Использование Elasticsearch, Logstash и Kibana с приложениями Go

Elasticsearch - это система распределенного поиска и аналитики с открытым исходным кодом, основанная на Apache Lucene. В отличие от SQL и NoSQL баз данных, основной целью которых является хранение данных, Elasticsearch хранит и индексирует данные, чтобы их можно было быстро найти и проанализировать. Он также интегрируется с Logstash (конвейер обработки данных, который может принимать данные из нескольких источников, таких как журналы и базы данных) и Kibana (для визуализации данных), и вместе они составляют стек ELK.
В этом руководстве мы рассмотрим, как объединить возможности Elasticsearch и Golang. Мы создадим базовую систему управления контентом с возможностью создавать, читать, обновлять и удалять сообщения, а также с возможностью поиска сообщений через Elasticsearch.
Требования
Чтобы следовать образцу проекта в этом руководстве, вам понадобятся:
- Go (версия> = 1.14) установлен на вашем компьютере
- Установлены Docker и docker-compose
- Некоторое знакомство с Docker и языком программирования Go
Приступим
Создайте новый каталог в предпочтительном месте для размещения проекта (я называю свой letterpress) и инициализируйте новый модуль Go с помощью следующих команд:
mkdir letterpress && cd letterpress
go mod init gitlab.com/idoko/letterpress
Зависимости приложения включают:
- lib/pq - драйвер PostgreSQL для Go, совместимый с пакетом database/sql в стандартной библиотеке Go.
- elastic/go-elasticsearch - официальный клиент Elasticsearch для Golang
- gin-gonic/gin - HTTP фреймворк, который мы будем использовать для REST API нашего приложения.
- rs/zerolog - легкий регистратор
Установите зависимости, выполнив следующую команду в своем терминале:
go get github.com/lib/pq github.com/elastic/go-elasticsearch github.com/gin-gonic/gin github.com/rs/zerologЗатем создайте необходимые папки и файлы в каталоге проекта, чтобы они соответствовали структуре, приведенной ниже:
├── cmd
│ ├── api
│ │ └── main.go
├── db
│ ├── database.go
│ └── posts.go
├── .env
├── handler
├── logstash
│ ├── config
│ ├── pipelines
│ └── queries
└── models
└── post.go
cmd- Здесь находятся двоичные файлы приложения (т.е.main.go). Мы также добавили внутреннюю подпапкуapi, чтобы разрешить использование нескольких двоичных файлов, что в противном случае было бы невозможно.db- Пакет действует как мост между нашим приложением и базой данных. Мы также будем использовать его позже для хранения файлов миграции базы данных..env- Содержит сопоставление «ключ-значение» наших переменных среды (например, учетные данные базы данных)handler- В пакетhandlerвходят обработчики маршрутов API, работающие на платформе gin.logstash- Здесь мы храним код, связанный с logstash, такой как конфигурации конвейера и сопутствующиеDockerfilemodels- Модели - это структуры Golang, которые можно маршалировать в соответствующие объекты JSON.
Откройте файл .env в корневом каталоге проекта и настройте переменные среды следующим образом:
POSTGRES_USER=letterpress
POSTGRES_PASSWORD=letterpress_secrets
POSTGRES_HOST=postgres
POSTGRES_PORT=5432
POSTGRES_DB=letterpress_db
ELASTICSEARCH_URL="http://elasticsearch:9200"
Откройте файл post.go (в папке models) и настройте структуру Post:
package models
type Post struct {
ID int `json:"id,omitempty"`
Title string `json:"title"`
Body string `json:"body"`
}
Затем добавьте в db/database.go приведенный ниже код для управления подключением к базе данных:
package db
import (
"database/sql"
"fmt"
_ "github.com/lib/pq"
"github.com/rs/zerolog"
)
type Database struct {
Conn *sql.DB
Logger zerolog.Logger
}
type Config struct {
Host string
Port int
Username string
Password string
DbName string
Logger zerolog.Logger
}
func Init(cfg Config) (Database, error) {
db := Database{}
dsn := fmt.Sprintf("host=%s port=%d user=%s password=%s dbname=%s sslmode=disable",
cfg.Host, cfg.Port, cfg.Username, cfg.Password, cfg.DbName)
conn, err := sql.Open("postgres", dsn)
if err != nil {
return db, err
}
db.Conn = conn
db.Logger = cfg.Logger
err = db.Conn.Ping()
if err != nil {
return db, err
}
return db, nil
}
В приведенном выше коде мы настраиваем конфигурацию базы данных и добавляем поле Logger, которое затем можно использовать для регистрации ошибок и событий базы данных.
