Интеграция H2 с Python и Flask
H2 - это легкий сервер баз данных, написанный на Java. Он может быть встроен в приложения Java или работать как отдельный сервер.
В этом руководстве мы рассмотрим, почему H2 может быть хорошим вариантом для ваших проектов. Мы также узнаем, как интегрировать H2 с Python, создав простое Flask API.
Особенности H2
H2 был построен с учетом производительности.
«H2 - это сочетание: быстрый, стабильный, простой в использовании и функциональный».
Хотя H2 известен в основном потому, что он может быть встроен в приложения Java, он имеет некоторые интересные особенности, которые также применимы к его серверной версии. Давайте посмотрим на некоторые из них дальше.
Размер и производительность
Размер файла .jar, используемого для серверной версии, составляет около 2 МБ. Мы можем скачать его с сайта H2 в комплекте с дополнительными скриптами и документацией. Однако, если мы будем искать в Maven Central, мы сможем загрузить файл .jar самостоятельно.
Производительность H2 проявляется во встроенной версии. Несмотря на это, официальный тест показывает, что его версия клиент-сервер также впечатляет.
Базы данных в памяти и шифрование
Базы данных в памяти не являются постоянными. Все данные хранятся в памяти, поэтому скорость значительно увеличивается.
На сайте H2 объясняется, что базы данных в памяти особенно полезны при создании прототипов или при использовании баз данных только для чтения.
Шифрование - еще одна полезная функция для защиты данных в состоянии покоя. Базы данных могут быть зашифрованы с помощью алгоритма AES-128.
Другие полезные функции
H2 также предоставляет кластерный режим, возможность запускать несколько серверов и соединять их вместе. Запись выполняется на всех серверах одновременно, а чтение выполняется с первого сервера в кластере.
H2 удивляет своей простотой. Он предоставляет несколько полезных функций и прост в настройке.
Давайте запустим сервер H2 в рамках подготовки к следующим разделам:
java -cp ./h2-1.4.200.jar org.h2.tools.Server -tcp -tcpAllowOthers -tcpPort 5234 -baseDir ./ -ifNotExists
Аргументы, начинающиеся с tcp разрешают обмен данными с сервером. Аргумент ifNotExists позволяет создать базу данных при доступе к ней в первый раз.
Описание API и общая схема
Предположим, мы пишем API для регистрации всех найденных на сегодняшний день экзопланет. Экзопланеты - это планеты, находящиеся за пределами нашей Солнечной системы, вращающиеся вокруг других звезд.
Это наше простое определение API, CRUD для одного ресурса:
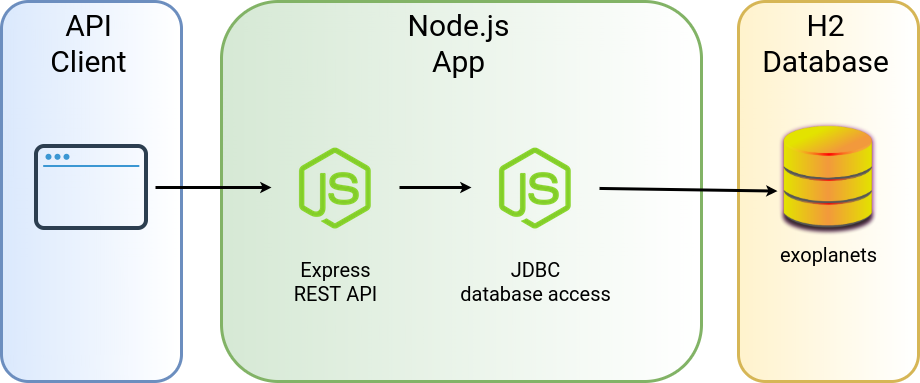
Это определение вместе с остальной частью кода, который мы увидим далее, доступно в этом репозитории GitHub.
