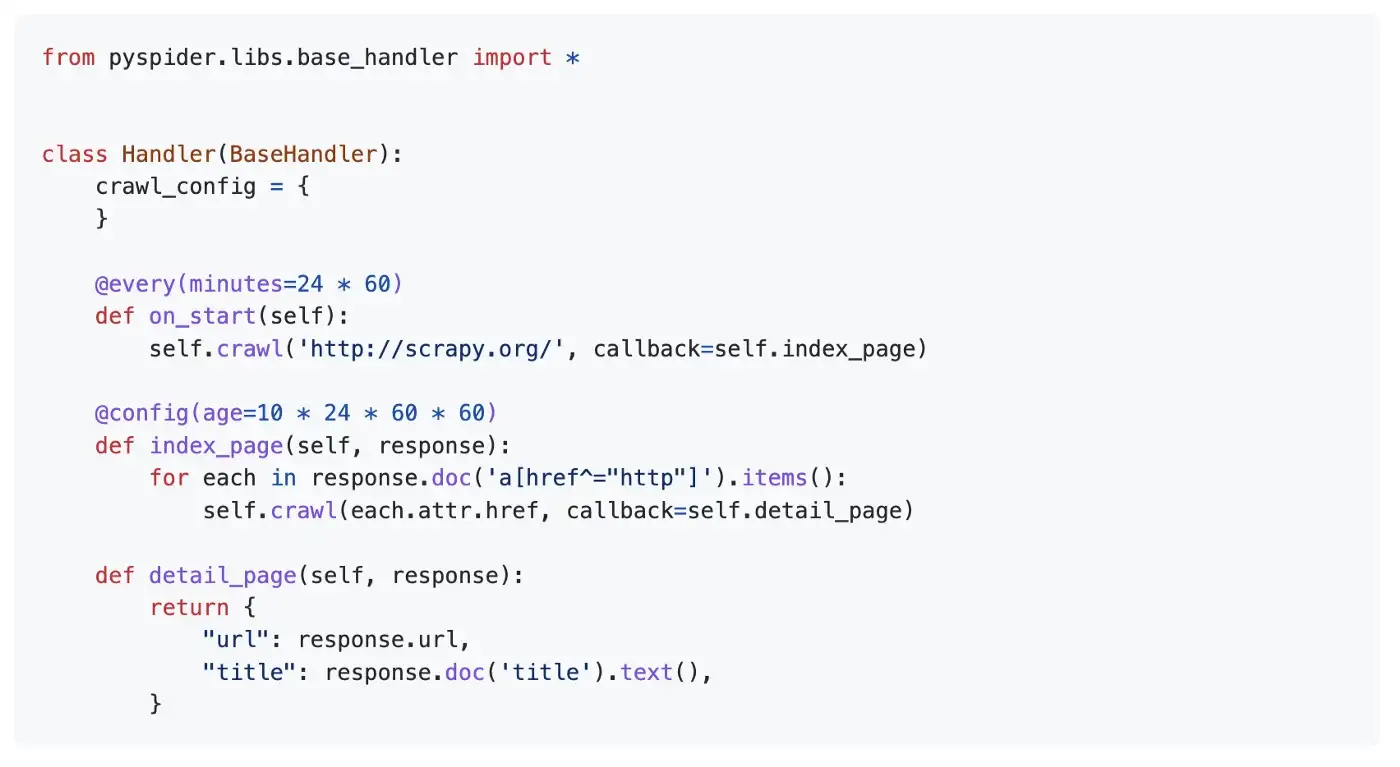
Как следует из названия, эта библиотека предоставляет мощную систему Spider (Web Crawler). Он включает в себя такие функции, как мощный WebUI с редактором сценариев, монитор задач, менеджер проектов и средство просмотра результатов, MySQL, MongoDB, Redis, SQLite, Elasticsearch; PostgreSQL c SQLAlchemy в качестве бэкэнда базы данных, приоритет задачи, повторная попытка, периодичность, повторный поиск по возрасту и т.д.
Pattern
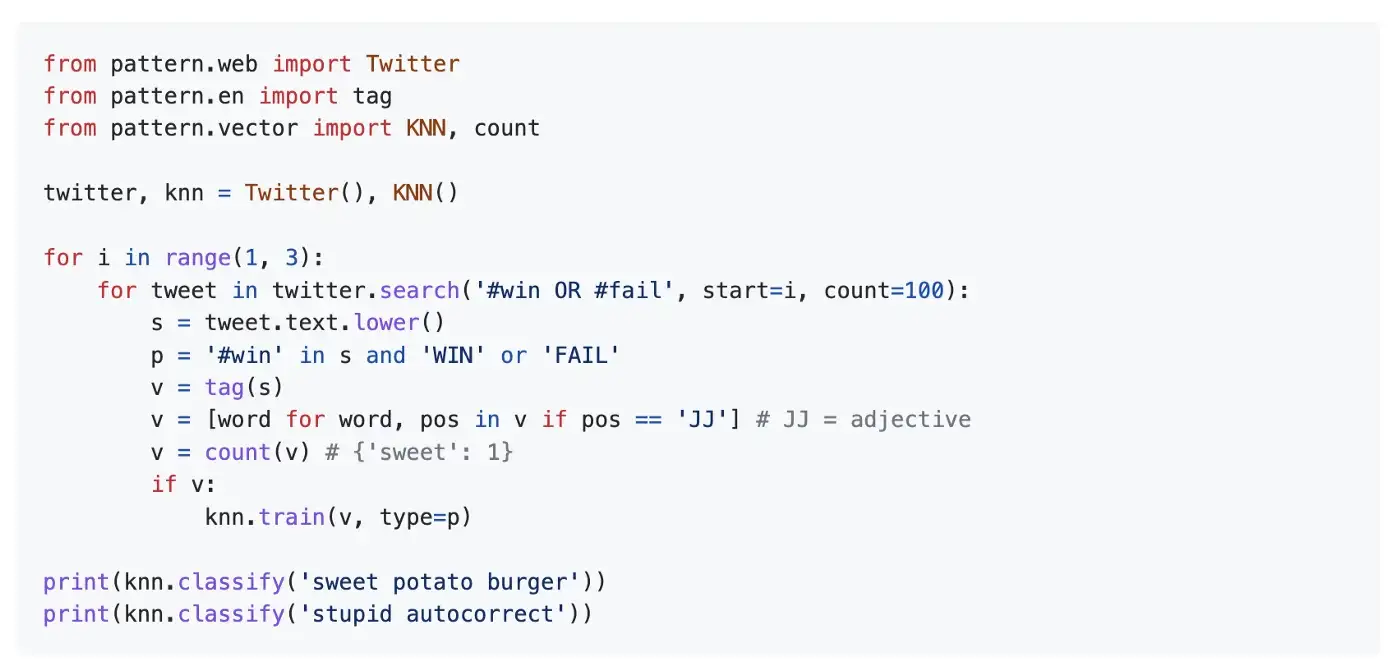
Эта библиотека предоставляет модуль веб-анализа данных. В нем есть инструменты для интеллектуального анализа данных (API Google, Twitter и Wikipedia, веб-сканер, анализатор HTML DOM), обработки естественного языка (теги частей речи, поиск по n-граммам, анализ настроений, WordNet), машинного обучения (модель векторного пространства, кластеризация, SVM), сетевого анализа и визуализация <canvas>.
FeedParser

Это библиотека для загрузки и анализа синдицированных каналов. Он может обрабатывать каналы RSS 0.90, Netscape RSS 0.91, Userland RSS 0.91, RSS 0.92, RSS 0.93, RSS 0.94, RSS 1.0, RSS 2.0, Atom 0.3, Atom 1.0 и CDF. Он также анализирует несколько популярных модулей расширений, включая Dublin Core и расширения iTunes от Apple.
Ruia

Эта библиотека асинхронного веб-сканирования, написанная с использованием asyncio и aiohttp, цель которой - сделать URL-адрес для обхода максимально удобным. Он включает в себя такие функции, как декларативное программирование, поддержка JavaScript и т.д.
Если вы заинтересованы в парсере с открытым исходным кодом, вам может подойти любой из вышеупомянутых инструментов. Тем не менее, убедитесь, что у вас достаточно опыта для написания кода на соответствующем языке для парсера.