Также откройте db/posts.go и реализуйте операции с базой данных для таблиц posts и post_logs, которые мы вскоре создадим:
package db
import (
"database/sql"
"fmt"
"gitlab.com/idoko/letterpress/models"
)
var (
ErrNoRecord = fmt.Errorf("no matching record found")
insertOp = "insert"
deleteOp = "delete"
updateOp = "update"
)
func (db Database) SavePost(post *models.Post) error {
var id int
query := `INSERT INTO posts(title, body) VALUES ($1, $2) RETURNING id`
err := db.Conn.QueryRow(query, post.Title, post.Body).Scan(&id)
if err != nil {
return err
}
logQuery := `INSERT INTO post_logs(post_id, operation) VALUES ($1, $2)`
post.ID = id
_, err = db.Conn.Exec(logQuery, post.ID, insertOp)
if err != nil {
db.Logger.Err(err).Msg("could not log operation for logstash")
}
return nil
}
Выше мы реализуем функцию SavePost, которая вставляет аргумент Post в базу данных. Если вставка прошла успешно, он переходит к регистрации операции и идентификатора, сгенерированного для нового сообщения, в таблице post_logs. Эти журналы ведутся на уровне приложения, но если вы чувствуете, что операции с базой данных не всегда проходят через приложение, вы можете попробовать сделать это на уровне базы данных с помощью триггеров. Позже Logstash будет использовать эти журналы для синхронизации нашего индекса Elasticsearch с нашей базой данных приложения.
По-прежнему в файле posts.go добавьте приведенный ниже код для обновления и удаления сообщений из базы данных:
func (db Database) UpdatePost(postId int, post models.Post) error {
query := "UPDATE posts SET title=$1, body=$2 WHERE id=$3"
_, err := db.Conn.Exec(query, post.Title, post.Body, postId)
if err != nil {
return err
}
post.ID = postId
logQuery := "INSERT INTO post_logs(post_id, operation) VALUES ($1, $2)"
_, err = db.Conn.Exec(logQuery, post.ID, updateOp)
if err != nil {
db.Logger.Err(err).Msg("could not log operation for logstash")
}
return nil
}
func (db Database) DeletePost(postId int) error {
query := "DELETE FROM Posts WHERE id=$1"
_, err := db.Conn.Exec(query, postId)
if err != nil {
if err == sql.ErrNoRows {
return ErrNoRecord
}
return err
}
logQuery := "INSERT INTO post_logs(post_id, operation) VALUES ($1, $2)"
_, err = db.Conn.Exec(logQuery, postId, deleteOp)
if err != nil {
db.Logger.Err(err).Msg("could not log operation for logstash")
}
return nil
}
Миграция базы данных с помощью golang-migrate
Хотя PostgreSQL автоматически создаст базу данных нашего приложения при ее настройке в контейнере Docker, нам нужно будет настроить таблицы самостоятельно. Для этого мы будем использовать golang-migrate/migrate для управления миграциями нашей базы данных. Установите migrate с помощью этого руководства и выполните команду ниже, чтобы сгенерировать файл миграции для таблицы сообщений:
migrate create -ext sql -dir db/migrations -seq create_posts_table
migrate create -ext sql -dir db/migrations -seq create_post_logs_table
Приведенная выше команда создаст четыре файла SQL в db/migrations, два из которых имеют расширение .up.sql, а два других оканчиваются на .down.sql. Миграции UP выполняются, когда мы применяем миграции. Поскольку в нашем случае мы хотим создать таблицы, добавьте в файл XXXXXX_create_posts_table.up.sql приведенный ниже блок кода:
CREATE TABLE IF NOT EXISTS posts (
id SERIAL PRIMARY KEY,
title VARCHAR(150),
