24 Важные функции Pandas, которые необходимо знать для каждого анализа данных

Python — один из самых популярных и быстрорастущих языков программирования в мире. Он имеет сильную поддержку сообщества, и вы можете найти пакет практически для любой области, такой как разработка программного обеспечения, веб-разработка, анализ данных и т. д.
Pandas - это одна из таких мощных библиотек python для анализа данных, которая используется для структурирования, изменения и манипулирования данными. Он построен на пакете NumPy, и его ключевая структура данных известна как DataFrame. DataFrame позволяет нам хранить табличные данные в строках и столбцах.
В этой статье мы рассмотрим 24 наиболее мощных функции Pandas, которые необходимы для любого анализа. Использование этих функций поможет вам понять, что возможно с Pandas, и сэкономить время при следующем анализе данных.
24 мощных функции Pandas
Мы начнем с импорта необходимых пакетов:
import numpy as np
import pandas as pdТеперь давайте посмотрим на функции:
1. read_csv, read_excel
Наиболее распространенным способом создания DataFrame является чтение данных из различных форматов файлов, таких как CSV, Excel и текстовые файлы.
Мы можем прочитать CSV или текстовый файл как DataFrame pandas, используя функцию read_csv(), как показано ниже:
df_1 = pd.read_csv('filename.txt')
df_2 = pd.read_csv('filename.csv')Если у нас есть файл Excel вместо файла CSV, мы будем использовать pd.read_excel.
df_3 = pd.read_excel('filename.xlsx')Обычно функцию head() используют после read_csv или read_excel, чтобы просмотреть несколько верхних строк фрейма данных.
df_1.head() ## return top 5 rows by defaultЕсли мы хотим просмотреть 10 верхних строк DataFrame, мы можем указать это в функции head:
df_1.head(10) ## This will return top 10 rows Пример
В приведенном ниже коде мы читаем набор данных о конфигурации мобильных устройств с помощью функции read_csv() и просматриваем 5 верхних строк. Мы будем использовать этот набор данных для большинства наших примеров.
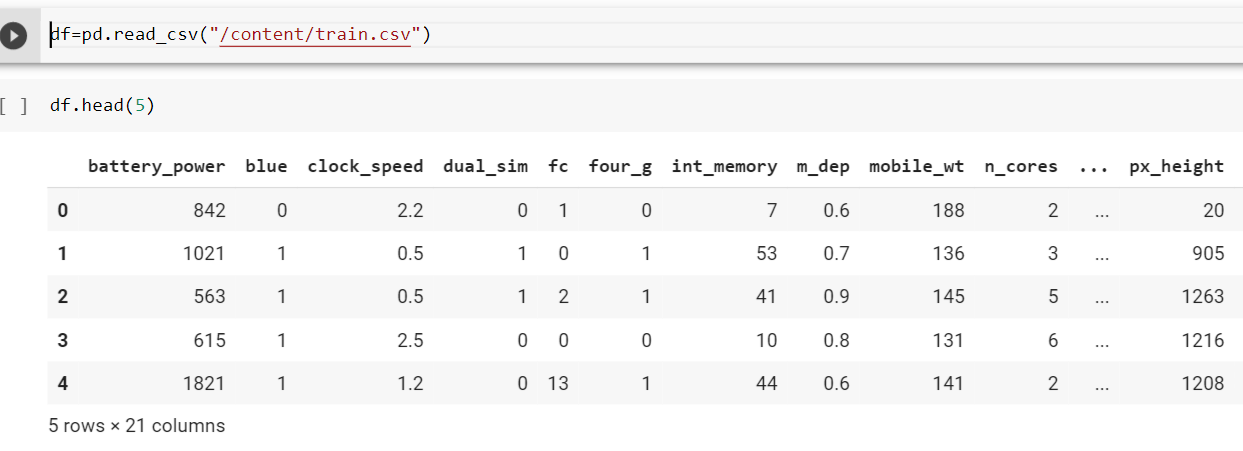
2. info()
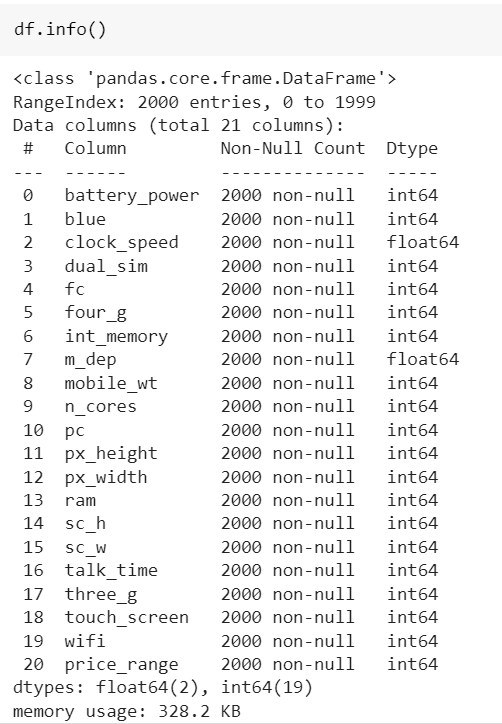
Функция info помогает нам собирать информацию или обзор наших наборов данных, таких как количество строк и столбцов, название столбцов, тип данных столбцов и количество ненулевых точек данных в каждом из столбцов.
dataset.info()Пример
3. columns
При работе с наборами данных, содержащими много столбцов (более 10-12), мы не можем видеть все столбцы с помощью функции head. Используя функцию «columns», мы можем напечатать имена всех столбцов нашего DataFrame:
df.columnsПример

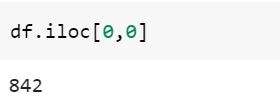
4. iloc()
Функция iloc() используется для фильтрации/извлечения данных с использованием индексов строк и столбцов в качестве параметров. Индексы начинаются с 0, то есть на первую строку или столбец будет ссылаться индекс 0.
df.iloc[row_index, column_index]Пример
Извлечение первой строки DataFrame.

