3 Простых способа создать график водопада на Python

Графики водопада (или диаграммы) часто используются для демонстрации кумулятивного изменения определенного значения с течением времени. В качестве альтернативы они могут использовать фиксированные категории (например, определенные события) вместо времени. Таким образом, такого рода сюжет может быть очень полезен при проведении презентаций для заинтересованных сторон бизнеса, поскольку мы можем легко показать, например, эволюцию доходов нашей компании/клиентской базы с течением времени.
В этой статье мы покажем вам, как легко создавать водопадные диаграммы на Python. Для этого мы будем использовать 3 разные библиотеки.
Настройка и данные
Как всегда, мы начинаем с импорта нескольких библиотек.
import pandas as pd
# plotting
import matplotlib.pyplot as plt
import waterfall_chart
from waterfall_ax import WaterfallChart
import plotly.graph_objects as go
# settings
plt.rcParams["figure.figsize"] = (16, 8)Затем мы готовим вымышленные данные для нашего игрушечного примера. Давайте предположим, что мы являемся специалистом по обработке данных в стартапе, который создал какое-то мобильное приложение. Чтобы подготовиться к следующим общим собраниям, нас попросили предоставить график, показывающий пользовательскую базу нашего приложения в 2022 году. Чтобы представить полную историю, мы хотим принять во внимание количество пользователей на конец 2021 года и ежемесячный подсчет в 2022 году. Для этого мы готовим следующий фрейм данных:
df = pd.DataFrame(
data={
"time": ["2021 end", "Jan", "Feb", "Mar", "Apr", "May", "Jun", "Jul", "Aug", "Sep", "Oct", "Nov", "Dec"],