body text
);
Точно так же откройте и исправьте XXXXXX_create_post_logs_table.up.sql, чтобы создать таблицу posts_logs следующим образом:
CREATE TABLE IF NOT EXISTS post_logs (
id SERIAL PRIMARY KEY,
post_id INT NOT NULL,
operation VARCHAR(20) NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
Миграция DOWN применяется, когда мы хотим откатить изменения, внесенные в базу данных. В нашем случае мы хотим удалить только что созданные таблицы. Добавьте приведенный ниже код в XXXXXX_create_posts_table.down.sql, чтобы удалить таблицу сообщений:
DROP TABLE IF EXISTS posts;
Сделайте то же самое для таблицы posts_logs , добавив приведенный ниже код в XXXXXX_create_post_logs_table.down.sql:
DROP TABLE IF EXISTS post_logs;
Elasticsearch и PostgreSQL как контейнеры Docker
Создайте файл docker-compose.yml в корне проекта и объявите сервисы, которые нужны нашему приложению, следующим образом:
version: "3"
services:
postgres:
image: postgres
restart: unless-stopped
hostname: postgres
env_file: .env
ports:
- "5432:5432"
volumes:
- pgdata:/var/lib/postgresql/data
api:
build:
context: .
dockerfile: Dockerfile
hostname: api
env_file: .env
ports:
- "8080:8080"
depends_on:
- postgres
elasticsearch:
image: 'docker.elastic.co/elasticsearch/elasticsearch:7.10.2'
environment:
- discovery.type=single-node
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
ports:
- "9200:9200"
volumes:
- esdata:/usr/share/elasticsearch/data
volumes:
pgdata:
driver: local
esdata:
driver: local
Сервисы включают:
postgres- База данных PostgreSQL, которую будет использовать наше приложение. Он также предоставляет порт PostgreSQL по умолчанию, чтобы мы могли получить доступ к нашей базе данных извне контейнера.api- Это REST API нашего приложения, который позволяет нам создавать и искать сообщения.elasticsearch- Образ Elasticsearch, используемый для нашей функции поиска. Мы также установим тип обнаружения какsingle-node, так как мы находимся в среде разработки
Затем создайте Dockerfile в папке проекта и заполните его приведенным ниже кодом:
FROM golang:1.15.7-buster
COPY go.mod go.sum /go/src/gitlab.com/idoko/letterpress/
WORKDIR /go/src/gitlab.com/idoko/letterpress
RUN go mod download
COPY . /go/src/gitlab.com/idoko/letterpress
RUN go build -o /usr/bin/letterpress gitlab.com/idoko/letterpress/cmd/api
EXPOSE 8080 8080
ENTRYPOINT ["/usr/bin/letterpress"]
В приведенном выше коде мы настроили Docker для создания нашего приложения с использованием образа Debian buster для Go. Затем он загружает зависимости приложения, создает приложение и копирует полученный двоичный файл в /usr/bin
Хотя мы еще не реализовали REST API, вы можете проверить прогресс, запустив в своем терминале docker-compose up--build, чтобы запустить сервисы.
При запущенном сервисе PostgreSQL экспортируйте имя источника данных (DSN) в качестве переменной среды и примените миграции, которые мы создали, выполнив следующие команды из корневого каталога проекта:
export PGURL="postgres://letterpress:letterpress_secrets@localhost:5432/letterpress_db?sslmode=disable"
migrate -database $PGURL -path db/migrations/ up
ПРИМЕЧАНИЕ. DSN имеет форматpostgres://USERNAME:PASSWORD@HOST:PORT/DATABASE?sslmode=SSLMODE. Не забудьте использовать свои значения, если они отличаются от тех, которые мы использовали в файле.envвыше.