Извлечение значения, соответствующего 1-й строке и 1-му столбцу DataFrame.
Мы также можем извлечь ряд строк и столбцов. Приведенный ниже код извлекает первые 10 строк (индекс 10 не является частью выходных данных) и столбцы с индексами от 1 до 4 (индекс 5 не является частью выходных данных).
df.iloc[:10,1:5]
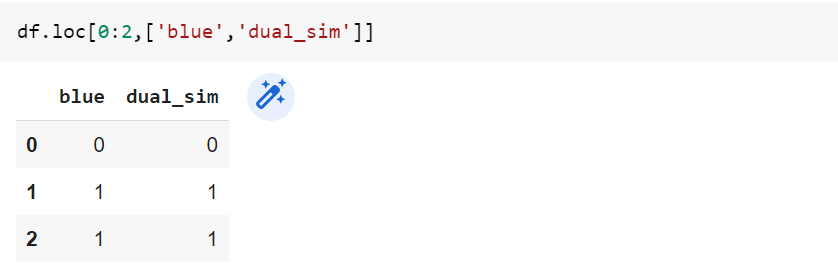
5. loc()
Функция loc() почти аналогична функции .iloc(). Используя функцию, мы можем указать индекс строки и имя столбца, который мы хотим извлечь. Ниже приведен синтаксис:
df.loc[row_index, column_name]Пример
6. corr()
Функция corr() дает корреляцию между всеми комбинациями столбцов набора данных. Корреляция — очень полезный статистический показатель, который очень помогает в анализе. Если два столбца имеют высокую корреляцию (0,8+), то мы можем игнорировать один из столбцов нашего анализа.
df.corr()Пример
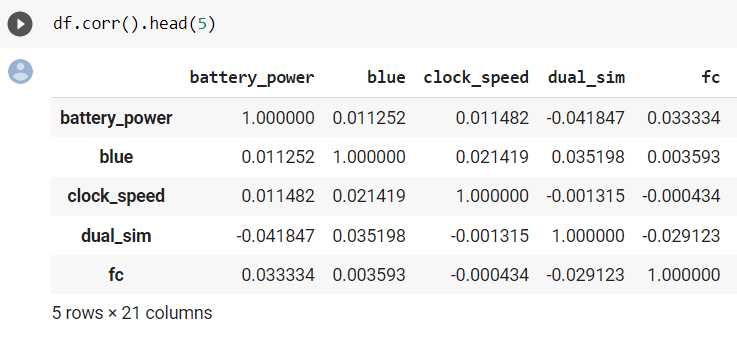
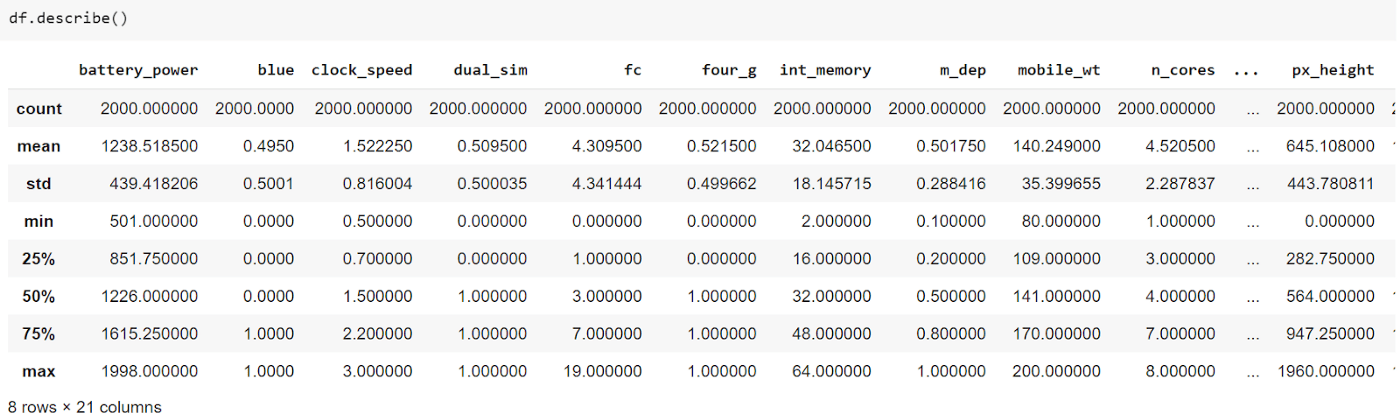
7. describe()
Функцию description() можно использовать для предоставления некоторых основных статистических показателей всего набора данных или нескольких столбцов, в зависимости от потребностей пользователя.