"users": [100, 120, 110, 150, 160, 190, 240, 200, 230, 240, 250, 280, 300]
}
)Подход №1: waterfall_ax
Начнем с самого простого подхода. Должен сказать, я был очень удивлен, обнаружив, что Microsoft разработала небольшую библиотеку на основе matplotlib для создания каскадных графиков. Библиотека называется waterfall_ax, и вы можете прочитать о ней здесь. Чтобы создать график с использованием нашего набора данных, нам нужно запустить следующее:
fig, ax = plt.subplots(1, 1, figsize=(16, 8))
waterfall = WaterfallChart(df["users"].to_list())
wf_ax = waterfall.plot_waterfall(ax=ax, title="# of users in 2022")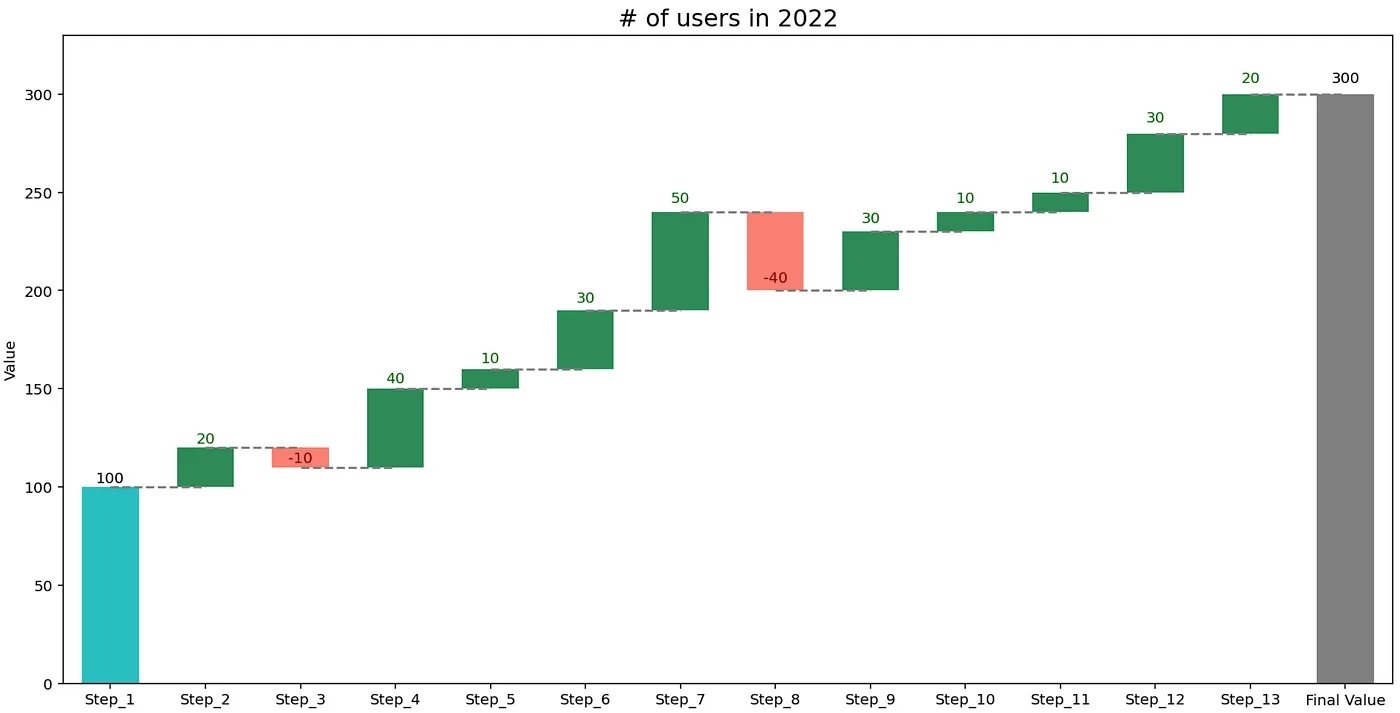
Одна вещь, которую следует отметить в библиотеке, заключается в том, что она работает со списками Python и на самом деле не поддерживает кадры данных pandas. Поэтому мы должны использовать метод to_list при указании столбца со значениями.
Хотя сюжет, безусловно, презентабелен, мы можем добиться немного большего, включив больше информации и заменив названия шагов по умолчанию. Мы делаем это в следующем фрагменте.
fig, ax = plt.subplots(1, 1, figsize=(16, 8))
waterfall = WaterfallChart(
df["users"].to_list(),
step_names=df["time"].to_list(),
metric_name="# users",
last_step_label="now"
)
wf_ax = waterfall.plot_waterfall(ax=ax, title="# of users in 2022")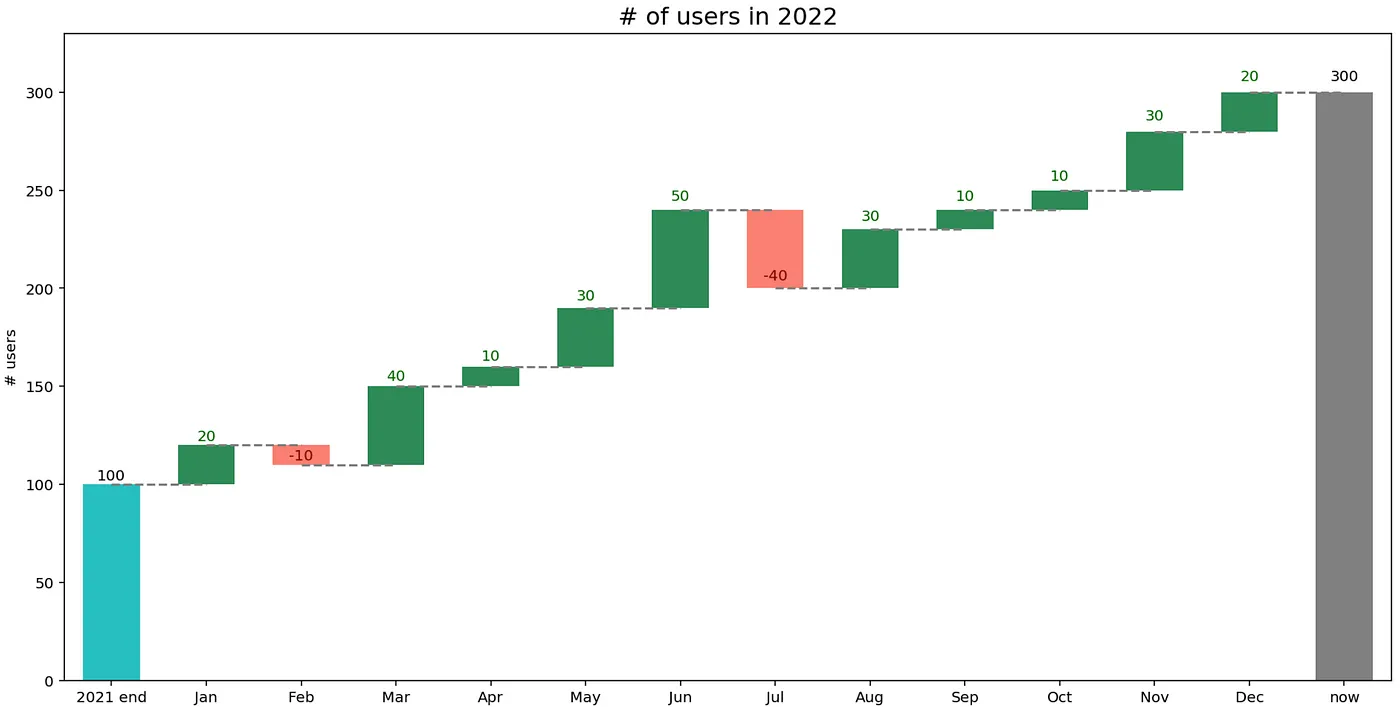
Подход №2: waterfall
Немного более сложный подход использует библиотеку waterfall. Чтобы создать график с использованием этой библиотеки, нам нужно добавить столбец, содержащий дельты, то есть различия между шагами.