Маршрутные хендлеры с gin-gonic/gin
Чтобы настроить наши маршруты API, создайте новый файл handler.go в папке handlers и настройте его для инициализации и регистрации соответствующих маршрутов:
package handler
import (
"github.com/elastic/go-elasticsearch/v7"
"github.com/gin-gonic/gin"
"github.com/rs/zerolog"
"gitlab.com/idoko/letterpress/db"
)
type Handler struct {
DB db.Database
Logger zerolog.Logger
ESClient *elasticsearch.Client
}
func New(database db.Database, esClient *elasticsearch.Client, logger zerolog.Logger) *Handler {
return &Handler{
DB: database,
ESClient: esClient,
Logger: logger,
}
}
func (h *Handler) Register(group *gin.RouterGroup) {
group.GET("/posts/:id", h.GetPost)
group.PATCH("/posts/:id", h.UpdatePost)
group.DELETE("/posts/:id", h.DeletePost)
group.GET("/posts", h.GetPosts)
group.POST("/posts", h.CreatePost)
group.GET("/search", h.SearchPosts)
}
Маршруты предоставляют интерфейс CRUD для наших сообщений, а также конечную точку поиска, позволяющую выполнять поиск по всем сообщениям с помощью Elasticsearch.
Создайте файл post.go в том же каталоге handlers и добавьте реализацию для обработчиков маршрута выше (для краткости мы рассмотрим создание и поиск сообщений, хотя вы можете увидеть полную реализацию для других обработчиков в репозитории GitLab проекта):
package handler
import (
"context"
"encoding/json"
"fmt"
"github.com/gin-gonic/gin"
"gitlab.com/idoko/letterpress/db"
"gitlab.com/idoko/letterpress/models"
"net/http"
"strconv"
"strings"
)
func (h *Handler) CreatePost(c *gin.Context) {
var post models.Post
if err := c.ShouldBindJSON(&post); err != nil {
h.Logger.Err(err).Msg("could not parse request body")
c.JSON(http.StatusBadRequest, gin.H{"error": fmt.Sprintf("invalid request body: %s", err.Error())})
return
}
err := h.DB.SavePost(&post)
if err != nil {
h.Logger.Err(err).Msg("could not save post")
c.JSON(http.StatusInternalServerError, gin.H{"error": fmt.Sprintf("could not save post: %s", err.Error())})
} else {
c.JSON(http.StatusCreated, gin.H{"post": post})
}
}
func (h *Handler) SearchPosts(c *gin.Context) {
var query string
if query, _ = c.GetQuery("q"); query == "" {
c.JSON(http.StatusBadRequest, gin.H{"error": "no search query present"})
return
}
body := fmt.Sprintf(
`{"query": {"multi_match": {"query": "%s", "fields": ["title", "body"]}}}`,
query)
res, err := h.ESClient.Search(
h.ESClient.Search.WithContext(context.Background()),
h.ESClient.Search.WithIndex("posts"),
h.ESClient.Search.WithBody(strings.NewReader(body)),
h.ESClient.Search.WithPretty(),
)
if err != nil {
h.Logger.Err(err).Msg("elasticsearch error")
c.JSON(http.StatusInternalServerError, gin.H{"error": err.Error()})
return
}
defer res.Body.Close()
if res.IsError() {
var e map[string]interface{}
if err := json.NewDecoder(res.Body).Decode(&e); err != nil {
h.Logger.Err(err).Msg("error parsing the response body")
} else {
h.Logger.Err(fmt.Errorf("[%s] %s: %s",
res.Status(),
e["error"].(map[string]interface{})["type"],
e["error"].(map[string]interface{})["reason"],
)).Msg("failed to search query")
}
c.JSON(http.StatusInternalServerError, gin.H{"error": e["error"].(map[string]interface{})["reason"]})
return
}
h.Logger.Info().Interface("res", res.Status())
var r map[string]interface{}
if err := json.NewDecoder(res.Body).Decode(&r); err != nil {
h.Logger.Err(err).Msg("elasticsearch error")
c.JSON(http.StatusInternalServerError, gin.H{"error": err.Error()})
return
}
c.JSON(http.StatusOK, gin.H{"data": r["hits"]})
}
CreatePost принимает тело запроса JSON и преобразует его в структуру Post с помощью gin ShouldBindJSON. Полученный объект затем сохраняется в базе данных с помощью функции SavePost, которую мы написали ранее.