Вот как наше приложение будет выглядеть в конце этого урока:
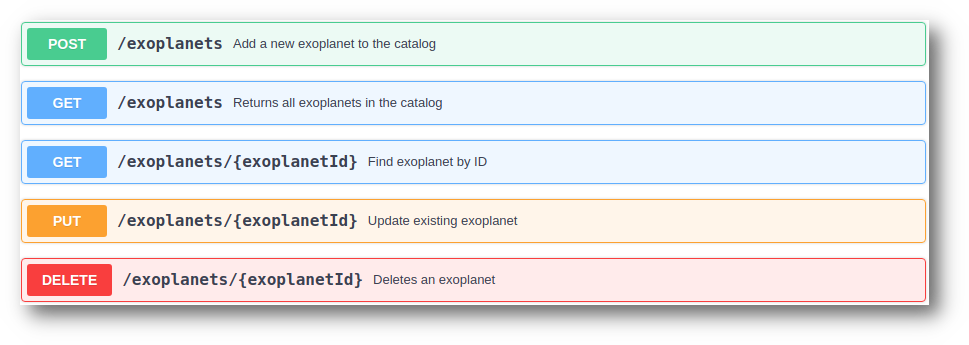
На другом конце мы находим сервер базы данных H2, работающий на TCP-порту 5234, как описано выше.
Наконец, наше приложение посередине состоит из трех файлов Python. У первого будет приложение Flask, которое будет отвечать на все запросы REST API. Все конечные точки, которые мы описали в определении выше, будут добавлены в этот файл.
Второй файл будет иметь функции сохранения, которые обращаются к базе данных для выполнения операций CRUD с использованием пакета JayDeBeApi.
Наконец, третий файл будет содержать схему, представляющую ресурс, которым управляет API. Мы будем использовать пакет Marshmallow для представления этой схемы. Первые два файла Python будут использовать эту схему для представления ресурсов и передачи их друг другу.
Схема базы данных
Чтобы сохранить ресурс Exoplanet в базе данных H2, мы должны сначала написать основные функции CRUD. Начнем с написания создания базы данных. Мы используем пакет JayDeBeApi для доступа к базам данных через JDBC:
import jaydebeapi
def initialize():
_execute(
("CREATE TABLE IF NOT EXISTS exoplanets ("
" id INT PRIMARY KEY AUTO_INCREMENT,"
" name VARCHAR NOT NULL,"
" year_discovered SIGNED,"
" light_years FLOAT,"
" mass FLOAT,"
" link VARCHAR)"))
def _execute(query, returnResult=None):
connection = jaydebeapi.connect(
"org.h2.Driver",
"jdbc:h2:tcp://localhost:5234/exoplanets",
["SA", ""],
"../h2-1.4.200.jar")
cursor = connection.cursor()
cursor.execute(query)
if returnResult:
returnResult = _convert_to_schema(cursor)
cursor.close()
connection.close()
return returnResult
Функция initialize() достаточно проста, так-же как и вспомогательные функции после. Она создает таблицу экзопланет, если она еще не существует. Эта функция должна быть выполнена до того, как наш API начнет получать запросы. Позже мы увидим, как это сделать с помощью Flask.
Функция _execute() содержит строку соединения и учетные данные для доступа к серверу базы данных. Для этого примера это проще, но есть возможности для улучшения безопасности. Мы могли бы сохранить наши учетные данные в другом месте, например, в переменных среды.
Кроме того, мы добавили в метод connect() путь к файлу jar H2, поскольку в нем есть драйвер, который нам нужен для подключения к H2 - org.h2.Driver.
Строка подключения JDBC заканчивается на /exoplanets. Это означает, что при первом подключении будет создана вызываемая база данных exoplanets.
Вы могли заметить, что _execute() можно вернуть результат SQL-запроса с помощью функции _convert_to_schema(). Давайте теперь посмотрим, как работает эта функция.
Схемы Marshmallow и функции базы данных CRUD
Некоторые SQL запросы возвращают табличные результаты, в частности оператор SELECT. JayDeBeApi отформатирует эти результаты как список кортежей. Например, для схемы, определенной в последнем разделе, мы могли бы получить результат, подобный этому:
connection = jaydebeapi.connect(...
cursor = connection.cursor()
cursor.execute("SELECT * FROM exoplanets")
cursor.fetchall()[(1, 'Sample1', 2019, 4.5, 1.2, 'http://sample1.com')]
Ничто не мешает нам управлять результатами в этом формате и в конечном итоге возвращать их клиенту API. Но забегая вперед, мы знаем, что будем использовать Flask , поэтому было бы хорошо уже возвращать результаты в формате, рекомендованном Flask.