Мы можем легко добавить новый столбец во фрейм данных и вычислить дельту, используя метод diff. Мы заполняем значение NA в первой строке количеством пользователей с конца 2021 года.
df_1 = df.copy()
df_1["delta"] = df_1["users"].diff().fillna(100)
df_1Затем мы можем использовать следующую однострочную строку для создания графика:
waterfall_chart.plot(df_1["time"], df_1["delta"])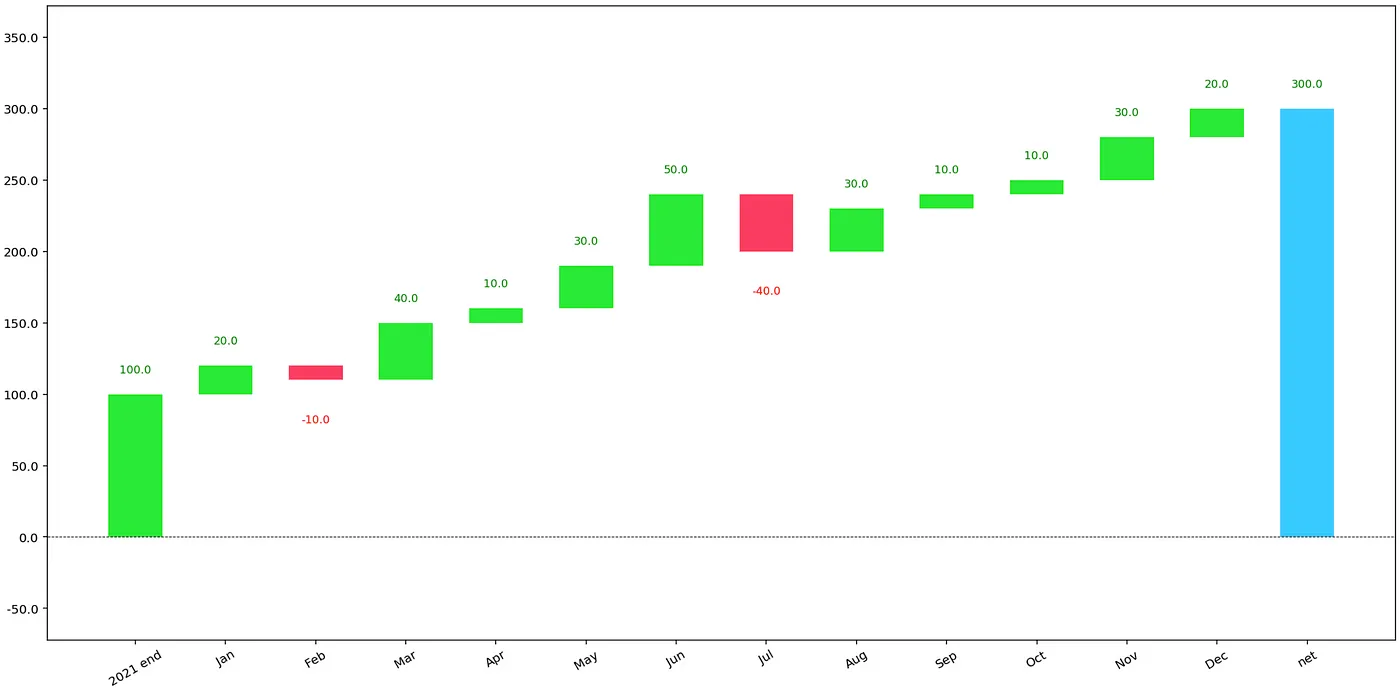
waterfall также предлагает возможность настройки сюжета. Мы делаем это в следующем фрагменте.