SearchPosts более интересен. Он использует мультизапрос Elasticsearch для поиска сообщений. Таким образом, мы можем быстро найти сообщения, заголовок и / или тело которых содержат данный запрос. Мы также проверяем и регистрируем любую ошибку, которая может произойти, и преобразуем ответ в объект JSON, используя пакет json из стандартной библиотеки Go, и представляем его пользователю в качестве результатов поиска.
Синхронизировать базу данных с Elasticsearch с помощью Logstash
Logstash - это конвейер обработки данных, который принимает данные из разных источников ввода, обрабатывает их и отправляет в источник вывода.
Поскольку цель состоит в том, чтобы сделать данные в нашей базе данных доступными для поиска через Elasticsearch, мы настроим Logstash для использования базы данных PostgreSQL в качестве входных данных и Elasticsearch в качестве выходных.
В каталоге logstash/config создайте новый файл pipelines.yml для хранения всех необходимых нам конвейеров Logstash. В этом проекте это единый конвейер, который синхронизирует базу данных с Elasticsearch. Добавьте приведенный ниже код в новый pipelines.yml:
- pipeline.id: sync-posts-pipeline
path.config: "/usr/share/logstash/pipeline/sync-posts.conf"
Затем добавьте файл sync-posts.conf в папку logstash/pipeline с приведенным ниже кодом, чтобы настроить источники ввода и вывода:
input {
jdbc {
jdbc_connection_string => "jdbc:postgresql://${POSTGRES_HOST}:5432/${POSTGRES_DB}"
jdbc_user => "${POSTGRES_USER}"
jdbc_password => "${POSTGRES_PASSWORD}"
jdbc_driver_library => "/opt/logstash/vendor/jdbc/postgresql-42.2.18.jar"
jdbc_driver_class => "org.postgresql.Driver"
statement_filepath => "/usr/share/logstash/config/queries/sync-posts.sql"
use_column_value => true
tracking_column => "id"
tracking_column_type => "numeric"
schedule => "*/5 * * * * *"
}
}
filter {
mutate {
remove_field => ["@version", "@timestamp"]
}
}
output {
if [operation] == "delete" {
elasticsearch {
hosts => ["http://elasticsearch:9200"] # URL of the ES docker container - docker would resolve it for us.
action => "delete"
index => "posts"
document_id => "%{post_id}"
}
} else if [operation] in ["insert", "update"] {
elasticsearch {
hosts => ["http://elasticsearch:9200"]
action => "index"
index => "posts"
document_id => "%{post_id}"
}
}
}
Приведенный выше файл конфигурации состоит из трех блоков:
input- Устанавливает соединение с PostgreSQL с помощью подключаемого модуля JDBC и инструктирует Logstash выполнять указанный SQL-запросstatement_filepathкаждые пять секунд (настраивается значениемschedule). Хотя расписание имеет синтаксис, подобный cron, он также поддерживает субминутные интервалы и за кулисами использует rufus-scheduler. Вы можете узнать больше о синтаксисе и его настройке здесь. Мы также отслеживаем столбецid, чтобы Logstash извлекал только те операции, которые были зарегистрированы с момента последнего запуска конвейера.filter- Удаляет ненужные поля, в том числе добавленные Logstashoutput- Отвечает за перемещение входных данных в наш индекс Elasticsearch. Он использует условные выражения ES для удаления документа из индекса (если поле операции в базе данных является удалением) или создания / обновления документа (если операция является либо вставкой, либо обновлением).