### show summary statistics of all
### the numeric features by default
df.describe()Пример
Сводную статистику по всем столбцам (числовым и категориальным) мы можем увидеть, используя аргумент — include = ‘all’.
df.describe(include = 'all')
8. drop()
Мы можем отбросить/удалить некоторые ненужные столбцы/строки, используя df.drop(). Аргумент оси используется, чтобы указать, хотим ли мы удалить строки или столбцы DataFrame. Axis = 0 для строк и Axis = 1 для столбцов.
df = df.drop(column, axis = 1) ## dropping a column Пример
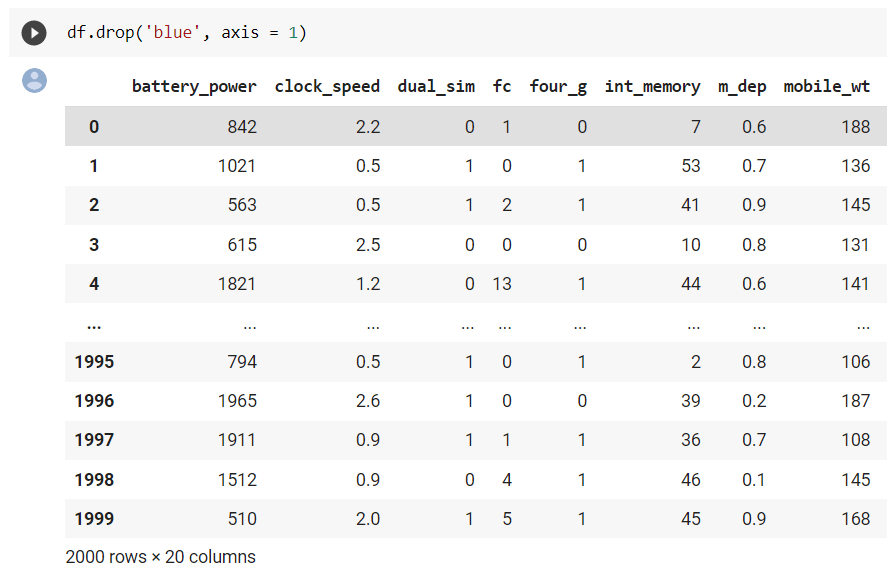
Мы видим, что общее количество столбцов уменьшилось с 21 до 20.
9. shape
Функция shape используется для определения количества строк и столбцов DataFrame.
df.shapeПример

10. isnull()
Функция isnull() используется для проверки наличия нулевых значений в DataFrame. Он возвращает True (или 1) для нулевых значений и False (или 0) для ненулевых значений.
Функция isnull() обычно используется вместе с функцией sum() для определения количества нулевых значений в разных столбцах DataFrame.
df.isnull().sum()Пример

11. groupby()
Функция groupby() используется для суммирования данных. Мы можем сгруппировать данные по определенной переменной/столбцу и узнать полезную информацию о группах.
df.groupby(['column1']).aggregate_function()В этом примере мы будем использовать другой набор данных, чтобы четко объяснить функцию groupby(). Мы создаем набор данных с информацией о выбросах углерода различных моделей автомобилей.
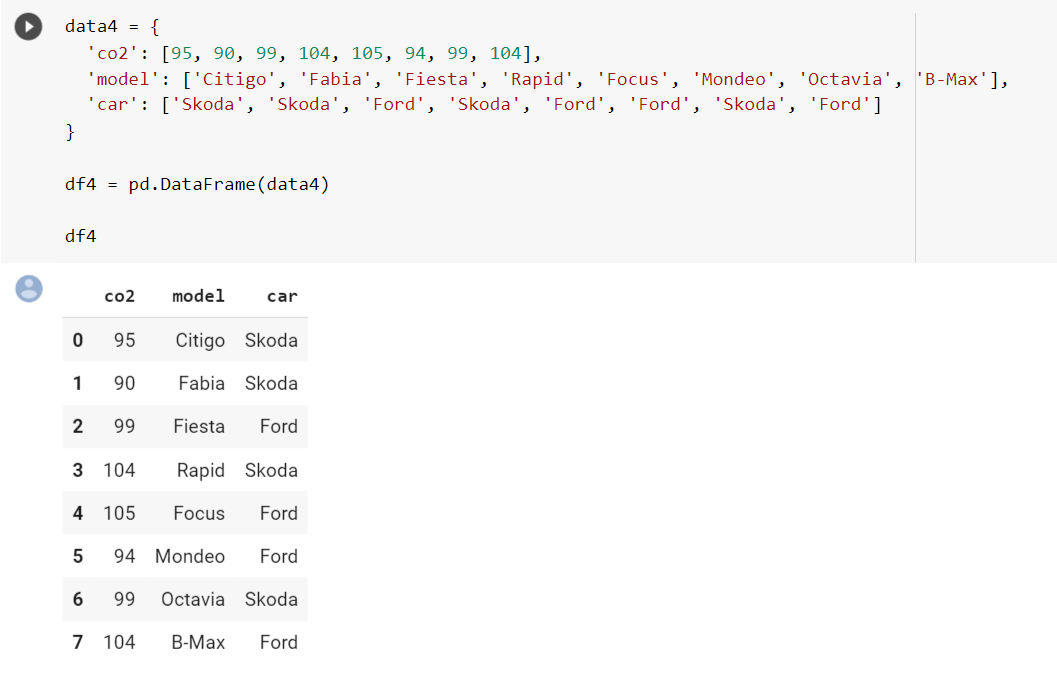
Найдем средние выбросы углекислого газа каждым автомобилем.