В частности, мы будем использовать Flask-RESTful для облегчения использования маршрутов API. Этот пакет рекомендует использовать Marshmallow для анализа запросов. Этот шаг позволяет нормализовать объекты. Таким образом, мы можем отбросить неизвестные свойства и, например, выделить ошибки проверки.
Давайте посмотрим, как будет выглядеть класс Exoplanet, чтобы мы могли продолжить обсуждение:
from marshmallow import Schema, fields, EXCLUDE
class ExoplanetSchema(Schema):
id = fields.Integer(allow_none=True)
name = fields.Str(required=True, error_messages={"required": "An exoplanet needs at least a name"})
year_discovered = fields.Integer(allow_none=True)
light_years = fields.Float(allow_none=True)
mass = fields.Float(allow_none=True)
link = fields.Url(allow_none=True)
class Meta:
unknown = EXCLUDE
Определение свойств кажется знакомым. Это то же самое, что и схема базы данных, включая определение обязательных полей. Все поля имеют тип, определяющий некоторую проверку по умолчанию. Например, поле link определено как URL-адрес, поэтому строка, не похожая на URL-адрес, не будет действительной.
Сюда также могут быть включены конкретные сообщения об ошибках, например проверка для name.
В этом примере проекта мы хотим отбросить или исключить все неизвестные поля, и клиент API может отправлять ошибочные данные. Это достигается во вложенном Meta классе.
Теперь мы можем использовать методы Marshmallow load() и loads() для преобразования и проверки наших ресурсов.
Теперь, когда мы знакомы с Marshmallow, мы можем объяснить, что делает _convert_to_schema():
def _convert_to_schema(cursor):
column_names = [record[0].lower() for record in cursor.description]
column_and_values = [dict(zip(column_names, record)) for record in cursor.fetchall()]
return ExoplanetSchema().load(column_and_values, many=True)
В JayDeBeApi имена столбцов сохраняются в поле description, а данные могут быть получены с помощью метода fetchall(). Мы использовали составные части списков в первых двух строках, чтобы получить имена и значения столбцов и объединить их с помощью zip().
Последняя строка принимает объединенный результат и преобразует их в объекты ExoplanetSchema, которые Flask может обрабатывать в дальнейшем.
Теперь, когда мы объяснили функцию _execute() и класс ExoplanetSchema, давайте посмотрим все CRUD функции базы данных:
def get_all():
return _execute("SELECT * FROM exoplanets", returnResult=True)
def get(Id):
return _execute("SELECT * FROM exoplanets WHERE id = {}".format(Id), returnResult=True)
def create(exoplanet):
count = _execute("SELECT count(*) AS count FROM exoplanets WHERE name LIKE '{}'".format(exoplanet.get("name")), returnResult=True)
if count[0]["count"] > 0:
return
columns = ", ".join(exoplanet.keys())
values = ", ".join("'{}'".format(value) for value in exoplanet.values())
_execute("INSERT INTO exoplanets ({}) VALUES({})".format(columns, values))
return {}
def update(exoplanet, Id):
count = _execute("SELECT count(*) AS count FROM exoplanets WHERE id = {}".format(Id), returnResult=True)
if count[0]["count"] == 0:
return
values = ["'{}'".format(value) for value in exoplanet.values()]
update_values = ", ".join("{} = {}".format(key, value) for key, value in zip(exoplanet.keys(), values))
_execute("UPDATE exoplanets SET {} WHERE id = {}".format(update_values, Id))
return {}
def delete(Id):
count = _execute("SELECT count(*) AS count FROM exoplanets WHERE id = {}".format(Id), returnResult=True)
if count[0]["count"] == 0:
return
_execute("DELETE FROM exoplanets WHERE id = {}".format(Id))
return {}
Все функции в основном SQL запросов, но create() и update() заслуживают большего пояснения.