Вы можете изучить документацию Logstash по плагинам ввода, фильтрации и вывода, чтобы увидеть еще больше возможностей в каждом блоке.
Затем создайте файл sync-posts.sql для размещения SQL-оператора нашего конвейера logstash/queries:
SELECT l.id,
l.operation,
l.post_id,
p.id,
p.title,
p.body
FROM post_logs l
LEFT JOIN posts p
ON p.id = l.post_id
WHERE l.id > :sql_last_value ORDER BY l.id;
Оператор SELECT использует SQL-соединения для извлечения соответствующей записи на основе post_id в таблице post_logs.
Настроив наш Logstash, теперь мы можем настроить его Dockerfile и добавить его в наши службы создания докеров. Создайте новый файл с именем Dockerfile в папке logstash и добавьте в него приведенный ниже код:
FROM docker.elastic.co/logstash/logstash:7.10.2
RUN /opt/logstash/bin/logstash-plugin install logstash-integration-jdbc
RUN mkdir /opt/logstash/vendor/jdbc
RUN curl -o /opt/logstash/vendor/jdbc/postgresql-42.2.18.jar https://jdbc.postgresql.org/download/postgresql-42.2.18.jar
ENTRYPOINT ["/usr/local/bin/docker-entrypoint"]
Приведенный выше файл Dockerfile берет официальный образ Logstash и устанавливает плагин JDBC, а также драйвер JDBC PostgreSQL, который нужен нашему конвейеру.
Обновите файл docker-compose.yml, добавив Logstash в список служб (т.е. перед блоком volumes) следующим образом:
logstash:
build:
context: logstash
env_file: .env
volumes:
- ./logstash/config/pipelines.yml:/usr/share/logstash/config/pipelines.yml
- ./logstash/pipelines/:/usr/share/logstash/pipeline/
- ./logstash/queries/:/usr/share/logstash/config/queries/
depends_on:
- postgres
- elasticsearch
Служба Logstash использует в качестве контекста каталог logstash, содержащий Dockerfile. Он также использует тома для монтирования файлов конфигурации из более ранних версий в соответствующие каталоги в контейнере Logstash.
Создание файла API
Теперь мы готовы представить наш проект как HTTP API. Мы будем делать это через проживание main.go в cmd/api. Откройте его в своем редакторе и добавьте к нему приведенный ниже код:
package main
import (
"github.com/elastic/go-elasticsearch/v7"
"os"
"strconv"
"github.com/gin-gonic/gin"
"github.com/rs/zerolog"
"gitlab.com/idoko/letterpress/db"
"gitlab.com/idoko/letterpress/handler"
)
func main() {
var dbPort int
var err error
logger := zerolog.New(os.Stderr).With().Timestamp().Logger()
port := os.Getenv("POSTGRES_PORT")
if dbPort, err = strconv.Atoi(port); err != nil {
logger.Err(err).Msg("failed to parse database port")
os.Exit(1)
}
dbConfig := db.Config{
Host: os.Getenv("POSTGRES_HOST"),
Port: dbPort,
Username: os.Getenv("POSTGRES_USER"),
Password: os.Getenv("POSTGRES_PASSWORD"),
DbName: os.Getenv("POSTGRES_DB"),
Logger: logger,
}
logger.Info().Interface("config", &dbConfig).Msg("config:")
dbInstance, err := db.Init(dbConfig)
if err != nil {
logger.Err(err).Msg("Connection failed")
os.Exit(1)
}
logger.Info().Msg("Database connection established")
esClient, err := elasticsearch.NewDefaultClient()
if err != nil {
logger.Err(err).Msg("Connection failed")
os.Exit(1)
}
h := handler.New(dbInstance, esClient, logger)
router := gin.Default()
rg := router.Group("/v1")
h.Register(rg)
router.Run(":8080")
}
Сначала мы настраиваем регистратор и передаем его всем компонентам приложения, чтобы обеспечить единообразие журналов ошибок и событий. Затем мы устанавливаем соединение с базой данных, используя значения из переменных среды (управляемых файлом .env). Мы также подключаемся к серверу Elasticsearch и обеспечиваем его доступность. После этого мы инициализируем наш обработчик маршрута и запускаем сервер API на порту 8080. Обратите внимание, что мы также используем группы маршрутов gin, чтобы поместить все наши маршруты в пространство имен v1, таким образом, мы также обеспечиваем своего рода «управление версиями» для нашего API.