Пример

Функция groupby() группирует набор данных по столбцу «автомобиль» и находит средние выбросы CO2 для автомобилей.
12. select_dtypes()
Можно выбрать столбцы определенного типа данных с помощью функции select_dtypes().
df.select_dtypes('data_type')Пример
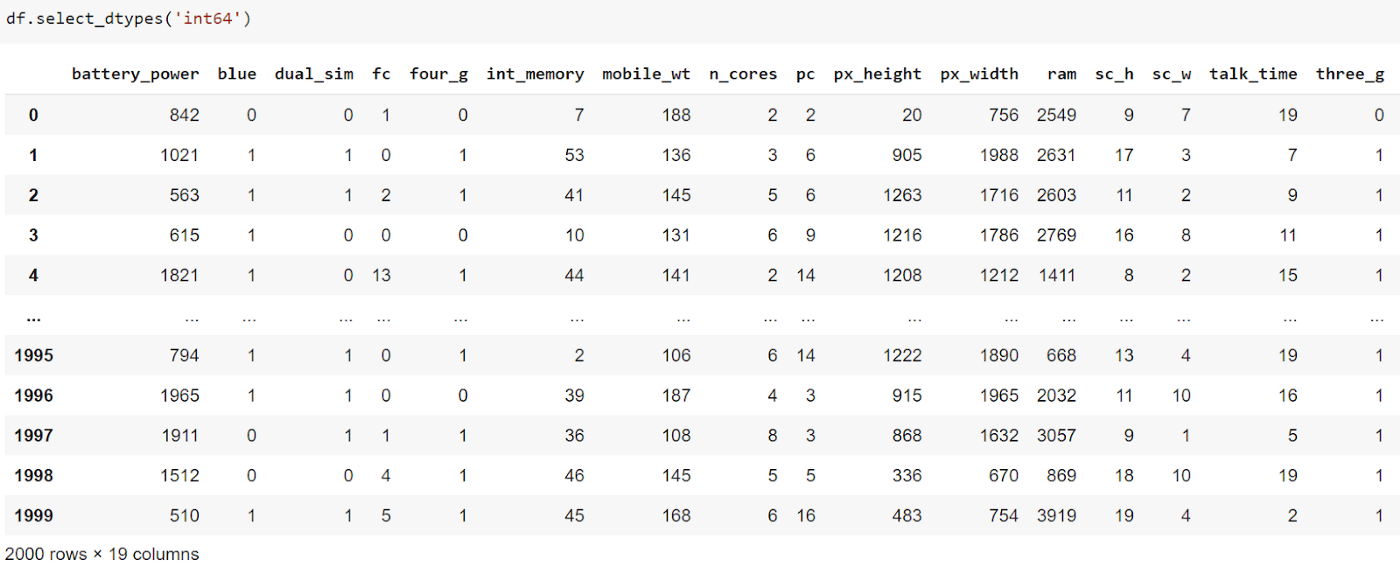
Мы видим, что выбрано только 19 столбцов, так как два других столбца имеют тип «float64».
13. sample()
Когда размер набора данных слишком велик, работа над полным набором данных занимает много времени и замедляет ход анализа. Решение состоит в том, чтобы взять образец, представляющий набор данных, для выполнения анализа и прогнозного моделирования. Эту функцию можно использовать для получения определенного числа или определенной доли точек данных.
df.sample(n = 200) ### extracting 200 random samples Пример
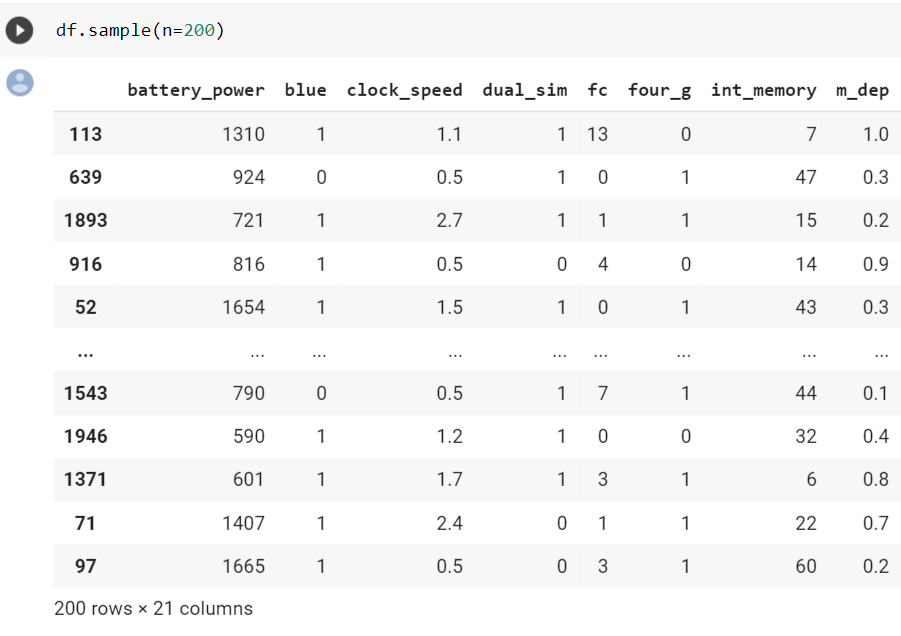
Это случайно выбранные 200 строк из общего числа 2000 строк в исходном наборе данных.
