Использование поиска по сходству векторов в GraphQL

В этом посте показан простой пример схемы GraphQL с векторными вложениями и соответствующей мутацией и запросом.
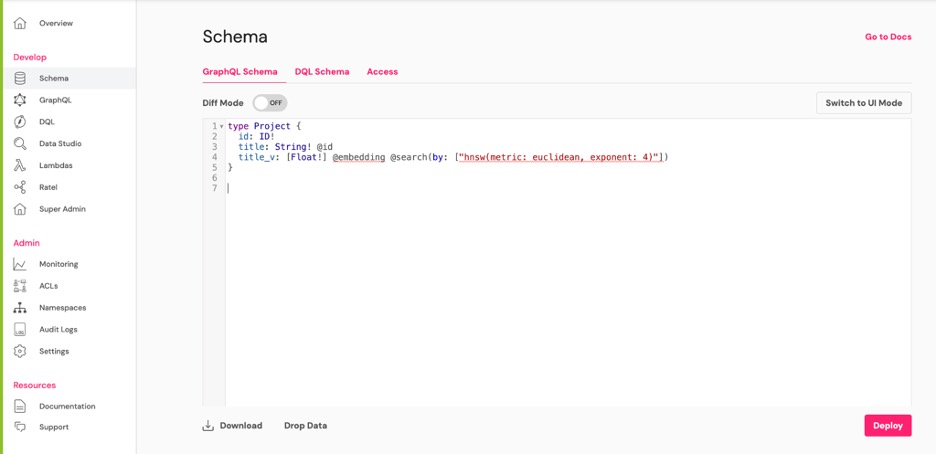
Разверните следующую схему GraphQL:
type Project {
id: ID!
title: String! @id
title_v: [Float!] @embedding @search(by: ["hnsw(metric: euclidean, exponent: 4)"])
}В этой схеме поле title_v представляет собой вложение, в котором алгоритм HNSW используется для создания индекса векторного поиска. Метрикой, используемой для вычисления расстояния между векторами (в этом примере), является евклидово расстояние. Была введена новая директива @embedding для обозначения одного или нескольких полей как векторных вложений. Директива @search была расширена для определения индекса HNSW на основе евклидова расстояния. Значение exponent используется для установки разумных значений по умолчанию для внутренних параметров настройки HNSW. Это целое число, представляющее приблизительное количество векторов, ожидаемых в индексе, в степени 10. Значение по умолчанию — «4» (10^4 вектора).
После успешного развертывания:
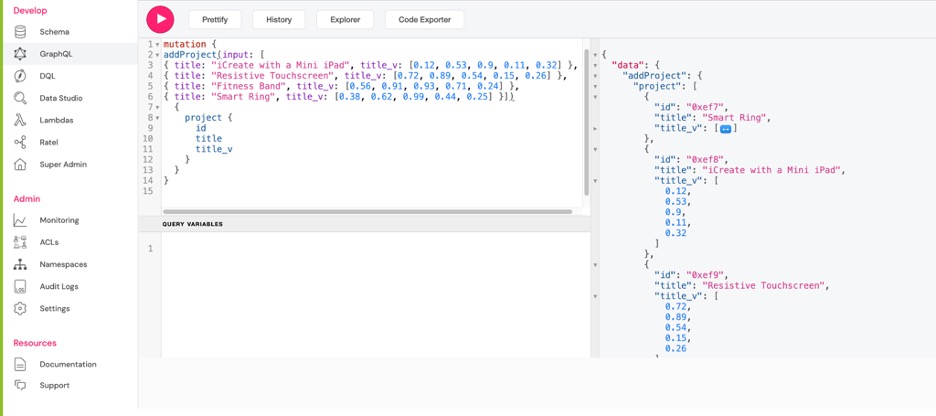
Давайте добавим некоторые данные с помощью автоматически сгенерированного addProject типа mutation.
mutation {
addProject(input: [
{ title: "iCreate with a Mini iPad", title_v: [0.12, 0.53, 0.9, 0.11, 0.32] },
{ title: "Resistive Touchscreen", title_v: [0.72, 0.89, 0.54, 0.15, 0.26] },
{ title: "Fitness Band", title_v: [0.56, 0.91, 0.93, 0.71, 0.24] },
{ title: "Smart Ring", title_v: [0.38, 0.62, 0.99, 0.44, 0.25] }])
{
project {
id
title
title_v
}
}
}
Автоматически сгенерированный querySimilarProjectByEmbedding запрос позволяет нам выполнить семантический поиск (он же поиск по сходству), используя векторный индекс, указанный в нашей схеме.