SQL оператор INSERT может получать в форме разделенные столбцы и значения INSERT INTO table (column1Name) VALUES ('column1Value'). Мы можем использовать функцию join() для объединения всех столбцов и разделения их запятыми, а также сделать что-то подобное для объединения всех значений, которые мы хотим вставить.
SQL оператор UPDATE немного сложнее. Его форма такая UPDATE table SET column1Name = 'column1Value'. Итак, нам нужно чередовать ключи и значения, и мы сделали это с помощью функции zip().
Все эти функции возвращают None при возникновении проблемы. Позже, когда мы вызовем их, нам нужно будет проверить это значение.
Давайте сохраним все функции базы данных в отдельном файле persistence.py, например чтобы мы могли добавить некоторый контекст при вызове функций:
import persistence
persistence.get_all()
REST API с Flask
Теперь, когда мы написали слой для абстрагирования доступа к базе данных, мы готовы написать REST API. Мы будем использовать пакеты Flask и Flask-RESTful, чтобы максимально упростить наше определение. Как мы узнали ранее, мы будем также использовать Marshmallow для проверки ресурсов.
Flask-RESTful требует определения одного класса для каждого ресурса API, в нашем случае только ресурса Exoplanet. Затем мы можем связать этот ресурс с таким маршрутом:
from flask import Flask
from flask_restful import Resource, Api
app = Flask(__name__)
api = Api(app)
class Exoplanet(Resource):
# ...
api.add_resource(Exoplanet, "/exoplanets", "/exoplanets/<int:Id>")
Таким образом, все наши маршруты, /exoplanets и /exoplanets/<int:Id> будут направлены в определенный нами класс.
Например, конечной точке GET /exoplanets ответит метод get(), вызываемый внутри класса Exoplanet. Поскольку у нас также есть конечная точка GET /exoplanet/<Id>, этот метод должен иметь дополнительный параметр, вызываемый Id.
Давайте посмотрим на весь класс, чтобы лучше понять это:
from flask import request
from flask_restful import Resource, abort
from marshmallow import ValidationError
import persistence
class Exoplanet(Resource):
def get(self, Id=None):
if Id is None:
return persistence.get_all()
exoplanet = persistence.get(Id)
if not exoplanet:
abort(404, errors={"errors": {"message": "Exoplanet with Id {} does not exist".format(Id)}})
return exoplanet
def post(self):
try:
exoplanet = ExoplanetSchema(exclude=["id"]).loads(request.json)
if not persistence.create(exoplanet):
abort(404, errors={"errors": {"message": "Exoplanet with name {} already exists".format(request.json["name"])}})
except ValidationError as e:
abort(405, errors=e.messages)
def put(self, Id):
try:
exoplanet = ExoplanetSchema(exclude=["id"]).loads(request.json)
if not persistence.update(exoplanet, Id):
abort(404, errors={"errors": {"message": "Exoplanet with Id {} does not exist".format(Id)}})
except ValidationError as e:
abort(405, errors=e.messages)
def delete(self, Id):
if not persistence.delete(Id):
abort(404, errors={"errors": {"message": "Exoplanet with Id {} does not exist".format(Id)}})
Остальные HTTP запросы обрабатываются таким же образом, как и GET, с помощью методов, с именами post(), put() и delete().
Как мы уже говорили ранее, логические ошибки при доступе к базе данных приводят к возврату функцией None. Эти ошибки фиксируются здесь, когда это необходимо.
Кроме того, исключения, которые представляют ошибки проверки, инициируются Marshmallow, поэтому эти ошибки также фиксируются и возвращаются пользователю вместе с соответствующей ошибкой.
Вывод
H2 - полезный, производительный и простой в использовании сервер баз данных. Хотя это пакет Java, он также может работать как отдельный сервер, поэтому мы можем использовать его в Python вместе с пакетом JayDeBeApi.
В этом руководстве мы определили простое приложение CRUD, чтобы показать, как получить доступ к базе данных и какие функции доступны. После этого мы определили REST API с Flask и Flask-RESTful.
Хотя некоторые концепции были опущены для краткости, такие как аутентификация и разбиение по страницам, это руководство является хорошей справкой для начала использования H2 в наших проектах Flask.