4 лучших предварительно подготовленных модели для классификации изображений с помощью кода Python
Человеческий мозг может легко распознавать и различать объекты на изображении. Например, имея изображение кошки и собаки, за наносекунды мы различаем их, и наш мозг воспринимает это различие. Если машина имитирует это поведение, она максимально приближена к искусственному интеллекту. Впоследствии область компьютерного зрения направлена на имитацию системы зрения человека - и было много вех, которые преодолели барьеры в этом отношении.Более того, в наши дни машины могут легко различать разные изображения, обнаруживать предметы и лица и даже генерировать изображения людей, которых не существует! Очаровательно, не правда ли? Одним из моих первых опытов, когда я начинал работать с компьютерным зрением, была задача классификации изображений. Сама способность машины различать объекты ведет к большему количеству направлений исследований, например, к различению людей.

Быстрое развитие компьютерного зрения и, соответственно, классификации изображений ускорилось с появлением трансферного обучения. Проще говоря, трансферное обучение позволяет нам использовать уже существующую модель, обученную на огромном наборе данных, для наших собственных задач. Следовательно, снижается стоимость обучения новых моделей глубокого обучения, а поскольку наборы данных проверены, мы можем быть уверены в качестве.
В классификации изображений есть несколько очень популярных наборов данных, которые используются в исследованиях, в промышленности и на хакатонах. Вот некоторые из наиболее известных:
и многое другое.
В этой статье я расскажу о 4 лучших предварительно обученных моделях для классификации изображений, которые являются современными (SOTA) и также широко используются в отрасли. Отдельные модели можно объяснить гораздо более подробно, но я ограничил статью, чтобы дать обзор их архитектуры и реализовать ее в наборе данных.
Настройка системы
Поскольку мы начали с кошек и собак, давайте рассмотрим набор данных изображений кошек и собак. Исходный набор обучающих данных на Kaggle содержит 25000 изображений кошек и собак, а тестовый набор данных - 10000 немаркированных изображений. Поскольку наша цель - только понять эти модели, я взял гораздо меньший набор данных. Вы можете напрямую запустить этот и остальной код в Google Colab - так что давайте приступим!
!wget --no-check-certificate \
https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip \
-O /tmp/cats_and_dogs_filtered.zip
Давайте также импортируем базовые библиотеки. Далее я расскажу о будущем импорте в зависимости от модели:
import os
import zipfile
import tensorflow as tf
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras import layers
from tensorflow.keras import Model
import matplotlib.pyplot as plt
Подготовка набора данных
Сначала мы подготовим набор данных и разделим изображения:
- Сначала мы разделяем содержимое папки на каталоги train и validation.
- Затем в каждом каталоге создайте отдельный каталог для кошек, содержащий только изображения кошек, и отдельный каталог для собак, содержащий только изображения собак.
local_zip = '/tmp/cats_and_dogs_filtered.zip'
zip_ref = zipfile.ZipFile(local_zip, 'r')
zip_ref.extractall('/tmp')
zip_ref.close()
base_dir = '/tmp/cats_and_dogs_filtered'
train_dir = os.path.join(base_dir, 'train')
validation_dir = os.path.join(base_dir, 'validation')
# Directory with our training cat pictures
train_cats_dir = os.path.join(train_dir, 'cats')
# Directory with our training dog pictures
train_dogs_dir = os.path.join(train_dir, 'dogs')
# Directory with our validation cat pictures
validation_cats_dir = os.path.join(validation_dir, 'cats')
# Directory with our validation dog pictures
validation_dogs_dir = os.path.join(validation_dir, 'dogs')
Следующий код позволит нам проверить, правильно ли загружены изображения:
# Set up matplotlib fig, and size it to fit 4x4 pics
import matplotlib.image as mpimg
nrows = 4
ncols = 4
fig = plt.gcf()
fig.set_size_inches(ncols*4, nrows*4)
pic_index = 100
train_cat_fnames = os.listdir( train_cats_dir )
train_dog_fnames = os.listdir( train_dogs_dir )
next_cat_pix = [os.path.join(train_cats_dir, fname)
for fname in train_cat_fnames[ pic_index-8:pic_index]
]
next_dog_pix = [os.path.join(train_dogs_dir, fname)
for fname in train_dog_fnames[ pic_index-8:pic_index]
]
for i, img_path in enumerate(next_cat_pix+next_dog_pix):
# Set up subplot; subplot indices start at 1
sp = plt.subplot(nrows, ncols, i + 1)
sp.axis('Off') # Don't show axes (or gridlines)
img = mpimg.imread(img_path)
plt.imshow(img)
plt.show()
Теперь, когда у нас есть готовый набор данных, давайте перейдем к этапу построения модели. В этом наборе данных мы будем использовать 4 разные предварительно обученные модели.