Тестирование нашего поискового приложения
На этом этапе мы можем опробовать наше приложение для поиска. Перестройте и запустите службы создания докеров, запустив их в своем терминале docker-compose up --build. Команда также должна запустить сервер API на http://localhost:8080.
Откройте свой любимый инструмент тестирования API (например: Postman, cURL, HTTPie и т.д.) и создайте несколько сообщений. В приведенном ниже примере я использовал HTTPie для добавления пяти разных сообщений (взятых из блога Creative Commons) в нашу базу данных:
http POST localhost:8080/v1/posts title="Meet CC South Africa, Our Next Feature for CC Network Fridays" body="After introducing the CC Italy Chapter to you in July, the CC Netherlands Chapter in August, CC Bangladesh Chapter in September, CC Tanzania Chapter in October, and the CC India Chapter in November, the CC Mexico Chapter in December, and CC Argentina Chapter in January, we are now traveling to Africa"
http POST localhost:8080/v1/posts title="Still Life: Art That Brings Comfort in Uncertain Times" body="There is a quiet, familiar beauty found in still life, a type of art that depicts primarily inanimate objects, like animals, food, or flowers. These comforting images offer a sense of certainty and simplicity in uncertain and complex times. This could explain why over six million Instagram users have fallen in love with still life"
http POST localhost:8080/v1/posts title="Why Universal Access to Information Matters" body="The coronavirus outbreak not only sparked a health pandemic; it triggered an infodemic of misleading and fabricated news. As the virus spread, trolls and conspiracy theorists began pushing misinformation, and their deplorable tactics continue to this day."
Если вы предпочитаете использовать Postman, вот скриншот запроса Postman, аналогичный приведенным выше:
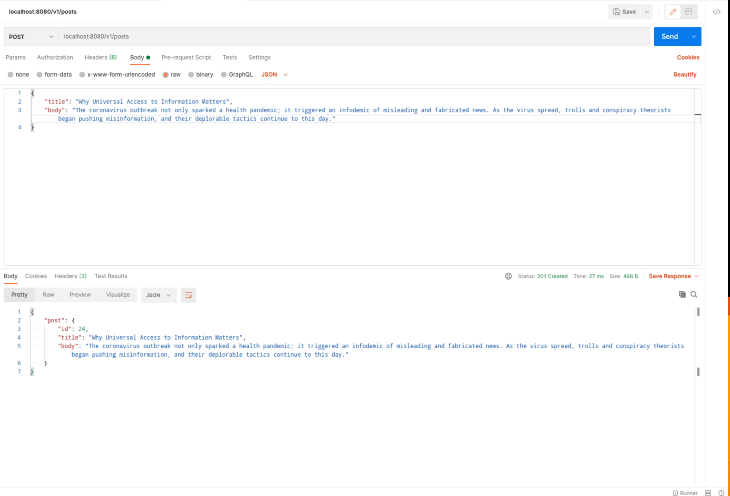
Вы также можете проверить журналы docker-compose (если вы не запускаете docker-compose в фоновом режиме), чтобы увидеть, как Logstash индексирует новые сообщения.