14. unique()
Функция unique() используется для поиска уникальных значений в столбце. Важно отметить, что уникальная функция применима только к серии pandas, а не к DataFrame, т. е. ее можно применять только к столбцу набора данных, а не ко всему набору данных.
df['column'].unique()Пример
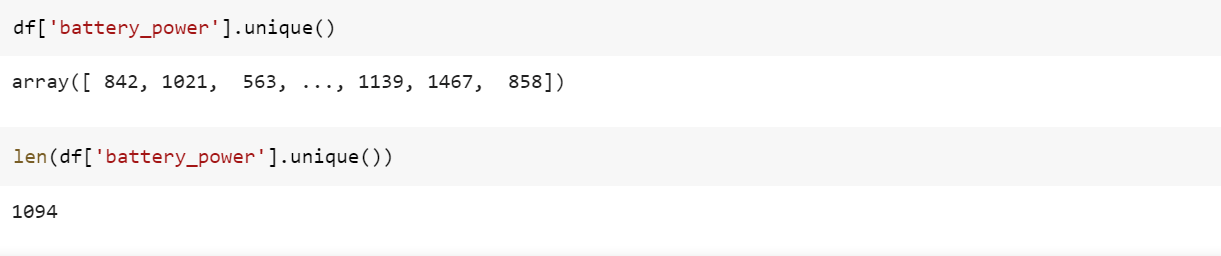
Функция len(), используемая вместе с функцией unique(), дает количество уникальных значений в столбце DataFrame.
15. nunique()
Функция nunique() используется для определения количества уникальных значений в столбце. Функцию len(), использовавшуюся вместе с функцией unique() в предыдущей функции, можно заменить на функцию nunique().
df.nunique()Пример

16. replace()
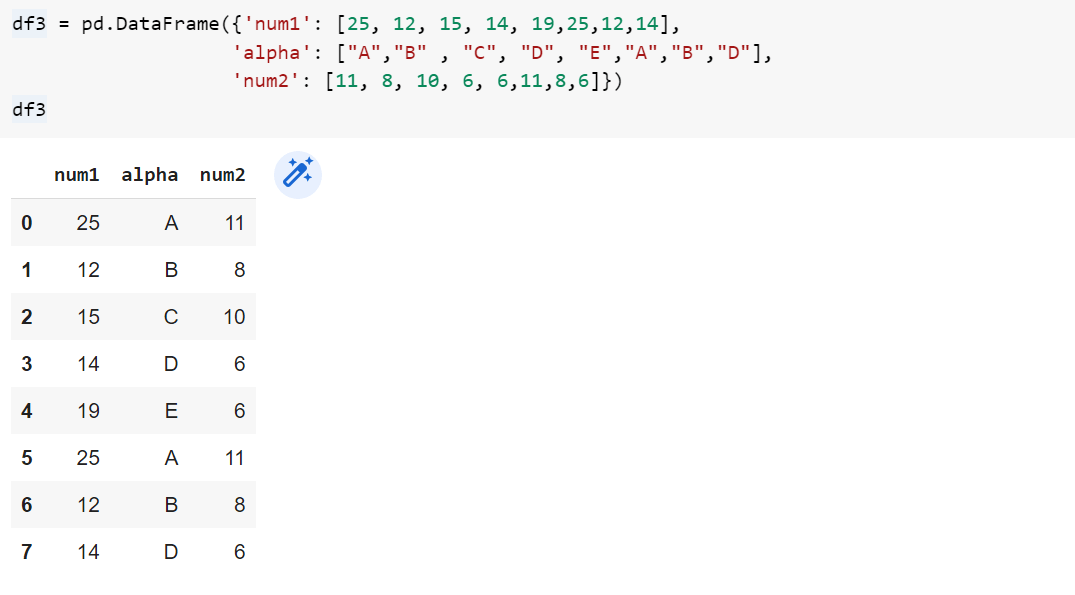
Функция замены заменяет значения столбца значением, определенным пользователем. Нам нужно предоставить старое значение и новые значения в качестве аргументов функции replace().
df.replace(old_value, new_value)Мы будем использовать пользовательский DataFrame для следующего примера.
