2 простых способа нормализовать данные в Python

В этом руководстве мы узнаем, как нормализовать данные в Python. При нормализации меняем масштаб данных. Чаще всего масштабирование данных изменяется в диапазоне от 0 до 1.
Почему нам нужно нормализовать данные в Python?
Алгоритмы машинного обучения, как правило, работают лучше или сходятся быстрее, когда различные функции (переменные) имеют меньший масштаб. Поэтому перед обучением на них моделей машинного обучения данные обычно нормализуются.
Нормализация также делает процесс обучения менее чувствительным к масштабу функций. Это приводит к улучшению коэффициентов после тренировки.
Этот процесс повышения пригодности функций для обучения путем изменения масштаба называется масштабированием функций.
Формула нормализации приведена ниже:
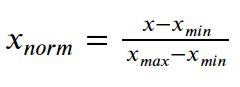
Мы вычитаем минимальное значение из каждой записи, а затем делим результат на диапазон. Где диапазон - это разница между максимальным значением и минимальным значением.
Шаги по нормализации данных в Python
Мы собираемся обсудить два разных способа нормализации данных в Python.
Первый - с помощью метода normalize() в sklearn.
Использование normalize() из sklearn
Начнем с импорта processing из sklearn.
from sklearn import preprocessing
Теперь давайте создадим массив с помощью Numpy.
import numpy as np
x_array = np.array([2,3,5,6,7,4,8,7,6])
Теперь мы можем использовать метод normalize() для массива. Этот метод нормализует данные по строке. Давайте посмотрим на метод в действии.
normalized_arr = preprocessing.normalize([x_array])
print(normalized_arr)
Полный код
Вот полный код из этого раздела:
from sklearn import preprocessing
import numpy as np
x_array = np.array([2,3,5,6,7,4,8,7,6])
normalized_arr = preprocessing.normalize([x_array])
print(normalized_arr)
Результат:
[0.11785113, 0.1767767 , 0.29462783, 0.35355339, 0.41247896, 0.23570226, 0.47140452, 0.41247896, 0.35355339]
Мы видим, что все значения теперь находятся в диапазоне от 0 до 1. Так работает метод normalize() в sklearn.
Вы также можете нормализовать столбцы в наборе данных, используя этот метод.
Нормализовать столбцы в наборе данных с помощью normalize()
Поскольку normalize() нормализует только значения по строкам, нам нужно преобразовать столбец в массив, прежде чем применять метод.
Чтобы продемонстрировать, мы собираемся использовать набор данных California Housing.
Начнем с импорта набора данных.
import pandas as pd
housing = pd.read_csv("/content/sample_data/california_housing_train.csv")
Затем нам нужно выбрать столбец и преобразовать его в массив. Мы собираемся использовать столбец total_bedrooms.
from sklearn import preprocessing
x_array = np.array(housing['total_bedrooms'])
normalized_arr = preprocessing.normalize([x_array])
print(normalized_arr)
Результат:
[[0.01437454 0.02129852 0.00194947 ... 0.00594924 0.00618453 0.00336115]]
Как нормализовать набор данных без преобразования столбцов в массив?
Давайте посмотрим, что произойдет, когда мы попытаемся нормализовать набор данных без преобразования функций в массивы для обработки.
from sklearn import preprocessing
import pandas as pd
housing = pd.read_csv("/content/sample_data/california_housing_train.csv")
d = preprocessing.normalize(housing)
scaled_df = pd.DataFrame(d, columns=names)
scaled_df.head()
Результат:

Здесь значения нормализованы по строкам, что может быть очень неинтуитивно. Нормализация по строкам означает, что нормализуется каждая отдельная выборка, а не признаки.
Однако вы можете указать ось при вызове метода для нормализации по элементу (столбцу).
Значение параметра оси по умолчанию установлено на 1. Если мы изменим значение на 0, процесс нормализации произойдет по столбцу.
from sklearn import preprocessing
import pandas as pd
housing = pd.read_csv("/content/sample_data/california_housing_train.csv")
d = preprocessing.normalize(housing, axis=0)
scaled_df = pd.DataFrame(d, columns=names)
scaled_df.head()
Результат:

Вы можете видеть, что столбец total_bedrooms в выходных данных совпадает с столбцом, который мы получили выше после преобразования его в массив и последующей нормализации.
Использование MinMaxScaler() для нормализации данных в Python
Когда дело доходит до нормализации данных, Sklearn предоставляет еще один вариант: MinMaxScaler.
Это более популярный выбор для нормализации наборов данных.
Вот код для нормализации набора данных жилья с помощью MinMaxScaler:
from sklearn import preprocessing
import pandas as pd
housing = pd.read_csv("/content/sample_data/california_housing_train.csv")
scaler = preprocessing.MinMaxScaler()
names = housing.columns
d = scaler.fit_transform(housing)
scaled_df = pd.DataFrame(d, columns=names)
scaled_df.head()
Результат:

Вы можете видеть, что значения на выходе находятся между (0 и 1).
MinMaxScaler также дает вам возможность выбрать диапазон функций. По умолчанию диапазон установлен на (0,1). Посмотрим, как изменить диапазон на (0,2).
from sklearn import preprocessing
import pandas as pd
housing = pd.read_csv("/content/sample_data/california_housing_train.csv")
scaler = preprocessing.MinMaxScaler(feature_range=(0, 2))
names = housing.columns
d = scaler.fit_transform(housing)
scaled_df = pd.DataFrame(d, columns=names)
scaled_df.head()
Результат:

Значения на выходе теперь находятся в диапазоне (0,2).
Вывод
Это два метода нормализации данных в Python. Мы рассмотрели два метода нормализации данных в разделе sklearn. Надеюсь, вам было весело учиться с нами!
 Александр Алесин
17.06.2021 в 19:54
Александр Алесин
17.06.2021 в 19:54