Предварительно обученные модели для классификации изображений
В этом разделе мы рассмотрим 4 предварительно обученных модели для классификации изображений следующим образом:
1. Очень глубокие сверточные сети для распознавания крупномасштабных изображений (VGG-16)
VGG-16 - одна из самых популярных предварительно обученных моделей для классификации изображений. Представленная на знаменитой конференции ILSVRC 2014, она была и остается ЛУЧШЕЙ моделью даже сегодня. Разработанный группой Visual Graphics Group Оксфордского университета, VGG-16 превзошел тогдашний стандарт AlexNet и был быстро принят исследователями и отраслью для решения задач классификации изображений.
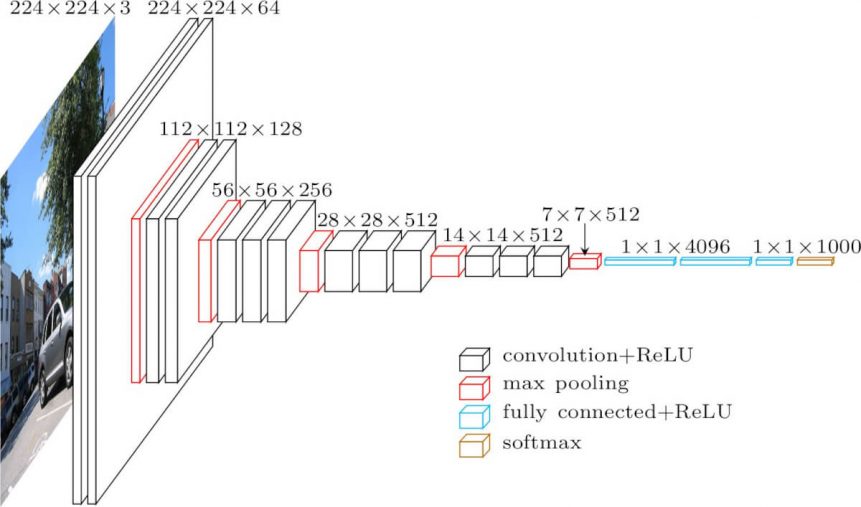
Вот архитектура VGG-16:
Вот более интуитивно понятная компоновка модели VGG-16.
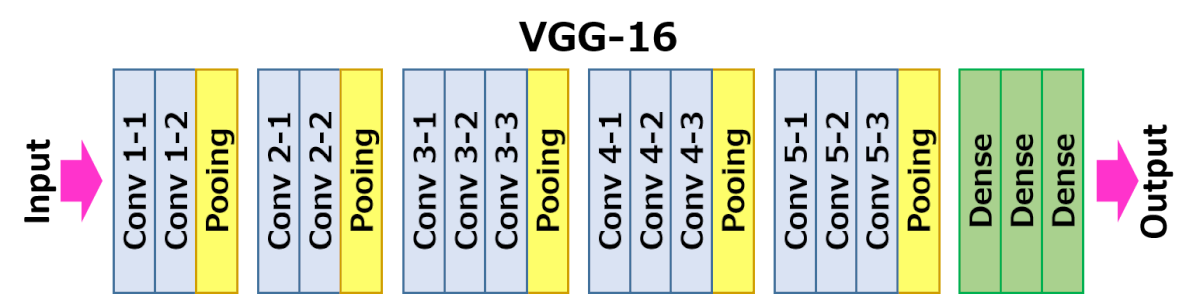
Следующие слои модели:
- Сверточные слои = 13
- Слои объединения = 5
- Плотные слои = 3
Давайте подробно рассмотрим слои:
- Вход: изображение размеров (224, 224, 3).
- Convolution Layer Conv1:Conv1-1: 64 фильтраConv1-2: 64 фильтра и максимальное объединениеРазмеры изображения: (224, 224)
- Conv1-1: 64 фильтра
- Conv1-2: 64 фильтра и максимальное объединение
- Размеры изображения: (224, 224)
- Слой свертки Conv2: теперь мы увеличиваем фильтры до 128Размеры входного изображения: (112 112)Conv2-1: 128 фильтровConv2-2: 128 фильтров и максимальное объединение
- Размеры входного изображения: (112 112)
- Conv2-1: 128 фильтров
- Conv2-2: 128 фильтров и максимальное объединение
- Convolution Layer Conv3: снова удвойте фильтры до 256, а теперь добавьте еще один слой свертки.Размеры входного изображения: (56,56)Conv3-1: 256 фильтровConv3-2: 256 фильтровУсловие 3-3: 256 фильтров и максимальное объединение
- Размеры входного изображения: (56,56)
- Conv3-1: 256 фильтров
- Conv3-2: 256 фильтров
- Условие 3-3: 256 фильтров и максимальное объединение
- Convolution Layer Conv4: аналогично Conv3, но теперь с 512 фильтрами.Размеры входного изображения: (28, 28)Conv4-1: 512 фильтровConv4-2: 512 фильтровConv4-3: 512 фильтров и максимальное объединение
- Размеры входного изображения: (28, 28)
- Conv4-1: 512 фильтров
- Conv4-2: 512 фильтров
- Conv4-3: 512 фильтров и максимальное объединение
- Convolution Layer Conv5: то же, что Conv4Размеры входного изображения: (14, 14)Conv5-1: 512 фильтровConv5-2: 512 фильтровConv5-3: 512 фильтров и максимальное объединениеВыходные размеры здесь (7, 7). На этом этапе мы сглаживаем выходные данные этого слоя, чтобы создать вектор признаков.
- Размеры входного изображения: (14, 14)
- Conv5-1: 512 фильтров
- Conv5-2: 512 фильтров
- Conv5-3: 512 фильтров и максимальное объединение
- Выходные размеры здесь (7, 7). На этом этапе мы сглаживаем выходные данные этого слоя, чтобы создать вектор признаков.
- Полностью подключенный / плотный FC1 : 4096 узлов, генерирующих вектор признаков размера (1, 4096)
- Fully ConnectedDense FC2: 4096 узлов, генерирующих вектор признаков размера (1, 4096)
- Полностью подключенный / плотный FC3: 4096 узлов, генерирующих 1000 каналов для 1000 классов. Затем он передается в функцию активации Softmax.
- Выходной слой
Как видите, модель носит последовательный характер и использует множество фильтров. На каждом этапе используются маленькие фильтры 3 * 3 для уменьшения количества параметров, все скрытые слои используют функцию активации ReLU. Даже в этом случае количество параметров составляет 138 миллиардов, что делает эту модель более медленной и гораздо более крупной для обучения, чем другие.
Кроме того, существуют вариации модели VGG16, которые, по сути, являются ее усовершенствованием, например, VGG19 (19 слоев). Вы можете найти подробное объяснение
Давайте теперь рассмотрим, как обучить модель VGG-16 на нашем наборе данных.
Шаг 1. Увеличение изображения
Поскольку раньше мы использовали гораздо меньший набор данных изображений, мы можем компенсировать это, дополнив эти данные и увеличив размер нашего набора данных. Если вы работаете с исходным более крупным набором данных, вы можете пропустить этот шаг и сразу перейти к построению модели.
# Add our data-augmentation parameters to ImageDataGenerator
train_datagen = ImageDataGenerator(rescale = 1./255.,rotation_range = 40, width_shift_range = 0.2, height_shift_range = 0.2, shear_range = 0.2, zoom_range = 0.2, horizontal_flip = True)
# Note that the validation data should not be augmented!
test_datagen = ImageDataGenerator( rescale = 1.0/255. )Шаг 2: наборы для обучения и проверки
# Flow training images in batches of 20 using train_datagen generator
train_generator = train_datagen.flow_from_directory(train_dir, batch_size = 20, class_mode = 'binary', target_size = (224, 224))
# Flow validation images in batches of 20 using test_datagen generator
validation_generator = test_datagen.flow_from_directory( validation_dir, batch_size = 20, class_mode = 'binary', target_size = (224, 224))
Шаг 3: Загрузка базовой модели
Мы будем использовать только базовые модели, с изменениями, внесенными только в последний слой. Это связано с тем, что это всего лишь проблема двоичной классификации, в то время как эти модели рассчитаны на обработку до 1000 классов.
from tensorflow.keras.applications.vgg16 import VGG16
base_model = VGG16(input_shape = (224, 224, 3), # Shape of our images
include_top = False, # Leave out the last fully connected layer
weights = 'imagenet')
Поскольку нам не нужно обучать все слои, мы делаем их non_trainable:
for layer in base_model.layers:
layer.trainable = False
Шаг 4: скомпилировать и подогнать
Затем мы построим последний полностью связанный слой. Я только что использовал базовые настройки, но не стесняйтесь экспериментировать с разными значениями отсева, а также с различными оптимизаторами и функциями активации.
# Flatten the output layer to 1 dimension
x = layers.Flatten()(base_model.output)
# Add a fully connected layer with 512 hidden units and ReLU activation
x = layers.Dense(512, activation='relu')(x)
# Add a dropout rate of 0.5
x = layers.Dropout(0.5)(x)
# Add a final sigmoid layer for classification
x = layers.Dense(1, activation='sigmoid')(x)
model = tf.keras.models.Model(base_model.input, x)
model.compile(optimizer = tf.keras.optimizers.RMSprop(lr=0.0001), loss = 'binary_crossentropy',metrics = ['acc'])
Теперь мы построим окончательную модель на основе ранее созданных наборов для обучения и проверки. Обратите внимание, что нужно использовать исходные каталоги вместо расширенных наборов данных, которые я использовал ниже. Я использовал всего 10 epoch, но вы также можете увеличить их, чтобы получить лучшие результаты:
vgghist = model.fit(train_generator, validation_data = validation_generator, steps_per_epoch = 100, epochs = 10)
Потрясающие! Как видите, мы смогли достичь точности проверки 93% всего за 10 epoch и без каких-либо серьезных изменений модели. Здесь мы понимаем, насколько мощным является трансферное обучение и насколько полезными могут быть предварительно обученные модели для классификации изображений. Однако здесь есть предостережение - VGG16 требует много времени для обучения по сравнению с другими моделями, и это может быть недостатком, когда мы имеем дело с огромными наборами данных.