Пример

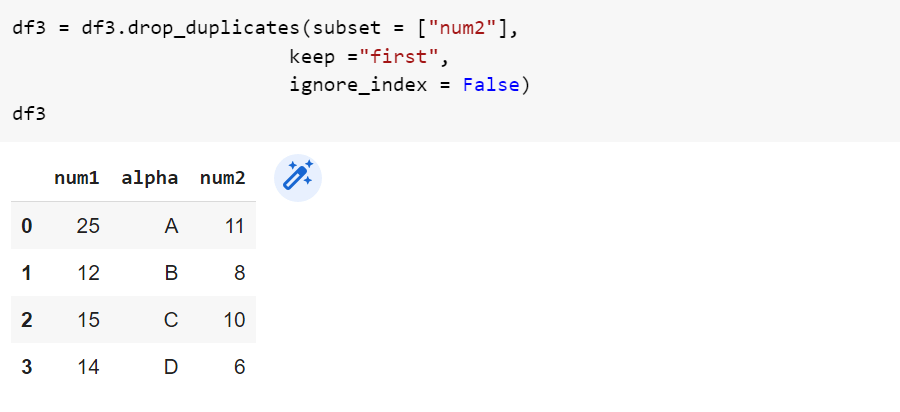
17. drop_duplicates()
Функция drop_duplicates(), как следует из названия, удаляет повторяющиеся строки из нашего набора данных. Хранение повторяющихся значений в нашем наборе данных влияет на генерируемую информацию, поэтому очистка данных важна, чтобы избежать просчетов.
df.drop_duplicates(subset,keep)Аргумент подмножества используется для указания столбца/столбцов, для которых мы хотим удалить дубликаты.
Параметр «keep» используется для определения того, какое значение из повторяющихся значений следует сохранить. Если мы хотим сохранить первое встречающееся значение, мы используем keep = ‘first’, иначе ‘last’.
Пример
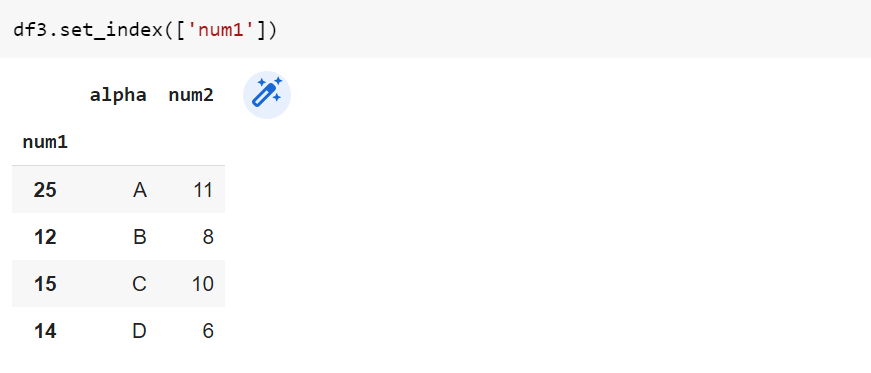
18. set_index()
Функция set_index() используется для установки индекса DataFrame. Столбец DataFrame можно использовать в качестве нового индекса.
df.set_index('column_name')Пример
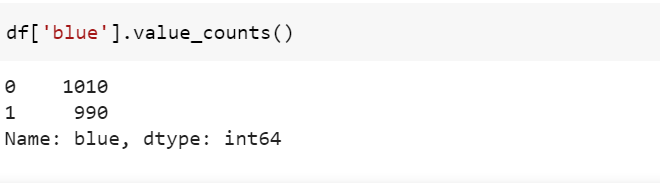
19. value_counts()
Функция value_counts возвращает частоту уникальных элементов в столбце DataFrame.
df.value_counts()Пример
20. rank()
Функция rank() присваивает ранг столбцам DataFrame. Ранг, связанный со столбцом, увеличивается по мере увеличения значения в столбце (по возрастанию по умолчанию). Мы также можем применить ранг в нисходящей последовательности.
df.rank()Пример
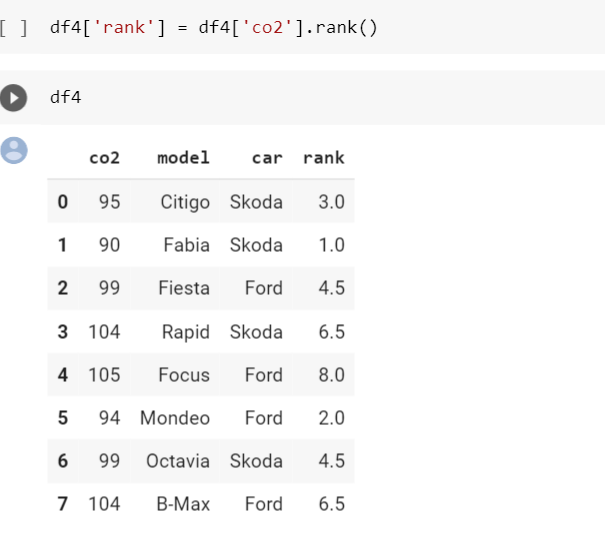
В приведенном выше примере ранг устанавливается на основе столбца co2. Ранг увеличивается с увеличением значения co2, и если 2 строки имеют одинаковое значение co2, то ранг представляет собой среднее значение двух рангов.
21. Bar plot
Гистограмма используется для отображения частоты значений в категориальном столбце. Это график, в котором используются прямоугольные столбцы с высотой, пропорциональной значениям, которые они представляют, для отображения категории данных.