waterfall_chart.plot(
df_1["time"],
df_1["delta"],
threshold=0.2,
net_label="now",
y_lab="# users",
Title="# of users in 2022"
);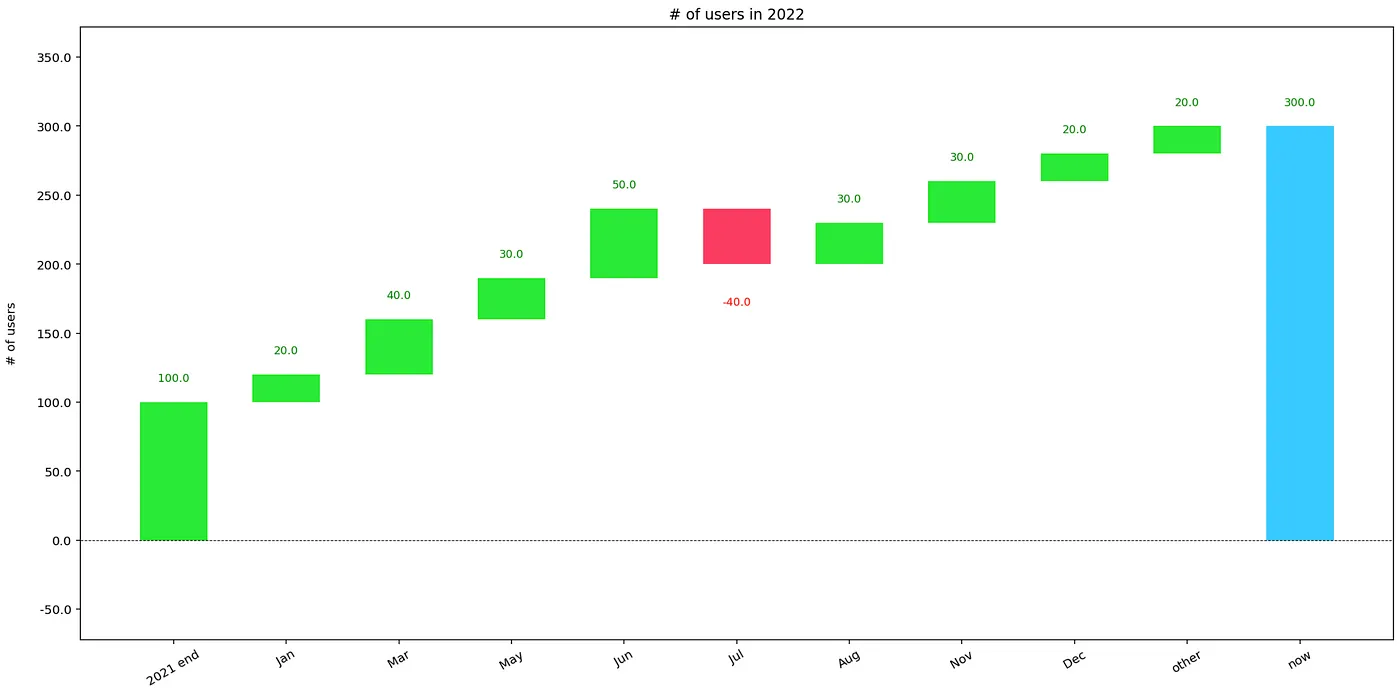
Хотя большинство дополнений говорят сами за себя, стоит упомянуть, что делает аргумент threshold. Он выражается в процентах от начального значения и группирует все изменения меньше указанного процента в новую категорию. По умолчанию эта категория называется other, но мы можем настроить ее с помощью аргумента other_label.
По сравнению с предыдущим графиком мы видим, что наблюдения с изменением 10 сгруппированы вместе: 3 раза +10 и 1 раз -10 дают чистую +20.
Эта функция группировки может быть полезна, когда мы хотим скрыть довольно много индивидуально незначительных значений. Например, такая логика группировки используется в библиотеке shap при построении значений SHAP на каскадном графике.