Выполните запрос:
query {
querySimilarProjectByEmbedding(by: title_v, topK: 3, vector: [0.1, 0.2, 0.3, 0.4, 0.5]) {
id
title
vector_distance
}
}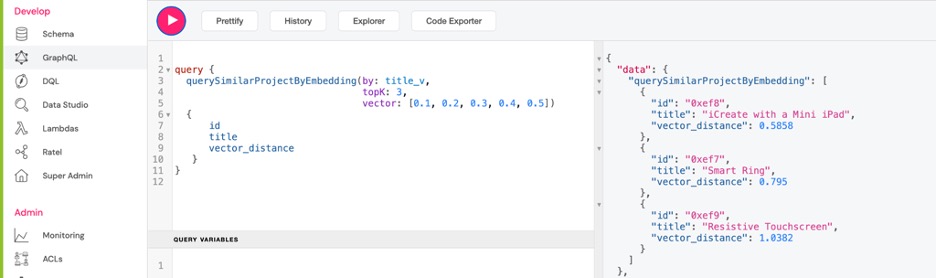
Результаты, полученные для querySimilarProjectByEmbedding функции, включают 3 ближайших проекта, упорядоченных по векторному расстоянию. vector_distance — это евклидово расстояние между title_v вектором внедрения и входным вектором, используемым в нашем запросе.
Примечание: вы можете опустить vector_distance предикат в запросе, результат все равно будет упорядочен по векторному расстоянию.
Используемая метрика расстояния указывается при создании индекса. В этом примере мы использовали:
title_v: [Float!] @embedding @search(by: ["hnsw(metric: euclidian, exponent: 4)"])Мы также можем запросить объекты, похожие на существующий объект, учитывая его id, используя функцию getSimilar<Object>ById.
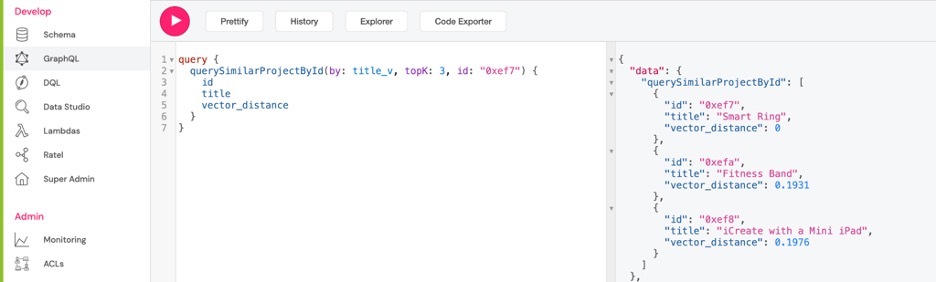
query {
querySimilarProjectById(by: title_v, topK: 3, id: "0xef7") {
id
title
vector_distance
}
}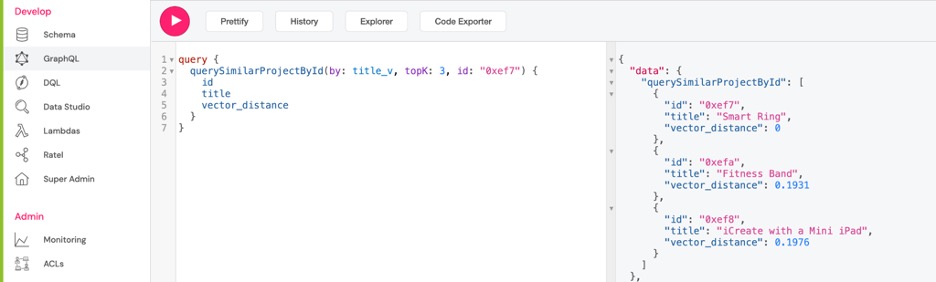
В приведенном ниже примере мы используем title для идентификации проекта, для которого мы хотим найти похожие проекты. В этом случае title поле представляет собой внешний идентификатор и аннотируется с помощью @id директивы в схеме. Вы можете назначить несколько полей внешними идентификаторами, используя директиву @id.
query {
querySimilarProjectById(by: title_v, topK: 3, title: "Smart Ring") {
title
vector_distance
}
}