Пример
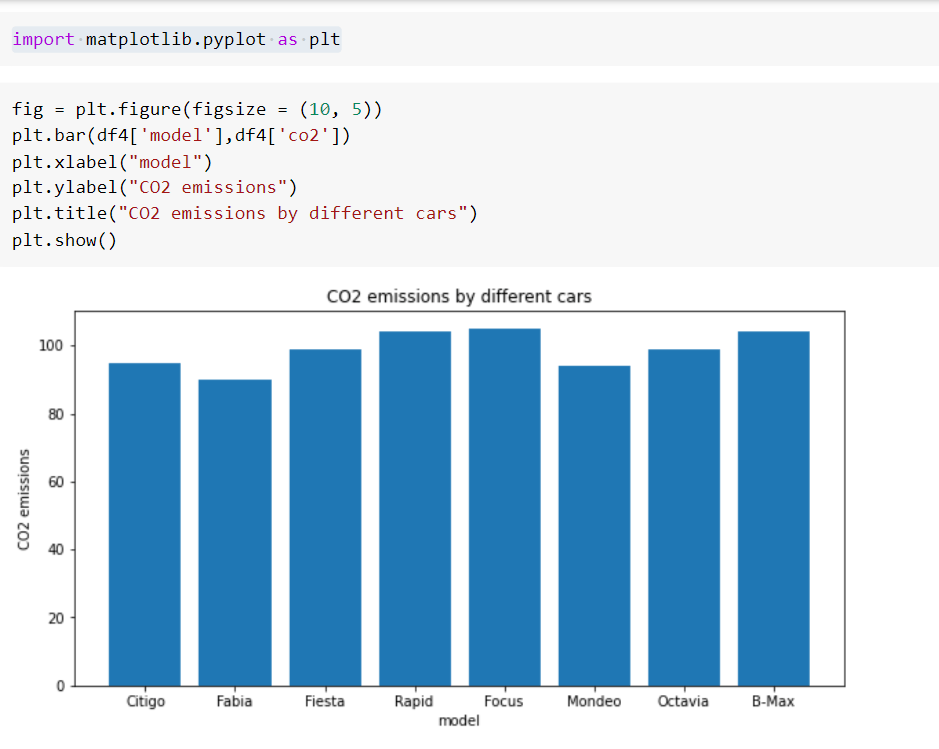
22. Line plot
Линейный график чаще всего используется для представления изменения числовых значений во времени (дни, месяцы, годы и т. д.). Простая функция plot() строит линейный график.
Пример
Чтобы показать линейный график, мы будем использовать синтетические данные временного ряда.
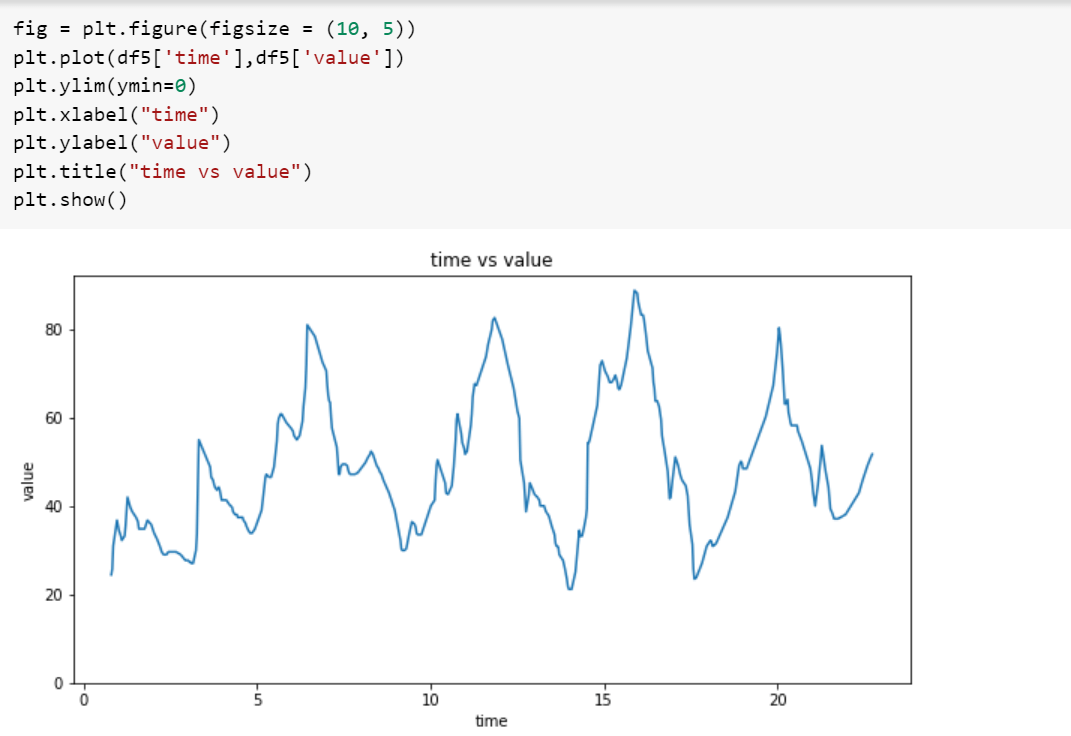
Ось X представляет дни, а ось Y представляет значения, связанные с днями.
Функция ylim() используется для установки значения оси Y в 0.
23. Scatter plot
Диаграмма рассеяния показывает связь между двумя непрерывными переменными и отображает ее с помощью точек. Он также используется для визуализации корреляции между двумя переменными.
Пример
На приведенном ниже графике мы показываем связь между числами и их квадратами значений.
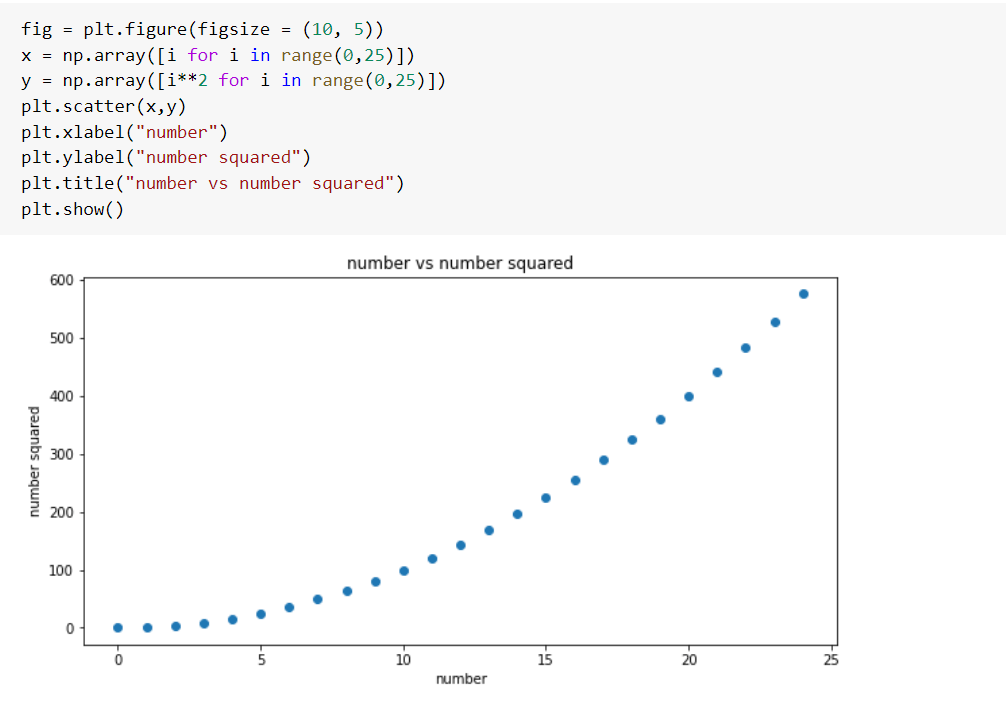
24. Histogram
Гистограмма — это график, показывающий частотное распределение диапазонов значений (бинов) числового столбца. Он покажет частоту значений (по оси Y), которые попадают в определенный диапазон значений (по оси X).
Пример
Мы будем использовать наш старый набор данных для демонстрации гистограммы.
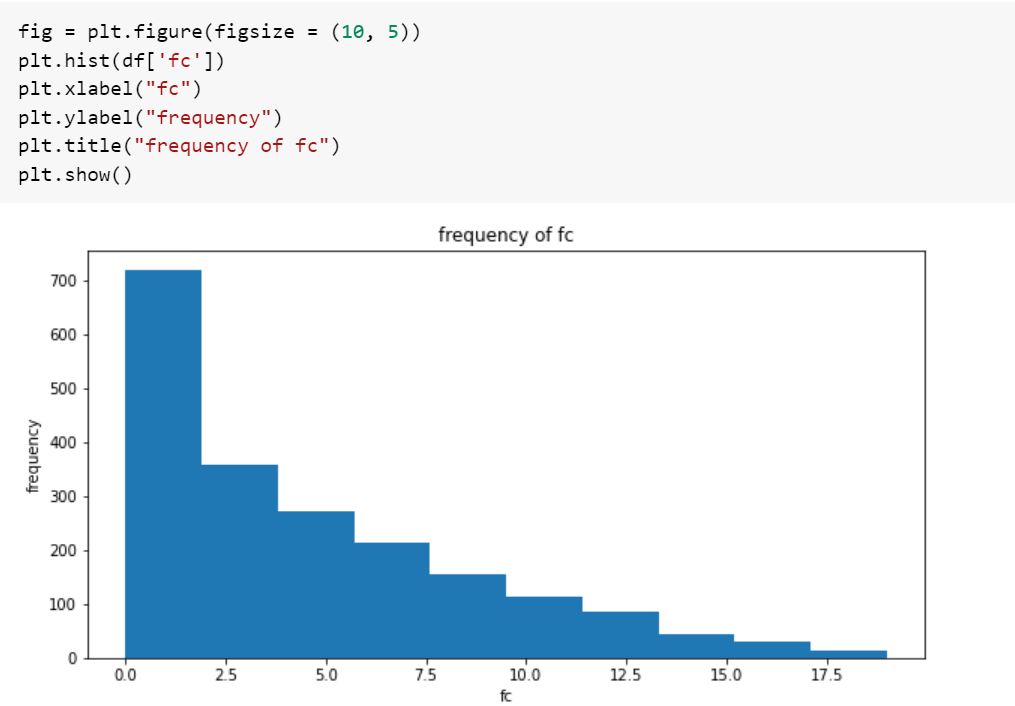
В этой статье мы указали важные функции Pandas, по нашему мнению, для каждого специалиста по науке о данных.