Подход № 3: plotly
В то время как в первых двух подходах использовались довольно нишевые библиотеки, последний будет использовать библиотеку, с которой вы наверняка знакомы — plotly. Еще раз, нам нужно сделать некоторые приготовления на входном фрейме данных, чтобы сделать его совместимым с plotly подходом.
df_2 = df_1.copy()
df_2["delta_text"] = df_2["delta"].astype(str)
df_2["measure"] = ["absolute"] + (["relative"] * 12)
df_2Мы создали новый столбец с именем delta_text, который содержит изменения, закодированные в виде строк. Мы будем использовать их в качестве меток на графике. Затем мы также определили столбец measure, который содержит меры, используемые plotly. Существует три типа мер, принимаемых библиотекой:
relative- указывает на изменения в последовательности,absolute- используется для установки начального значения или сброса вычисленного итога,total- используется для вычисления сумм.
Подготовив кадр данных, мы можем создать каскадный график, используя следующий фрагмент:
fig = go.Figure(
go.Waterfall(
measure=df_2["measure"],
x=df_2["time"],
textposition="outside",
text=df_2["delta_text"],
y=df_2["delta"],
)
)
fig.update_layout(
title="# of users in 2022",
showlegend=False
)
fig.show()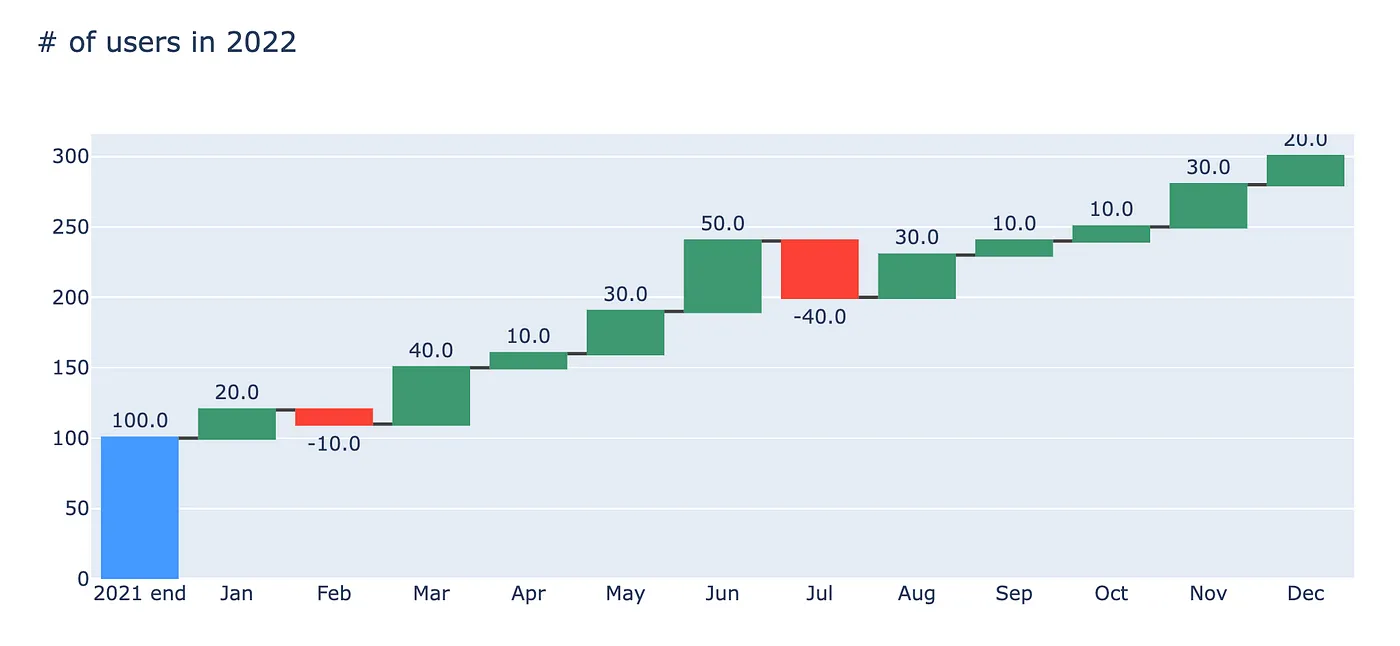
Естественно, самым большим преимуществом использования библиотеки plotly является тот факт, что графики полностью интерактивны — мы можем увеличивать масштаб, просматривать всплывающие подсказки для получения дополнительной информации (в данном случае, чтобы увидеть совокупную сумму) и т.д.
Одно явное отличие от предыдущих графиков заключается в том, что мы не видим последний блок, показывающий нетто/итого. Естественно, мы также можем добавить его с помощью plotly. Чтобы сделать это, мы должны добавить новую строку во фрейм данных.
total_row = pd.DataFrame(
data={
"time": "now",
"users": 0,
"delta":0,
"delta_text": "",
"measure": "total"
},
index=[0]
)
df_3 = pd.concat([df_2, total_row], ignore_index=True)Как вы можете видеть, нам не нужно указывать конкретные значения. Вместо этого мы предоставляем показатель “total”, который будет использоваться для вычисления суммы. Кроме того, мы добавляем метку “now”, чтобы получить тот же график, что и раньше.
Код, используемый для генерации графика, на самом деле не изменился, единственное отличие состоит в том, что мы используем фрейм данных с дополнительной строкой.
fig = go.Figure(
go.Waterfall(
measure=df_3["measure"],
x=df_3["time"],
textposition="outside",
text=df_3["delta_text"],
y=df_3["delta"],
)
)
fig.update_layout(
title="# of users in 2022",
showlegend=False
)
fig.show()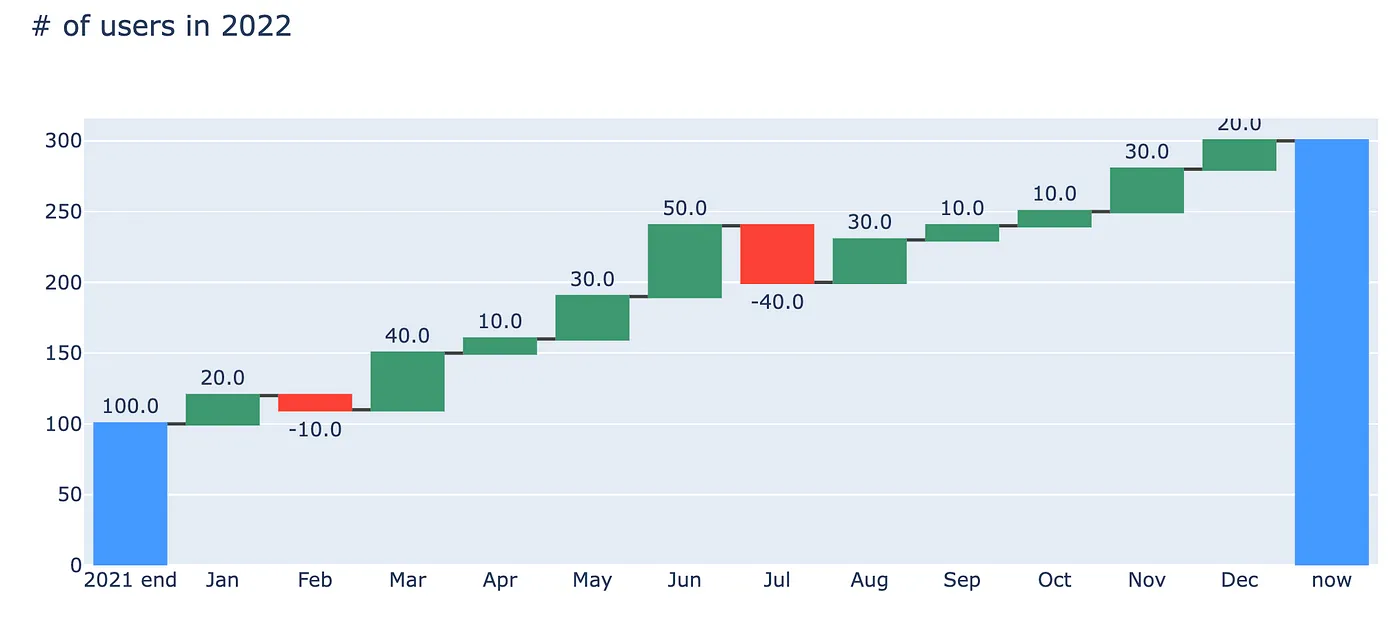
Вы можете прочитать больше о создании водопадных графиков в plotly здесь.
Подведение итогов
- Мы показали, как легко и быстро подготовить графики водопада на Python, используя три различные библиотеки:
waterfall_ax,waterfallиplotly. - При создании ваших графиков стоит помнить, что разные библиотеки используют разные типы входных данных (либо необработанные значения, либо дельты).
Вы можете найти код, используемый в этой статье, на GitHub.