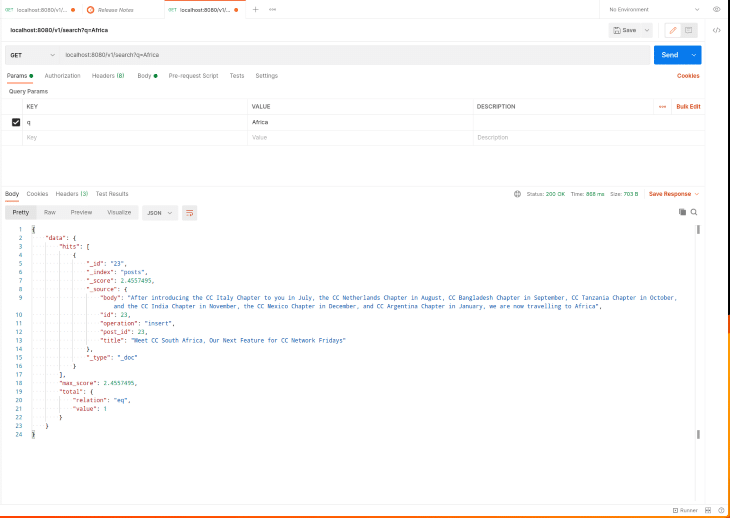
Чтобы проверить конечную точку поиска, отправьте HTTP-запрос GET на http://localhost: 8080/v1/search, как показано на снимке экрана ниже:
Визуализируйем Elasticsearch с Kibana
Хотя мы всегда можем использовать Elasticsearch API, чтобы увидеть, что происходит на нашем сервере Elasticsearch, или просмотреть документы, которые в настоящее время находятся в индексе, иногда полезно визуализировать и исследовать эту информацию на специальной панели инструментов. Кибана позволяет нам это делать. Обновите файл docker-compose, чтобы включить службу Kibana, добавив приведенный ниже код в раздел services (то есть после службы logstash, но перед разделом volumes):
kibana:
image: 'docker.elastic.co/kibana/kibana:7.10.2'
ports:
- "5601:5601"
hostname: kibana
depends_on:
- elasticsearch
Мы делаем Kibana зависимой от сервиса Elasticsearch, поскольку он будет бесполезен, если Elasticsearch не работает. Мы также предоставляем порт Kibana по умолчанию, чтобы мы могли получить доступ к панели управления с нашей машины разработки.
Запустите службы docker-compose, запустив docker-compose up (вам нужно будет сначала остановить docker-compose down, если они были запущены). Посетите http://localhost:5601, чтобы получить доступ к панели управления Kibana.
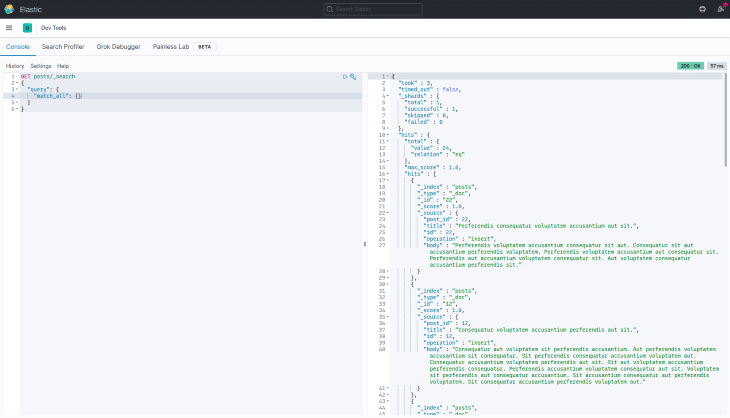
Вы также можете использовать инструменты разработчика, чтобы просмотреть все документы в индексе сообщений или попробовать различные поисковые запросы, прежде чем использовать их в своем приложении. На скриншоте ниже мы используем match_all для перечисления всех проиндексированных сообщений: