Быстрый совет: Визуализация векторных вкраплений OpenAI с помощью Plotly Express

В этой статье показано, как визуализировать векторные вкрапления OpenAI для поискового запроса с помощью t-SNE и Plotly Express.
Файл блокнота, использованный в данной статье, доступен на GitHub.
Введение
В замечательной статье автор демонстрирует, как визуализировать векторные вкрапления с помощью нескольких технологий. Мы можем использовать предыдущий набор данных из примера OpenAI, упростить код и использовать Plotly Express для создания аналогичной визуализации. Давайте посмотрим, как это сделать.
Мы будем следовать инструкциям по созданию блокнота.
Заполнение блокнота
Сначала мы установим библиотеку OpenAI:
!pip install openai --quietДалее мы определим модель встраивания:
import openai
EMBEDDING_MODEL = "text-embedding-ada-002"Далее мы зададим наш API-ключ OpenAI:
import os
import getpass
os.environ["OPENAI_API_KEY"] = getpass.getpass("OpenAI API Key:")
openai.api_key = os.environ["OPENAI_API_KEY"]Теперь мы добавим еще несколько библиотек:
!pip install matplotlib --quiet
!pip install scikit-learn --quiet
!pip install wget --quietи импортов:
import numpy as np
import pandas as pd
import wget
import astСейчас мы загрузим из OpenAI CSV-файл, содержащий текст и вкрапления, связанные с зимними Олимпийскими играми 2022 года:
embeddings_path = "https://cdn.openai.com/API/examples/data/winter_olympics_2022.csv"
file_path = "winter_olympics_2022.csv"
if not os.path.exists(file_path):
wget.download(embeddings_path, file_path)
print("File downloaded successfully.")
else:
print("File already exists in the local file system.")Теперь мы прочитаем файл в Dataframe и преобразуем данные в массив NumPy:
df = pd.read_csv(
"winter_olympics_2022.csv"
)
# Convert embeddings from CSV str type to NumPy Array
embedding_array = np.array(
df['embedding'].apply(ast.literal_eval).to_list()
)Наш поисковый запрос - "золотая медаль по керлингу", и мы получим векторные вкрапления для этого из OpenAI:
from openai.embeddings_utils import get_embedding
query = "curling gold medal"
query_embedding_response = np.array(
get_embedding(query, EMBEDDING_MODEL)
)
Теперь найдем и сохраним евклидово расстояние между поисковым термином и загруженными ранее векторными вкраплениями:
from scipy.spatial.distance import cdist
df['distance'] = cdist(
embedding_array,
[query_embedding_response]
)и масштабируем значения между 0 и 1, а затем сохраняем их, как показано ниже:
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
scaler.fit(df[['distance']])
df['normalised'] = scaler.transform(df[['distance']])Наконец, мы создадим модель t-SNE и построим график данных с помощью Plotly Express:
import plotly.express as px
from sklearn.manifold import TSNE
# Create a t-SNE model
tsne_model = TSNE(
n_components = 2,
perplexity = 15,
random_state = 42,
init = 'random',
learning_rate = 200
)
tsne_embeddings = tsne_model.fit_transform(embedding_array)
# Create a DataFrame for visualisation
visualisation_data = pd.DataFrame(
{'x': tsne_embeddings[:, 0],
'y': tsne_embeddings[:, 1],
'Similarity': df['normalised']}
)
# Create the scatter plot using Plotly Express
plot = px.scatter(
visualisation_data,
x = 'x',
y = 'y',
color = 'Similarity',
color_continuous_scale = 'rainbow',
opacity = 0.3,
title = f"Similarity to '{query}' visualised using t-SNE"
)
plot.update_layout(
width = 650,
height = 650
)
# Show the plot
plot.show()На выходе должно получиться то, что показано на рисунке 1.
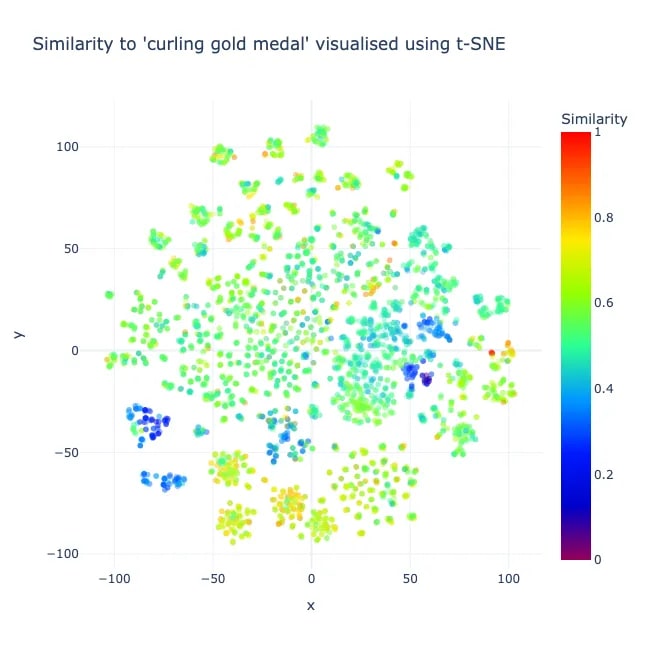
Цвета указывают на сходство с поисковым термином. В данном случае мы видим на графике красные области, которые находятся ближе, и синие области, которые находятся дальше.
Итоги
Визуализация данных может быть использована для получения представления о распределении данных. В этой статье мы рассмотрели, как с помощью векторных вкраплений и поискового запроса создать модель t-SNE и визуализировать ее с помощью Plotly Express. Этот простой пример показал, как можно использовать визуализацию данных для выявления закономерностей и тенденций.