При этом мне очень понравилось, насколько проста и интуитивно понятна эта модель. Обученная в корпусе ImageNet, еще одним заметным достижением VGG-16 является то, что она заняла 1-е место в ImageNet ILSVRC-2014 и, таким образом, закрепила свое место в списке лучших предварительно обученных моделей для классификации изображений.
2. Начало
Во время исследования для этой статьи было ясно одно. 2014 год стал знаковым с точки зрения разработки действительно популярных предварительно обученных моделей для классификации изображений. В то время как вышеупомянутый VGG-16 обеспечил 2-е место в ILSVRC того года, 1-е место было обеспечено не кем иным, как Google - через его модель GoogLeNet или Inception, как ее теперь называют.
В исходной статье предлагается модель Inceptionv1. Имея всего 7 миллионов параметров, он был намного меньше, чем у распространенных тогда моделей, таких как VGG и AlexNet. Прибавив к этому меньшую частоту ошибок, вы поймете, почему это была прорывная модель. Не только это, но и главное нововведение в этой статье - это еще один прорыв - начальный модуль.
Простыми словами, начальный модуль просто выполняет свертки с разными размерами фильтров на входе, выполняет максимальное объединение и объединяет результат для следующего начального модуля. Введение операции свертки 1 * 1 резко снижает параметры.
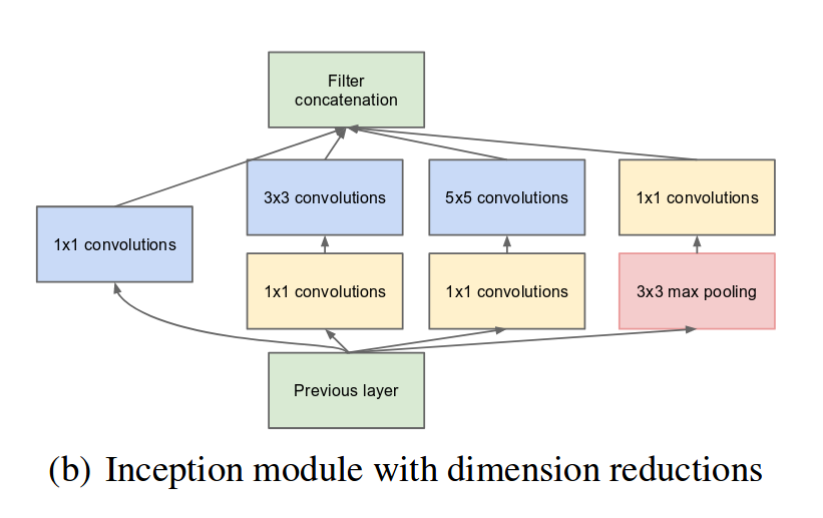
Хотя количество слоев в Inceptionv1 составляет 22, значительное сокращение параметров делает его отличной моделью.
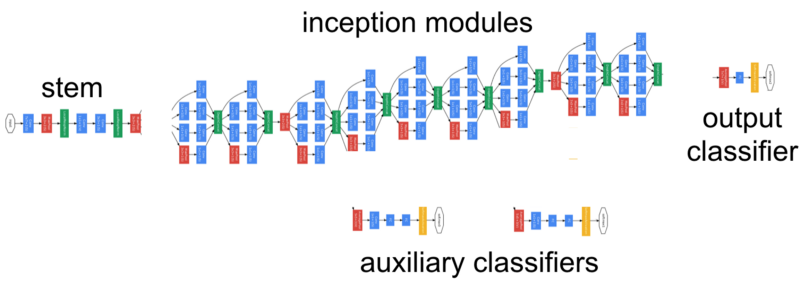
Модель Inceptionv2 была значительным улучшением модели Inceptionv1, которое повысило точность и еще больше сделало модель менее сложной. В той же статье, что и Inceptionv2, авторы представили модель Inceptionv3 с еще несколькими улучшениями в v2.
Ниже перечислены основные улучшения:
- Введение в пакетную нормализацию
- Больше факторизации
- Оптимизатор RMSProp
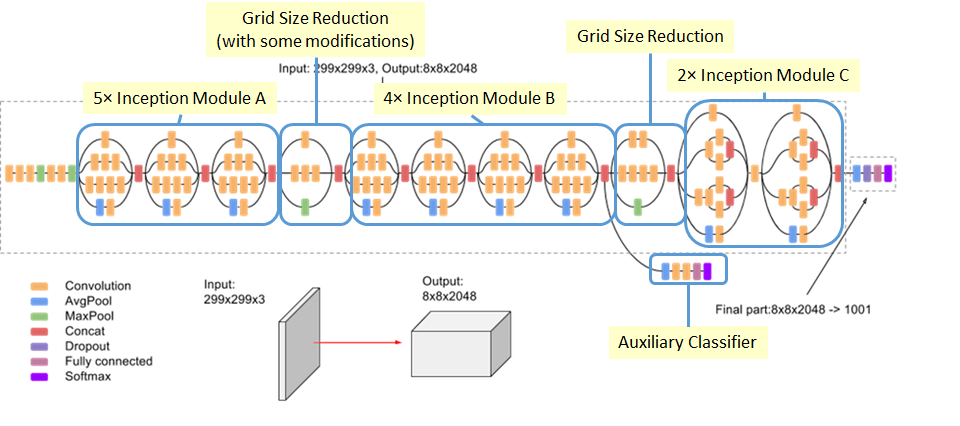
Как видите, количество слоев 42, по сравнению с ничтожными 16 слоями VGG16. Кроме того, Inceptionv3 снизил частоту ошибок до 4,2%.
Посмотрим, как это реализовать на python
Шаг 1. Увеличение данных
Вы заметите, что я не выполняю обширное увеличение данных. Код такой же, как и раньше. Я только что изменил размеры изображения для каждой модели.
# Add our data-augmentation parameters to ImageDataGenerator
train_datagen = ImageDataGenerator(rescale = 1./255., rotation_range = 40, width_shift_range = 0.2, height_shift_range = 0.2,shear_range = 0.2, zoom_range = 0.2, horizontal_flip = True)
test_datagen = ImageDataGenerator( rescale = 1.0/255. )
Шаг 2. Генераторы обучения и проверки
train_generator = train_datagen.flow_from_directory(train_dir, batch_size = 20, class_mode = 'binary', target_size = (150, 150))
validation_generator = test_datagen.flow_from_directory(validation_dir, batch_size = 20, class_mode = 'binary', target_size = (150, 150))
Шаг 3: Загрузка базовой модели
from tensorflow.keras.applications.inception_v3 import InceptionV3
base_model = InceptionV3(input_shape = (150, 150, 3), include_top = False, weights = 'imagenet')
Шаг 4: скомпилировать и подогнать
Как и в случае с VGG-16, мы изменим только последний слой.
for layer in base_model.layers:
layer.trainable = False
Выполняем следующие операции:
- Сведите вывод нашей базовой модели к одному измерению
- Добавьте полностью связанный слой с 1024 скрытыми блоками и активацией ReLU
- На этот раз мы выберем показатель отсева 0,2.
- Добавьте последний полностью связанный сигмовидный слой
- Мы снова будем использовать RMSProp, хотя вы также можете попробовать Adam Optimiser
from tensorflow.keras.optimizers import RMSprop
x = layers.Flatten()(base_model.output)
x = layers.Dense(1024, activation='relu')(x)
x = layers.Dropout(0.2)(x)
x = layers.Dense(1, activation='sigmoid')(x)
model = tf.keras.models.Model(base_model.input, x)
model.compile(optimizer = RMSprop(lr=0.0001), loss = 'binary_crossentropy', metrics = ['acc'])
Затем мы подгоним модель:
inc_history = model.fit_generator(train_generator, validation_data = validation_generator, steps_per_epoch = 100, epochs = 10)

В результате мы видим, что мы получаем точность валидации 96% за 10 epoch. Также обратите внимание, насколько эта модель намного быстрее, чем VGG16. Каждая эпоха занимает примерно 1/4 времени, чем в VGG16. Конечно, вы всегда можете поэкспериментировать с различными значениями гиперпараметров и посмотреть, насколько лучше / хуже он работает.
Мне очень понравилось изучение модели Inception. В то время как большинство моделей в то время были просто последовательными и следовали принципу: чем глубже и крупнее модель, тем лучше она будет работать - Inception и его варианты сломали этот шаблон. Как и его предшественники, Inceptionv3 занял первое место в CVPR 2016 с коэффициентом ошибок всего 3,5% из первой пятерки.
3. ResNet50
Как и Inceptionv3, ResNet50 - не первая модель из семейства ResNet. Первоначальная модель называлась Residual net или ResNet и была еще одной вехой в области CV еще в 2015 году.
Основная мотивация этой модели заключалась в том, чтобы избежать низкой точности по мере того, как модель становилась глубже. Кроме того, если вы знакомы с градиентным спуском, вы могли бы столкнуться с проблемой исчезающего градиента - модель ResNet также была направлена на решение этой проблемы. Вот архитектура самого раннего варианта: ResNet34 (ResNet50 также следует аналогичной методике, только с большим количеством слоев)
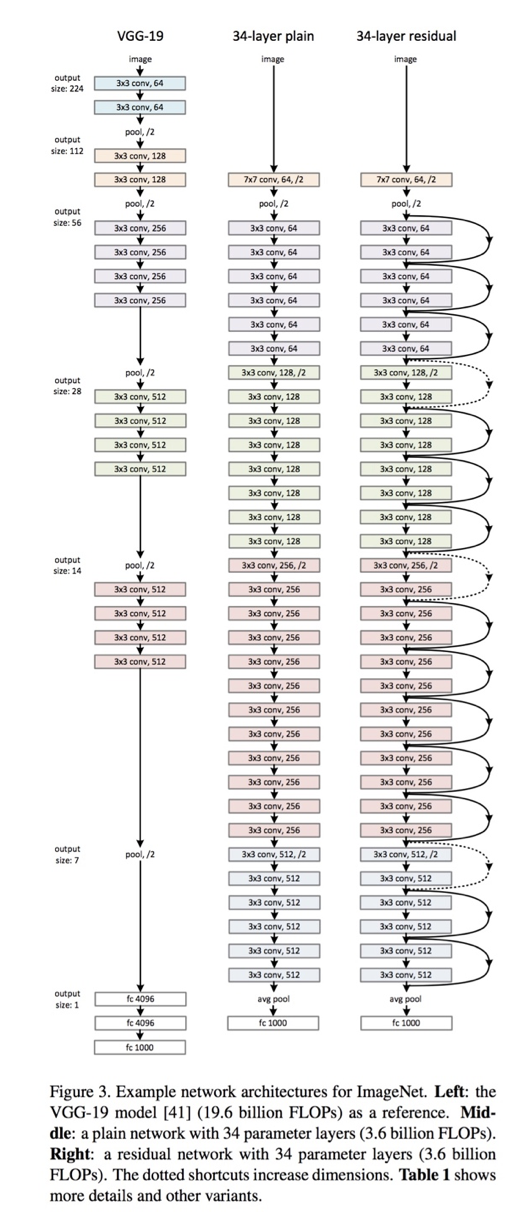
Вы можете видеть, что после того, как вы начали с одного сверточного слоя и максимального объединения, есть 4 похожих слоя с разными размерами фильтров - все они используют операцию свертки 3 * 3. Кроме того, после каждых 2 сверток мы обходим / пропускаем промежуточный слой. Это основная концепция моделей ResNet. Эти пропущенные соединения называются «соединениями ярлыка идентификации» и используют так называемые остаточные блоки:
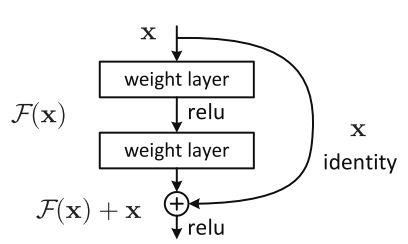
Проще говоря, авторы ResNet предполагают, что подгонка остаточного сопоставления намного проще, чем подгонка фактического сопоставления и, таким образом, применяют его ко всем слоям.
Это противоречит тому, что мы видели в Inception, и почти похоже на VGG16 в том смысле, что он просто накладывает слои друг на друга. ResNet просто изменяет базовое отображение.
Модель ResNet имеет множество вариантов, последняя из которых - ResNet152. Ниже представлена архитектура семейства ResNet с точки зрения используемых слоев:
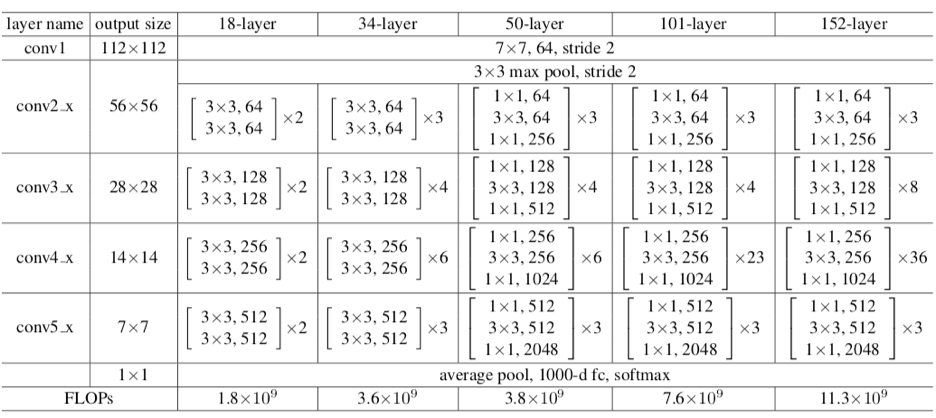
Давайте теперь используем ResNet50 в нашем наборе данных:
Шаг 1. Расширение данных и генераторы
# Add our data-augmentation parameters to ImageDataGenerator
train_datagen = ImageDataGenerator(rescale = 1./255., rotation_range = 40, width_shift_range = 0.2, height_shift_range = 0.2, shear_range = 0.2, zoom_range = 0.2, horizontal_flip = True)
test_datagen = ImageDataGenerator(rescale = 1.0/255.)
train_generator = train_datagen.flow_from_directory(train_dir, batch_size = 20, class_mode = 'binary', target_size = (224, 224))
validation_generator = test_datagen.flow_from_directory( validation_dir, batch_size = 20, class_mode = 'binary', target_size = (224, 224))
Шаг 2. Импортируйте базовую модель
Опять же, мы используем только базовую модель ResNet, поэтому мы оставим слои замороженными и изменим только последний слой.
Шаг 3: Постройте и скомпилируйте модель
Здесь я хотел бы показать вам еще более короткий код для использования модели ResNet50. Мы будем использовать эту модель как слой в последовательной модели, и просто добавим один полностью связанный слой поверх него.
Скомпилируем модель и на этот раз попробуем оптимизатор SGD:
base_model.compile(optimizer = tf.keras.optimizers.SGD(lr=0.0001), loss = 'binary_crossentropy', metrics = ['acc'])
Шаг 4: Подгонка модели
resnet_history = base_model.fit(train_generator, validation_data = validation_generator, steps_per_epoch = 100, epochs = 10)
Вот результат, который мы получаем:
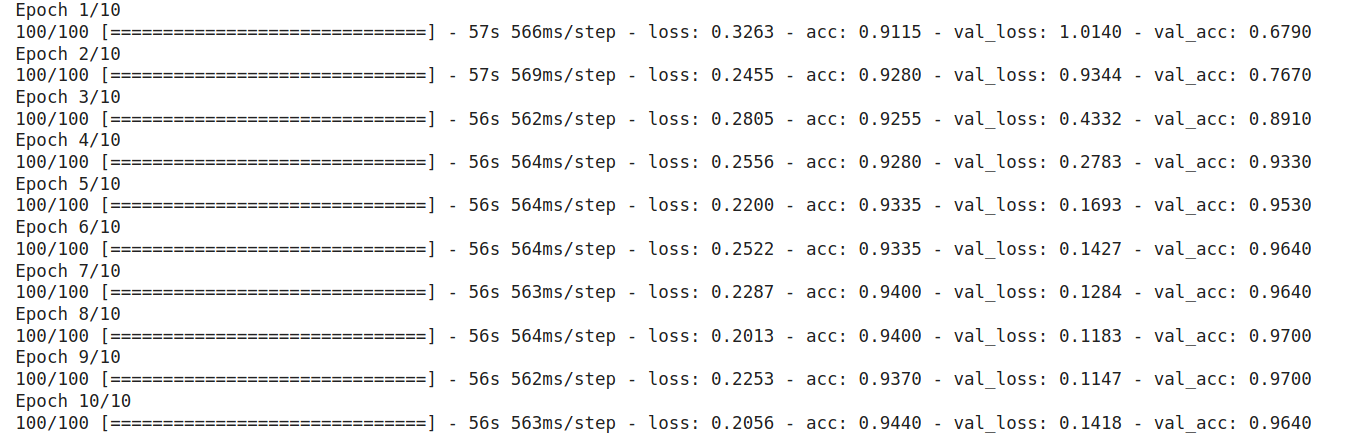
Вы можете увидеть, насколько хорошо он работает с нашим набором данных, и это делает ResNet50 одной из наиболее широко используемых предварительно обученных моделей. Как и VGG, у него есть и другие варианты, как мы видели в таблице выше. Примечательно, что ResNet не только имеет свои варианты, но также породил серию архитектур, основанных на ResNet. К ним относятся ResNeXt, ResNet как Ensemble и т.д. Кроме того, ResNet50 является одной из самых популярных моделей и достигает 5% ошибок в топ-5.
4. EfficientNet
Наконец, мы подошли к последней модели среди этих 4, которые вызвали волну в этой области, и, конечно же, это от Google. В EfficientNet авторы предлагают новый метод масштабирования под названием Compound Scaling. Короче говоря, это так: более ранние модели, такие как ResNet, следовали традиционному подходу к произвольному масштабированию размеров и добавлению все большего количества слоев.
Тем не менее, в документе предлагается, что если мы одновременно масштабируем размеры на фиксированную величину и делаем это равномерно, мы добиваемся гораздо большей производительности. Фактически, коэффициенты масштабирования может определять пользователь.
Хотя этот метод масштабирования можно использовать для любой модели на основе CNN, авторы начали со своей собственной базовой модели под названием EfficientNetB0:
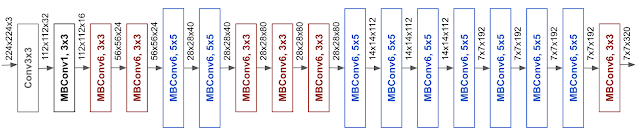
MBConv означает мобильное инвертированное узкое место Convolution (аналогично MobileNetv2). Они также предлагают формулу составного масштабирования со следующими коэффициентами масштабирования:
- Глубина = 1,20
- Ширина = 1,10
- Разрешение = 1,15
Эта формула снова используется для построения семейства EfficientNets - от EfficientNetB0 до EfficientNetB7. Ниже приведен простой график, показывающий сравнительные характеристики этого семейства по сравнению с другими популярными моделями:
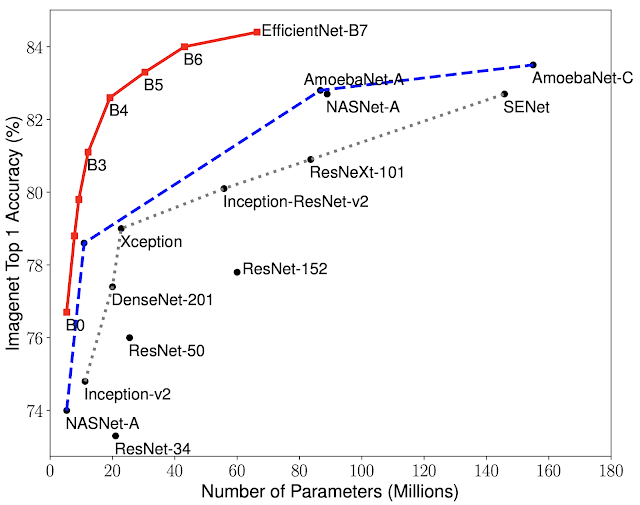
Как видите, даже базовая модель B0 начинается с гораздо более высокой точности, которая только увеличивается, и это тоже с меньшим количеством параметров. Например, у EfficientB0 всего 5,3 миллиона параметров!
