Анализ тональности в Python с помощью TextBlob
Современные технологии НЛП позволяют нам анализировать естественные языки на разных уровнях: от простой сегментации текстовой информации до более сложных методов категоризации настроений.
Однако это не обязательно означает, что вы должны быть очень продвинутыми в программировании для реализации высокоуровневых задач, таких как анализ тональности в Python.
Анализ настроений
Алгоритмы анализа настроений в основном сосредоточены на определении мнений, отношений и даже смайлов в корпусе текстов. Диапазон устоявшихся настроений значительно варьируется от одного метода к другому. В то время как стандартный анализатор определяет до трех основных полярных эмоций (положительную, отрицательную, нейтральную), пределы более продвинутых моделей шире.
Следовательно, они могут смотреть за пределы полярности и определять шесть «универсальных» эмоций (например, гнев, отвращение, страх, счастье, печаль и удивление):

Более того, в зависимости от задачи, над которой вы работаете, также можно собрать дополнительную информацию из контекста, например об авторе или теме, которая при дальнейшем анализе может предотвратить более сложную проблему, чем обычная классификация полярностей, а именно субъективность / объективность. идентификация.
Например, это предложение от Business Insider: "In March, Elon Musk described concern over the coronavirus outbreak as a "panic" and "dumb," and he's since tweeted incorrect information, such as his theory that children are "essentially immune" to the virus." выражает субъективность через личное мнение Э. Маска, а также автора текста.
Анализ тональности в Python с помощью TextBlob
Подход, который пакет TextBlob применяет к анализу тональности, отличается тем, что он основан на правилах и поэтому требует заранее определенного набора категоризированных слов. Эти слова можно, например, загрузить из базы данных NLTK. Более того, тональность определяется на основе семантических отношений и частоты каждого слова во входном предложении, что позволяет получить в результате более точный результат.
После того, как первый шаг выполнен и модель Python снабжена необходимыми входными данными, пользователь может получить оценки настроения в форме полярности и субъективности, которые обсуждались в предыдущем разделе. Мы можем увидеть, как этот процесс работает, в этой статье Forum Kapadia:
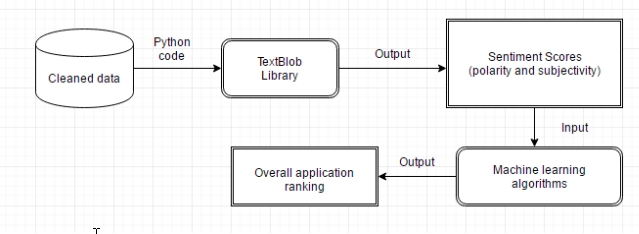
Результатом TextBlob для задачи полярности является число с плавающей точкой в диапазоне [-1.0, 1.0], где -1.0 - отрицательная полярность, а 1.0 положительная. Эта оценка также может быть равна 0, что означает нейтральную оценку утверждения, поскольку оно не содержит слов из обучающего набора.
Принимая во внимание, что задача идентификации субъективности / объективности сообщает о поплавке в пределах диапазона [0.0, 1.0], где 0.0 это очень объективное предложение и 1.0 очень субъективно.
Существуют различные примеры взаимодействия Python с анализатором настроений TextBlob: начиная с модели, основанной на различных наборах данных Kaggle (например, обзоры фильмов), до расчета настроений к твиту через API Twitter.
Но давайте посмотрим на простой анализатор, который можно применить к определенному предложению или короткому тексту. Сначала начнем с импорта библиотеки TextBlob:
from textblob import TextBlob
После импорта мы загрузим предложение для анализа и создадим экземпляр объекта TextBlob, а также присвоим свойство sentiment нашему собственному analysis:
sentence = '''The platform provides universal access to the world's best education, partnering with top universities and organizations to offer courses online.'''
analysis = TextBlob(sentence).sentiment
print(analysis)
Свойство sentiment представляет собой namedtuple представления Sentiment(polarity, subjectivity).
Где ожидаемый результат анализа:
Sentiment(polarity=0.5, subjectivity=0.26666666666666666)
Более того, также возможно получить результаты полярности или субъективности по отдельности, просто выполнив следующее:
from textblob import TextBlob
sentence = '''The platform provides universal access to the world's best education, partnering with top universities and organizations to offer courses online.'''
analysisPol = TextBlob(sentence).polarity
analysisSub = TextBlob(sentence).subjectivity
print(analysisPol)
print(analysisSub)
Что даст нам результат:
0.5
0.26666666666666666
Одна из замечательных особенностей TextBlob заключается в том, что он позволяет пользователю выбирать алгоритм для реализации высокоуровневых задач НЛП:
PatternAnalyzer- классификатор по умолчанию, построенный на библиотеке паттерновNaiveBayesAnalyzer- модель НЛТК, обученная на корпусе обзоров фильмов
Чтобы изменить настройки по умолчанию, мы просто в коде укажем анализатор NaiveBayes. Давайте проведем анализ настроений твитов прямо из Twitter:
from textblob import TextBlob
import tweepy
from textblob.sentiments import NaiveBayesAnalyzer
После этого нам нужно установить соединение с Twitter API через ключи API (которые вы можете получить через учетную запись разработчика):
api_key = 'XXXXXXXXXXXXXXX'
api_secret = 'XXXXXXXXXXXXXXX'
access_token = 'XXXXXXXXXXXXXXX'
access_secret = 'XXXXXXXXXXXXXXX'
twitter = tweepy.OAuthHandler(api_key, api_secret)
api = tweepy.API(twitter)
Теперь мы можем проводить анализ твитов на любую тему. Искомое слово (например, блокировка) может состоять как из одного слова, так и из нескольких. Более того, эта задача может занять много времени из-за огромного количества твитов. Рекомендуется ограничить вывод:
corpus_tweets = api.search("lockdown", count=5)
for tweet in corpus_tweets:
print(tweet.text)
Вывод этого последнего фрагмента кода вернет пять твитов, в которых упоминается искомое слово в следующей форме:
RT@DhwaniPandya: How Asia's densest slum contained the virus and the economic catastrophe that stares at the hardworking slum population...
Последним шагом в этом примере является переключение модели по умолчанию на анализатор NLTK, который возвращает свои результаты namedtuple в виде Sentiment(classification, p_pos, p_neg):
blob_object = TextBlob(tweet.text, analyzer=NaiveBayesAnalyzer())
analysis = blob_object.sentiment
print(analysis)
Наконец, наша модель Python даст нам следующую оценку настроения:
Sentiment(classification='pos', p_pos=0.5057908299783777, p_neg=0.49420917002162196)
Вывод
В этой статье мы рассмотрели, что такое анализ тональности, после чего использовали библиотеку TextBlob для выполнения анализа тональности импортированных предложений, а также твитов.