Самый простой способ реализовать EfficientNet - это установить его, а остальные шаги аналогичны тому, что мы видели выше.
Установка EfficientNet:
pip install -U effectivenetИмпортируйте его
import efficientnet.keras as efn
Шаг 1. Увеличение изображения
Мы будем использовать те же размеры изображения, что и для VGG16 и ResNet50. К настоящему времени вы уже знакомы с процессом увеличения:
# Add our data-augmentation parameters to ImageDataGenerator
train_datagen = ImageDataGenerator(rescale = 1./255., rotation_range = 40, width_shift_range = 0.2, height_shift_range = 0.2, shear_range = 0.2, zoom_range = 0.2, horizontal_flip = True)
test_datagen = ImageDataGenerator(rescale = 1.0/255.)
train_generator = train_datagen.flow_from_directory(train_dir, batch_size = 20, class_mode = 'binary', target_size = (224, 224))
validation_generator = test_datagen.flow_from_directory( validation_dir, batch_size = 20, class_mode = 'binary', target_size = (224, 224))
Шаг 2: Загрузка базовой модели
Мы будем использовать версию EfficientNet B0, так как это самая простая из 8. Я призываю вас поэкспериментировать с остальными моделями, но помните, что модели становятся все более и более сложными, и возможно, не так хорошо подходит для простой задачи двоичной классификации.
base_model = efn.EfficientNetB0(input_shape = (224, 224, 3), include_top = False, weights = 'imagenet')
Опять же, давайте заморозим слои:
for layer in base_model.layers:
layer.trainable = False
Шаг 3: Постройте модель
Как и в Inceptionv3, мы выполним эти шаги на последнем слое:
x = model.output
x = Flatten()(x)
x = Dense(1024, activation="relu")(x)
x = Dropout(0.5)(x)
predictions = Dense(1, activation="sigmoid")(x)
model_final = Model(input = model.input, output = predictions)
Шаг 4: скомпилировать и подогнать
Давайте снова воспользуемся RMSProp Optimiser, хотя здесь я ввел параметр затухания:
model_final.compile(optimizers.rmsprop(lr=0.0001, decay=1e-6),loss='binary_crossentropy',metrics=['accuracy'])
Наконец мы подогнали модель к нашим данным:
eff_history = model_final.fit_generator(train_generator, validation_data = validation_generator, steps_per_epoch = 100, epochs = 10)
Итак, мы получили колоссальную точность 98% на нашей проверке, установленной всего за 10 epoch. Я призываю вас попробовать обучить больший набор данных с помощью EfficientNetB7 и поделиться с нами результатами ниже.
В заключение:
Подводя итог, в этой статье я представил вам 4 самые современные предварительно обученные модели для классификации изображений. Вот удобная таблица для обозначения этих моделей и их характеристик:
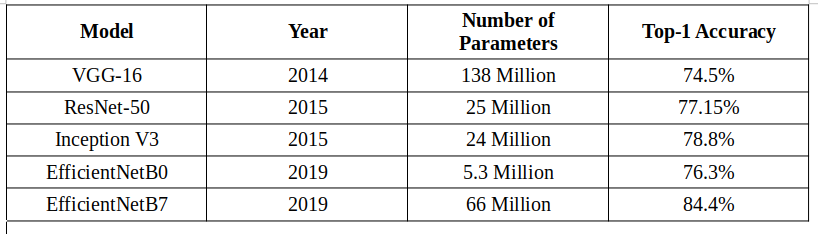
Я только представил обзор 4 лучших предварительно обученных моделей для классификации изображений и того, как их реализовать. Тем не менее, это постоянно растущая область, и всегда есть новая модель, на которую стоит рассчитывать и которая расширяет границы. Мне не терпится изучить эти новые модели, и я также призываю вас опробовать указанные выше модели на разных наборах данных с разными параметрами и поделиться своими результатами с нами в комментариях ниже!